
【实测】X99 PCIe 4.0 是真是假?用实际带宽测试拆穿华强北黑魔法
-
起因
最近逛论坛看到有大佬论证 X99 支持 PCIe 4.0 ,说是华强北的板厂在 BIOS 里加了 PCIe 4.0 的选项,实际也能协商到 4.0。看着挺诱人的——毕竟 X99 板子便宜,Xeon E5 v3/v4 白菜价,要是真能跑 4.0,配上两张 RX 7900 XTX 跑 LLM 的 TP(张量并行),跨卡通信带宽直接翻倍,美滋滋。
(原始贴现在因为论坛的搜索改版,已经找不回来了,大概意思就是该大佬通过几个命令,都能读出来协商的是16GB/s的带宽,然后推定x99支持pcie4.0)但冷静下来一想:X99 的 PCIe 控制器是集成在 CPU 里的,Haswell-E/Broadwell-E 的 IMC 和 PCIe root complex 都是 Intel 定死的规格,只到 PCIe 3.0。华强北再牛逼,能改 BIOS 设置,总不能重做 CPU 的硅片吧?
于是决定不靠嘴炮,上机实测。
测试平台
项目 规格 主板 6卡直插矿板 X99-6Plus CPU Intel Xeon E5-2682 v4(Broadwell-EP) 被测 GPU RTX 3080 Ti(GA102,支持 PCIe 4.0) OS Ubuntu Linux 测试工具 nvidia-smi / lspci / gpu-pcie-bench 本来是打算测两张 7900 XTX 的,但它们在跑推理工作中,就不打扰了。拿 3080 Ti 测,结果是一样的——瓶颈在 CPU/主板侧,不在 GPU 侧。
第一步:看协商状态
nvidia-smi --query-gpu=pcie.link.gen.current,pcie.link.gen.max,pcie.link.width.current --format=csv结果:
1, 3, 16current = 1:空闲降到了 PCIe 1.0,正常省电行为max = 3:最大只支持 PCIe 3.0
width = 16:通道数正常
关键就是
max = 3——如果真解锁了 4.0,这里应该显示 4。再来看看 lspci:
sudo lspci -s 02:00.0 -vvv | grep -E "LnkCap|LnkSta"LnkCap: Speed 8GT/s, Width x16 LnkSta: Speed 2.5GT/s (downgraded), Width x16- LnkCap(能力):
Speed 8GT/s= PCIe 3.0(Gen3 = 8GT/s,Gen4 = 16GT/s) - LnkSta(当前):
Speed 2.5GT/s= 空闲降到了 Gen1
(这里其实存在一个问题,之前看到贴子的时候,汇报是Speed 16GT/s,可能是指那2张7900xtx吧)
到这里已经很明显了:硬件能力上就不支持 Gen4。
第二步:实际跑带宽
协商是一回事,实际能不能跑出那个速度是另一回事。上
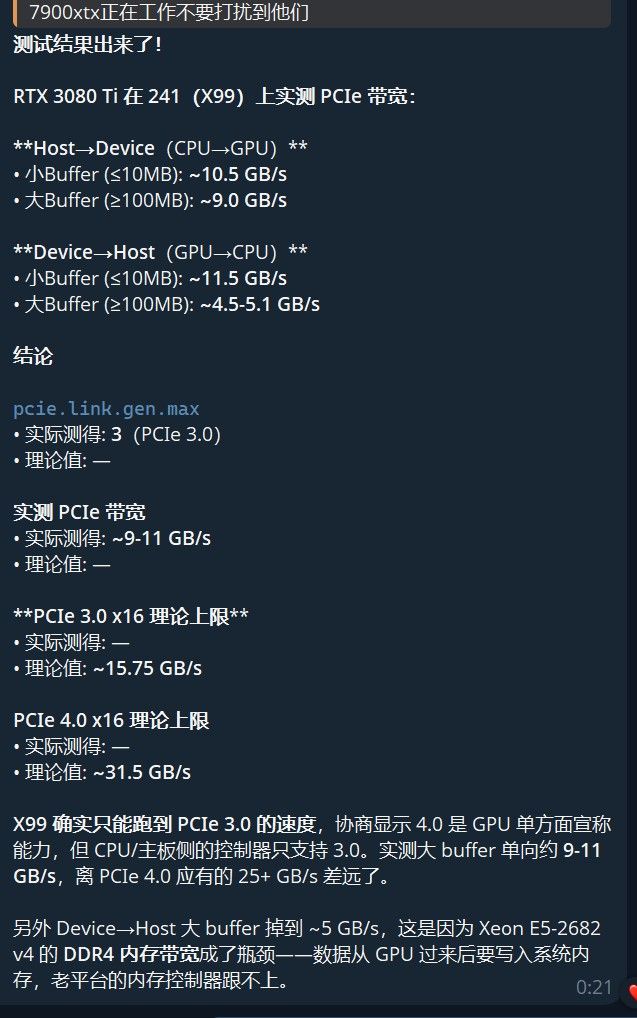
