
淺談 llama.cpp 配合 RTX Pro 4500 簡單測試 Qwen 3.6 27B, MoQ, AutoRound以及普通UD Q5KM
-
跨平臺llama-benchy的數據
tokenizer沿用vllm的kaitchup/Qwen3.6-27B-autoround-nvfp4-linearattn-mtp-BF16
測試咒語
~/llama-benchy/.venv/bin/llama-benchy --base-url http://127.0.0.1:8081/v1 --model Qwen3.6-27B-MTP-MoQ --served-model-name /models/Jianqiao1/Qwen3.6-27B-MTP-MoQ-GGUF/Qwen3.6-27B-MTP-MoQ-4.95.gguf --tokenizer ~/vllm/models/kaitchup/Qwen3.6-27B-autoround-nvfp4-linearattn-mtp-BF16 --pp 1024 --tg 64 --depth 98304 196608 --runs 1 --latency-mode generation --concurrency 1 --skip-coherence --post-run-cmd 'nvidia-smi --query-gpu=timestamp,memory.used,memory.total --format=csv,noheader,nounits' --save-result llama-benchy-moq-longctx.json --format json模型 測試階段 上下文長度 Avg latency TTFR Prefill tok/s Generation tok/s Peak tok/s MoQ 4.95 half 98304 107.74 ms 101.23s 982.37 52.56 56 MoQ 4.95 full 196608 107.61 ms 312.73s 632.23 40.22 42 Unsloth Q5_K_M half 98304 156.26 ms 107.96s 921.55 50.48 53 Unsloth Q5_K_M full 196608 148.79 ms 323.88s 610.53 33.82 41 AutoRound Q5_K_M half 98304 117.32 ms 107.76s 922.93 44.01 46 AutoRound Q5_K_M full 196608 114.29 ms 323.57s 611.04 38.01 41 不得不説這個比上篇的vllm差很多啊, 100K上下文vLLM也有60 tks, 是我的設定有問題還是本來就這麽差
MoQ的各個速度都很高, 而且在長上下文的表現還不錯, 可能是因爲Bit per weight相對更小的關係
-
MTP測試
模型 測試階段 Generated draft tokens Accepted draft tokens Acceptance Mean acceptance length Acceptance rate per position (first 3) MoQ 4.95 half 56 44 78.571% 3.32 (0.895, 0.842, 0.579)MoQ 4.95 full 51 45 88.235% 3.65 (0.941, 0.882, 0.824)Unsloth Q5_K_M half 53 45 84.906% 3.50 (0.944, 0.889, 0.667)Unsloth Q5_K_M full 57 43 75.439% 3.15 (0.900, 0.650, 0.600)AutoRound Q5_K_M half 61 42 68.852% 3.00 (0.857, 0.667, 0.476)AutoRound Q5_K_M full 51 45 88.235% 3.65 (1.000, 0.882, 0.765) -
KLD, PPL測試
llama.cpp本身支持這兩個數據, 前者可以當作跟基準模型的偏差值, 後者可以當成困惑度, 視作模型對於下個要預測的Token精準度就好 (越低代表模型預測能力越好)
因爲VRAM大小沒辦法測試原生BF16/Q8, 所以單純以UD Unsloth Q5KM作爲基準模型
上下文512, 32分塊, 測試文本沿用vLLM的在Readme提及的預設長篇Sherlock小説
