
双 3090(NVLink)跑 Qwen3.6-27B,128K 上下文实测
-
@applejuice 投影层的名字 或者下载地址 能麻烦给一个吗
@laihzang619 我刚查了一下
原来不需要
应该是我之前的那个需要很多都是ai 自动设置所以我也忘了

-
@Leon-Y 3090的nvlink在哪里买?多少钱呀?
-
@Leon-Y prefill 呢?
-
@Leon-Y 3090的nvlink在哪里买?多少钱呀?
taobao, RMB2500
-
声明:这篇东西是叫AI 总结的
交作业。双 3090 跑 Qwen3.6-27B,测了上下文深度对速度的影响
GPU:RTX 3090 ×2,已上 NVLink(nvidia-smi topo -m 显示 NV4,4 条 link 各 14GB/s,约 56GB/s)
模型:Qwen3.6-27B-UD-Q4_K_XL(unsloth 动态量化) --- 下载错了 将就用
引擎:llama.cpp 自编译(CUDA),layer-split(默认模式)
KV cache:q8_0,上下文 153600
开了 MTP(--spec-type draft-mtp --spec-draft-n-max 3)、flash-attn测试方法: 每次冷 prefill,关掉 prompt cache,数字比较实在。脚本跑 /completion 读 timings。
prompt_n | prefill t/s | gen t/s | 总显存 | 功耗
782 | 708.8 | 59.2 | 34.7G | 440W
6155 | 1285.9 | 58.5 | 34.8G | 436W
24587 | 1249.5 | 54.6 | 34.8G | 441W
98315 | 835.4 | 47.4 | 34.8G | 441W
135017 | 694.2 | 43.2 | 34.8G | 444W解码 59 → 43 t/s,从 800 一路到 135K 上下文只掉 27%,曲线相当平,不像单卡过了 64K 就断崖
显存全程稳定 34.7G(KV cache 启动时按满 context 预分配),48G 总显存还剩富裕,上下文还能再往上拉
prefill 在中段(6K~24K)能冲到 1250+ t/s,深上下文回落到 700 左右
双卡 layer-split,两张卡轮流跑,速度约等于单卡——双卡的收益主要是"显存容量",能塞下深上下文
功耗双卡合计稳定 ~440W一开始先用vllm 跑两张卡 结果只有7t/s, 所以先用上llama 然后在看能不能用上NVLINK
现在还叫claude 解决vllm 然后测试@applejuice 我和你试了几乎完全一样的设置Qwen3.6-27B-UD-Q4_K_XL,不过是单卡4090 24GB,所以上下文只能装120000。MTP开了以后大概能85~90tps,不开大概45tps,vram用了23GB
-
双卡3090 vLLM跑Qwen3.6-27B,强烈建议关注: https://github.com/noonghunna/club-3090 。
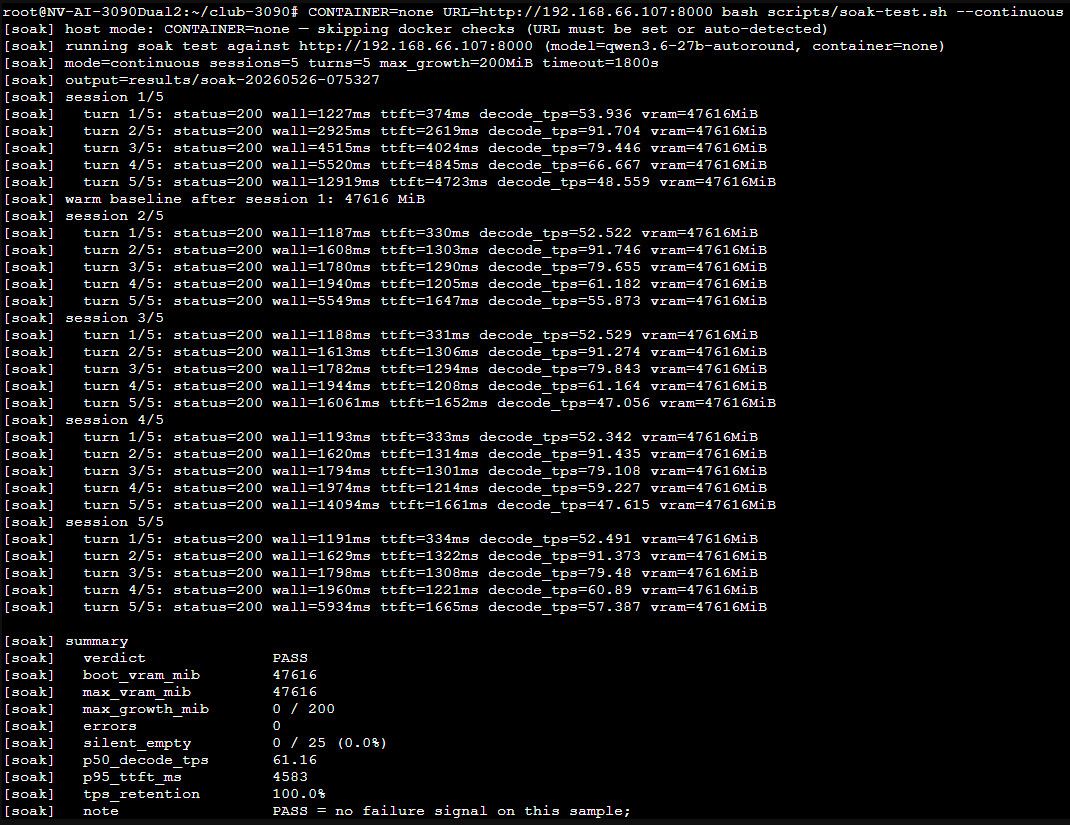
我自己的环境: 双卡3090 nvlink,模型Qwen3.6-27B-autoround-int4。 kv cache fp8_e5m2量化, 上下文长度 262144 。采用 dual-mtp 的vllm运行参数和测试脚本(soak-test.sh), p50_decode_tps:61.34;p95_ttft_ms:4864 。
官方给的测试,应该能到接近70tps,我的还有优化空间,但是能用了就没折腾,参考DUAL_CARD.md。
num_speculative_tokens我测了2,3,4,5。效果上3最好。启动脚本:
root@NV-AI-3090Dual2:~# cat vllm.qwen3.6-27b.sh #!/bin/bash source /root/.bashrc source /root/venv/bin/activate # vLLM 启动脚本 — Qwen3.6-27B-AutoRound-INT4 # 用法: bash start-vllm-qwen3.6.sh [TP] [PP] # TP: tensor-parallel size,默认 2 # PP: pipeline-parallel size,默认 1 set -e # ========== 参数 ========== TP="${1:-${TP:-2}}" PP="${2:-${PP:-1}}" MODEL_PATH="/root/models/qwen3.6-27b-autoround-int4" PORT="${PORT:-8000}" HOST="${HOST:-0.0.0.0}" MAX_MODEL_LEN="${MAX_MODEL_LEN:-262144}" GPU_MEM_UTIL="${GPU_MEMORY_UTILIZATION:-0.92}" KV_CACHE_DTYPE="${KV_CACHE_DTYPE:-fp8_e5m2}" TEMP="${TEMP:-${TEMPERATURE:-0.6}}" TOP_P="${TOP_P:-0.95}" TOP_K="${TOP_K:-20}" MIN_P="${MIN_P:-0.0}" REPEAT_PENALTY="${REPEAT_PENALTY:-1.0}" # speculative decoding SPECULATIVE_CONFIG='{"method":"mtp","num_speculative_tokens":3}' # 推理模板参数(关闭 thinking) CHAT_TEMPLATE_KWARGS='{"enable_thinking": false}' # ========== 环境变量 ========== export NVIDIA_VISIBLE_DEVICES="${NVIDIA_VISIBLE_DEVICES:-all}" export HUGGING_FACE_HUB_TOKEN="${HF_TOKEN:-}" export VLLM_WORKER_MULTIPROC_METHOD=spawn export NCCL_CUMEM_ENABLE=0 export NCCL_P2P_DISABLE=0 export VLLM_NO_USAGE_STATS=1 export VLLM_USE_FLASHINFER_SAMPLER=1 export OMP_NUM_THREADS=1 export PYTORCH_CUDA_ALLOC_CONF="expandable_segments:True,max_split_size_mb:512" # NVLink 检测(自行补充 detect_nvlink.sh 逻辑,或删掉这两行) # source /etc/club3090/detect_nvlink.sh # _NVLINK_ENABLED=0 # 手动设置:0=无NVLink, 1=NvLink开启 # ========== 构建命令 ========== ARGS=( --model "$MODEL_PATH" --served-model-name qwen3.6-27b-autoround --quantization auto_round --dtype float16 --tensor-parallel-size "$TP" --pipeline-parallel-size "$PP" --max-model-len "$MAX_MODEL_LEN" --gpu-memory-utilization "$GPU_MEM_UTIL" --max-num-seqs 2 --max-num-batched-tokens 8192 --kv-cache-dtype "$KV_CACHE_DTYPE" --trust-remote-code # --chat-template "${CHAT_TEMPLATE}" # 没有自定义模板文件则删除此行 --reasoning-parser qwen3 --default-chat-template-kwargs "$CHAT_TEMPLATE_KWARGS" --enable-auto-tool-choice --tool-call-parser qwen3_coder --enable-prefix-caching --enable-chunked-prefill --disable-custom-all-reduce --speculative-config "$SPECULATIVE_CONFIG" --override-generation-config "{\"temperature\":${TEMP},\"top_p\":${TOP_P},\"top_k\":${TOP_K},\"min_p\":${MIN_P},\"repetition_penalty\":${REPEAT_PENALTY}}" --host "$HOST" --port "$PORT" ) echo "==========================================" echo "启动 vLLM | TP=$TP PP=$PP | $MODEL_PATH" echo "==========================================" echo "命令: vllm serve ${ARGS[*]}" echo "" exec vllm serve "${ARGS[@]}" deactivate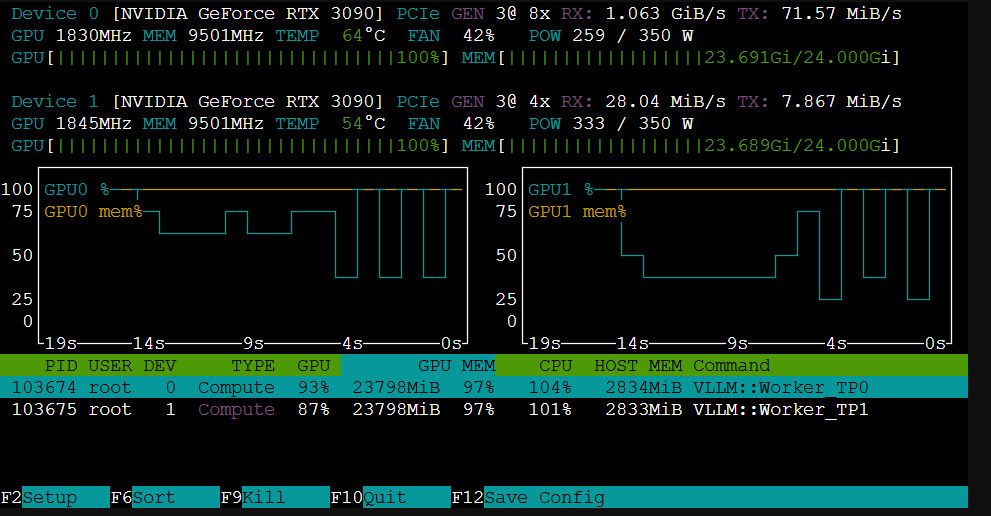
@applejuice 我觉得结果很不错,NVlink通信损失小,TP是算力叠加,所以2x3090在这种情况下tps能接近或者等同单卡4090算力,而且上下文能更多
@Leon-Y 为什么你的数据比 @applejuice 的好很多?
-
@applejuice 我觉得结果很不错,NVlink通信损失小,TP是算力叠加,所以2x3090在这种情况下tps能接近或者等同单卡4090算力,而且上下文能更多
@Leon-Y 为什么你的数据比 @applejuice 的好很多?
@topgun2000 模型不一样
如果用那个模型 开mtp 结果差不多 -
@topgun2000 模型不一样
如果用那个模型 开mtp 结果差不多@applejuice 了解了,他用的是int4的文字模型,所以TP更快一些
-
声明:这篇东西是叫AI 总结的
交作业。双 3090 跑 Qwen3.6-27B,测了上下文深度对速度的影响
GPU:RTX 3090 ×2,已上 NVLink(nvidia-smi topo -m 显示 NV4,4 条 link 各 14GB/s,约 56GB/s)
模型:Qwen3.6-27B-UD-Q4_K_XL(unsloth 动态量化) --- 下载错了 将就用
引擎:llama.cpp 自编译(CUDA),layer-split(默认模式)
KV cache:q8_0,上下文 153600
开了 MTP(--spec-type draft-mtp --spec-draft-n-max 3)、flash-attn测试方法: 每次冷 prefill,关掉 prompt cache,数字比较实在。脚本跑 /completion 读 timings。
prompt_n | prefill t/s | gen t/s | 总显存 | 功耗
782 | 708.8 | 59.2 | 34.7G | 440W
6155 | 1285.9 | 58.5 | 34.8G | 436W
24587 | 1249.5 | 54.6 | 34.8G | 441W
98315 | 835.4 | 47.4 | 34.8G | 441W
135017 | 694.2 | 43.2 | 34.8G | 444W解码 59 → 43 t/s,从 800 一路到 135K 上下文只掉 27%,曲线相当平,不像单卡过了 64K 就断崖
显存全程稳定 34.7G(KV cache 启动时按满 context 预分配),48G 总显存还剩富裕,上下文还能再往上拉
prefill 在中段(6K~24K)能冲到 1250+ t/s,深上下文回落到 700 左右
双卡 layer-split,两张卡轮流跑,速度约等于单卡——双卡的收益主要是"显存容量",能塞下深上下文
功耗双卡合计稳定 ~440W一开始先用vllm 跑两张卡 结果只有7t/s, 所以先用上llama 然后在看能不能用上NVLINK
现在还叫claude 解决vllm 然后测试@applejuice 兄弟 哪个主板可以插双3090啊 这个卡台厚了 论坛洋垃圾的主板行吗
-
@applejuice 兄弟 哪个主板可以插双3090啊 这个卡台厚了 论坛洋垃圾的主板行吗
@applejuice 兄弟 哪个主板可以插双3090啊 这个卡台厚了 论坛洋垃圾的主板行吗
我的是涡轮卡
一张卡占 2 条 正常间距的pcie16我用的是x10-x99-8d
只有双路的pcie 16间距 才能插nvlink -
@applejuice 兄弟 哪个主板可以插双3090啊 这个卡台厚了 论坛洋垃圾的主板行吗
-
@applejuice 架子65,延长线贵延长线要¥69,30厘米的
nvlink是卖显卡那个二手店套餐送的