gpu-pcie-bench(https://github.com/tpoechtrager/gpu-pcie-bench)做实际 PCIe 吞吐测试。# 安装 git clone --depth=1 https://github.com/tpoechtrager/gpu-pcie-bench.git cd gpu-pcie-bench && make # 跑测试 ./bin/x86_64/gpu-pcie-bench --device 0 --rounds 50 --direction both --unit gb实测结果:
Buffer 大小 Host→Device(CPU→GPU) Device→Host(GPU→CPU) 512 KB 9.30 GB/s 9.73 GB/s 1 MB 10.03 GB/s 10.54 GB/s 10 MB 11.33 GB/s 11.47 GB/s 100 MB 9.05 GB/s 4.36 GB/s 1 GB 8.99 GB/s 5.13 GB/s 2 GB 8.98 GB/s 5.14 GB/s 对比理论值:
标准 理论单向带宽 实测典型值 PCIe 3.0 x16 ~15.75 GB/s ~9-11.5 GB/s  符合预期
符合预期PCIe 4.0 x16 ~31.5 GB/s  差得远
差得远PCIe 3.0 x8 ~7.88 GB/s 大 buffer D2H 接近这个值 注意大 buffer 的 Device→Host 掉到 ~5 GB/s,这个是因为 Xeon E5-2682 v4 的 DDR4 内存带宽成了瓶颈——数据从 GPU 读回来要写进系统内存,老平台的内存控制器跟不上。这进一步说明:哪怕 GPU 再快,整个平台的 PCIe 子系统的天花板就在那里。
结论:所谓的"魔改 PCIe 4.0"到底是什么?
拆穿来看,无非是三件事:
- GPU 端是真支持 Gen4——RTX 3080 Ti 和 RX 7900 XTX 自身都支持 PCIe 4.0,会向上报 Capability
- 寨板焊了 Gen4 的 retimer/switch 芯片——为了兼容性,物理层芯片用支持 4.0 的
- BIOS 菜单直接从 GPU 的 Capability 里读选项显示出来——但实际 CPU-PCH 的链路仍然是 Gen3 握手
一句话总结:
插槽是 4.0 的皮,链路是 3.0 的芯。
PCIe 协商是双向的——一方说 4.0 没用,双方都支持才是真 4.0。CPU 那端的 root complex 不支持,插宇宙最快的显卡也没用。
对 X99 双卡跑 LLM 的启示
如果你像我一样,想在 X99 上插两张卡跑 TP(张量并行),除了确认是 3.0 不是 4.0 之外,还要注意:
- X99 的 CPU 只有 40 条 PCIe 通道
- 两张 GPU 如果都插 x16 槽,实际可能是 x16 + x8(CPU 的 PCIe lane 分配限制)
- 如果第二张卡是 x8,那 PCIe 3.0 x8 ≈ ~5-7 GB/s,TP 模式的通信会成为明显瓶颈
- PP(流水线并行)比 TP 友好一些,但依然有影响
当然,单卡推理完全没所谓——模型加载到显存后,PCIe 只做偶尔的数据传输,瓶颈在算力和显存带宽上。
附:Windows 上怎么测?