模型 PPL Unsloth Q5_K_M 1.2398 +/- 0.01457 MoQ 4.95 1.2796 +/- 0.01553 AutoRound Q5_K_M 1.3137 +/- 0.01656
模型 基準 Mean KLD 99.9% KLD Same top-p MoQ 4.95 Unsloth Q5_K_M 0.085771 5.087046 95.870% AutoRound Q5_K_M Unsloth Q5_K_M 0.138661 7.634626 94.645% -
Bit Per Weight探討
Model Local GGUF size Approx file bpw Note Unsloth Q5_K_M 19,834,053,760 bytes 5.81 基準Q5_K_M GGUF AutoRound Q5_K_M 19,535,700,032 bytes 5.72 減少約1.5%, 基本忽略不計 MoQ 4.95 16,540,767,424 bytes 4.84 減少約16.6% 儘管MoQ的BPW比Autoround Q5KM還低, 但是KLD其實也沒差太遠, PPL相差則可接受範圍, 權重在顯存也比Autoround少大約2GB, 預留更多KV Cache空間, 應該也能當成主力使用
不過我應該要用Q4_K_M來比較才對, 畢竟他們的BPW比較類似, oh well it happened -
MoQ技術探討
其實MoQ在這裏并不是第一次出現, @stxpnet stxp大大有在這裏發過帖子探討模型輸出的代碼素質, 各位可以看完再繼續
MoQ (Mixture of Quantization, 混合量化)最好被理解為一種 量化配方 (recipe), 而不是單一的量化格式, 理論上他也能用在vLLM身上
-
訓練後量化 (Post-training quantization): 從 BF16/FP16 權重開始, 訓練完成後壓縮權重
-
混合精度量化 (Mixed precision quantization): 不同的張量 (tensor) 會採用不同的格式, 不是像普通的K Quant那樣, 強迫整個模型使用單一格式
-
顯著權重選擇: 比較重要的權重會保持在較高的精度, 較不敏感的張量則會被壓低精度, 這個就十分類似Autoround
-
混合量化類型: MoQ支持混合多種格式, 例如 Q5_K, Q4_K, IQ4_XS, BF16或誇張點, FP32
-
校準數據: 通常會由一個校準數據集 (calibration set) 或重要性矩陣 (importance-matrix) 風格的訊號來決定哪些權重可以承受較低的精度, 相對來説代表這個更像坊間為Qwen 3.6 27B加入Opus Reasoning訓練集
-
部分層會受特別關照: 正規化層 (norms), 嵌入層 (embeddings), 輸出頭 (output heads), 循環網路/狀態空間模型組件 (recurrent/SSM pieces) 或與 MTP 相關的網絡會保留較高精度, 因為這些地方的微小誤差對預測結果 (logits) 會比單純壓縮網絡内部造成較大的影響
-
運行時解壓縮 (Runtime Dequantization): llama.cpp在推論期間進行解壓, 理論上就會按照原先定好的量化類型進行解壓 (第四點)
資料來源: https://x.com/bnjmn_marie/status/2060051274545111177?s=20
簡單一個類比就是:
MoQ 就像是在有嚴格重量限制的情況下打包行李出門旅行, 正常人不會把所有物品都換成最輕的版本, 會先把易碎或至關重要的物品放在合適的硬殼箱裡, 之後較耐用的物品用較輕的袋子裝, 而在損壞較大也無大礙的地方就隨便裝
普通的 Q5_K_M 則是規定所有東西都必須使用同一種行李箱
MoQ 則是每件物品都在能提供足夠保護的前提下, 使用最便宜/最輕的容器這個模式基本上追隨Autoround的思路
-
-
,
 T terry 固定了此主题
T terry 固定了此主题
-
我看到越来越多无审查的NVFP4。。。。陆陆续续下载了,单单看 t/s 的增长, 很爽
-
,系统 取消固定了此主题
-
,T terry 固定了此主题
-
,系统 取消固定了此主题
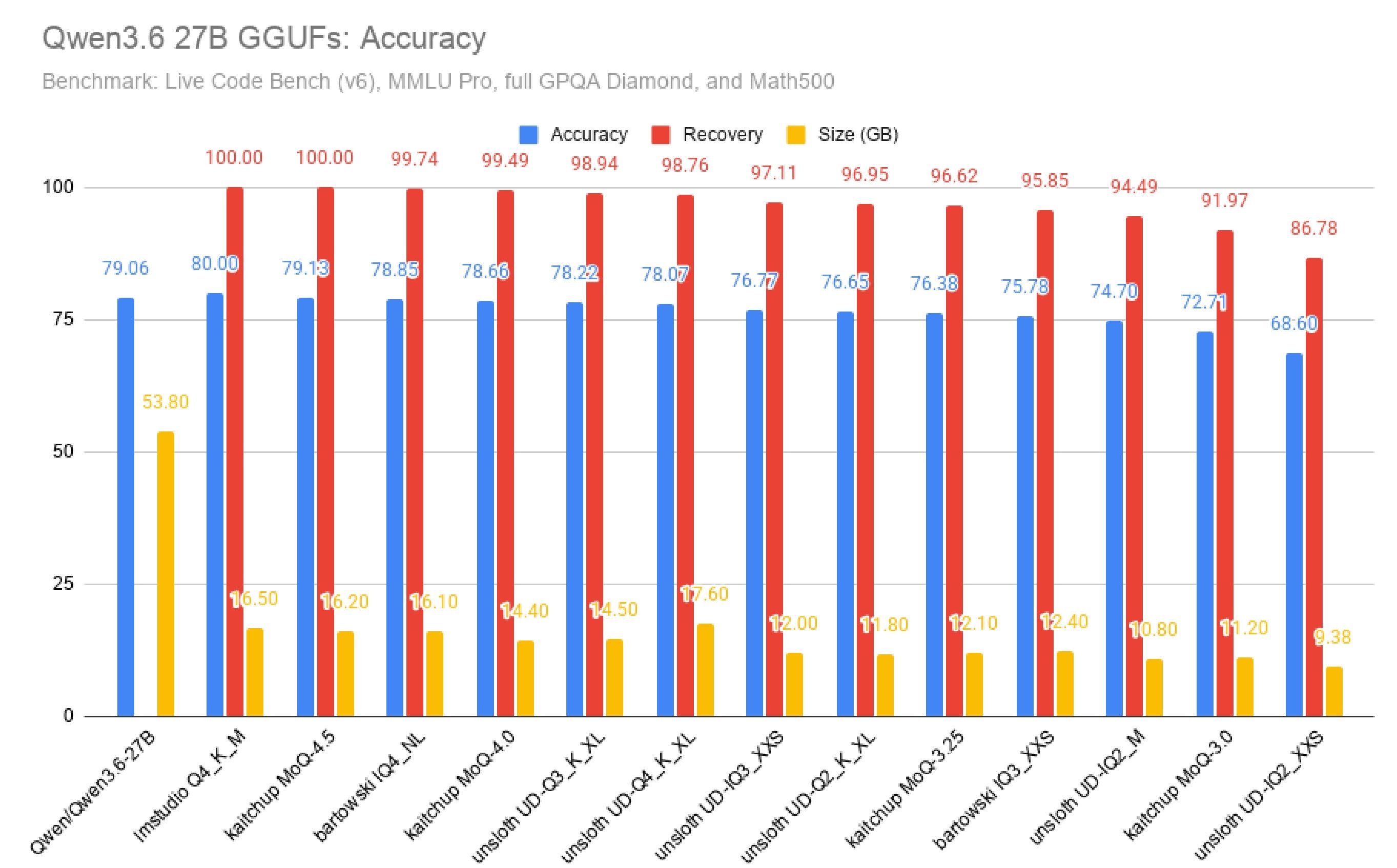 只有这个分辨率,lmstudio我没找到,我的显卡也只能跑 4.5的moq. 晚点我详细试试
只有这个分辨率,lmstudio我没找到,我的显卡也只能跑 4.5的moq. 晚点我详细试试