如果是在 Windows 下,推荐:
工具 用法 GPU-Z 打开 → 点问号旁边的「Render Test」按钮 → 看 Bus Interface 那行从 @ x16 1.1升到@ x16 3.0就是 Gen3,升到@ x16 4.0才是真 Gen4AIDA64 Tools → GPGPU Benchmark,看 Host→Device / Device→Host 的带宽 nvidia-smi Windows 版一样可以用: nvidia-smi --query-gpu=pcie.link.gen.current,pcie.link.gen.max,pcie.link.width.current --format=csv快速排查命令(Linux)
# 1. 看 GPU 协商到的最大版本 nvidia-smi --query-gpu=pcie.link.gen.max --format=csv # 2. 看 PCIe 设备能力(Gen3=8GT/s, Gen4=16GT/s) sudo lspci -s <GPU_BUS> -vvv | grep LnkCap # 3. 跑实际带宽(最靠谱) gpu-pcie-bench --device 0 --direction both --unit gb数据说话,别信 BIOS 菜单里的花活。
-
,
 T Tony Wang 固定了此主题
T Tony Wang 固定了此主题
-
,T Tony Wang 取消固定了此主题
-
,T Tony Wang 固定了此主题
-
赞。这对很多采购用户是非常重要的。
-
应该没那做测试的 7900XTX 破。我那台就是 3.0的插槽。现在又扔去吃灰了。坐等7900XTX 涨价 。
-
,系统 取消固定了此主题
-
起因
最近逛论坛看到有大佬论证 X99 支持 PCIe 4.0 ,说是华强北的板厂在 BIOS 里加了 PCIe 4.0 的选项,实际也能协商到 4.0。看着挺诱人的——毕竟 X99 板子便宜,Xeon E5 v3/v4 白菜价,要是真能跑 4.0,配上两张 RX 7900 XTX 跑 LLM 的 TP(张量并行),跨卡通信带宽直接翻倍,美滋滋。
(原始贴现在因为论坛的搜索改版,已经找不回来了,大概意思就是该大佬通过几个命令,都能读出来协商的是16GB/s的带宽,然后推定x99支持pcie4.0)但冷静下来一想:X99 的 PCIe 控制器是集成在 CPU 里的,Haswell-E/Broadwell-E 的 IMC 和 PCIe root complex 都是 Intel 定死的规格,只到 PCIe 3.0。华强北再牛逼,能改 BIOS 设置,总不能重做 CPU 的硅片吧?
于是决定不靠嘴炮,上机实测。
测试平台
项目 规格 主板 6卡直插矿板 X99-6Plus CPU Intel Xeon E5-2682 v4(Broadwell-EP) 被测 GPU RTX 3080 Ti(GA102,支持 PCIe 4.0) OS Ubuntu Linux 测试工具 nvidia-smi / lspci / gpu-pcie-bench 本来是打算测两张 7900 XTX 的,但它们在跑推理工作中,就不打扰了。拿 3080 Ti 测,结果是一样的——瓶颈在 CPU/主板侧,不在 GPU 侧。
第一步:看协商状态
nvidia-smi --query-gpu=pcie.link.gen.current,pcie.link.gen.max,pcie.link.width.current --format=csv结果:
1, 3, 16current = 1:空闲降到了 PCIe 1.0,正常省电行为max = 3:最大只支持 PCIe 3.0width = 16:通道数正常
关键就是
max = 3——如果真解锁了 4.0,这里应该显示 4。再来看看 lspci:
sudo lspci -s 02:00.0 -vvv | grep -E "LnkCap|LnkSta"LnkCap: Speed 8GT/s, Width x16 LnkSta: Speed 2.5GT/s (downgraded), Width x16- LnkCap(能力):
Speed 8GT/s= PCIe 3.0(Gen3 = 8GT/s,Gen4 = 16GT/s) - LnkSta(当前):
Speed 2.5GT/s= 空闲降到了 Gen1
(这里其实存在一个问题,之前看到贴子的时候,汇报是Speed 16GT/s,可能是指那2张7900xtx吧)
到这里已经很明显了:硬件能力上就不支持 Gen4。
第二步:实际跑带宽
协商是一回事,实际能不能跑出那个速度是另一回事。上
gpu-pcie-bench(https://github.com/tpoechtrager/gpu-pcie-bench)做实际 PCIe 吞吐测试。# 安装 git clone --depth=1 https://github.com/tpoechtrager/gpu-pcie-bench.git cd gpu-pcie-bench && make # 跑测试 ./bin/x86_64/gpu-pcie-bench --device 0 --rounds 50 --direction both --unit gb实测结果:
Buffer 大小 Host→Device(CPU→GPU) Device→Host(GPU→CPU) 512 KB 9.30 GB/s 9.73 GB/s 1 MB 10.03 GB/s 10.54 GB/s 10 MB 11.33 GB/s 11.47 GB/s 100 MB 9.05 GB/s 4.36 GB/s 1 GB 8.99 GB/s 5.13 GB/s 2 GB 8.98 GB/s 5.14 GB/s 对比理论值:
标准 理论单向带宽 实测典型值 PCIe 3.0 x16 ~15.75 GB/s ~9-11.5 GB/s 符合预期PCIe 4.0 x16 ~31.5 GB/s 差得远PCIe 3.0 x8 ~7.88 GB/s 大 buffer D2H 接近这个值 注意大 buffer 的 Device→Host 掉到 ~5 GB/s,这个是因为 Xeon E5-2682 v4 的 DDR4 内存带宽成了瓶颈——数据从 GPU 读回来要写进系统内存,老平台的内存控制器跟不上。这进一步说明:哪怕 GPU 再快,整个平台的 PCIe 子系统的天花板就在那里。
结论:所谓的"魔改 PCIe 4.0"到底是什么?
拆穿来看,无非是三件事:
- GPU 端是真支持 Gen4——RTX 3080 Ti 和 RX 7900 XTX 自身都支持 PCIe 4.0,会向上报 Capability
- 寨板焊了 Gen4 的 retimer/switch 芯片——为了兼容性,物理层芯片用支持 4.0 的
- BIOS 菜单直接从 GPU 的 Capability 里读选项显示出来——但实际 CPU-PCH 的链路仍然是 Gen3 握手
一句话总结:
插槽是 4.0 的皮,链路是 3.0 的芯。
PCIe 协商是双向的——一方说 4.0 没用,双方都支持才是真 4.0。CPU 那端的 root complex 不支持,插宇宙最快的显卡也没用。
对 X99 双卡跑 LLM 的启示
如果你像我一样,想在 X99 上插两张卡跑 TP(张量并行),除了确认是 3.0 不是 4.0 之外,还要注意:
- X99 的 CPU 只有 40 条 PCIe 通道
- 两张 GPU 如果都插 x16 槽,实际可能是 x16 + x8(CPU 的 PCIe lane 分配限制)
- 如果第二张卡是 x8,那 PCIe 3.0 x8 ≈ ~5-7 GB/s,TP 模式的通信会成为明显瓶颈
- PP(流水线并行)比 TP 友好一些,但依然有影响
当然,单卡推理完全没所谓——模型加载到显存后,PCIe 只做偶尔的数据传输,瓶颈在算力和显存带宽上。
附:Windows 上怎么测?
如果是在 Windows 下,推荐:
工具 用法 GPU-Z 打开 → 点问号旁边的「Render Test」按钮 → 看 Bus Interface 那行从 @ x16 1.1升到@ x16 3.0就是 Gen3,升到@ x16 4.0才是真 Gen4AIDA64 Tools → GPGPU Benchmark,看 Host→Device / Device→Host 的带宽 nvidia-smi Windows 版一样可以用: nvidia-smi --query-gpu=pcie.link.gen.current,pcie.link.gen.max,pcie.link.width.current --format=csv快速排查命令(Linux)
# 1. 看 GPU 协商到的最大版本 nvidia-smi --query-gpu=pcie.link.gen.max --format=csv # 2. 看 PCIe 设备能力(Gen3=8GT/s, Gen4=16GT/s) sudo lspci -s <GPU_BUS> -vvv | grep LnkCap # 3. 跑实际带宽(最靠谱) gpu-pcie-bench --device 0 --direction both --unit gb数据说话,别信 BIOS 菜单里的花活。


