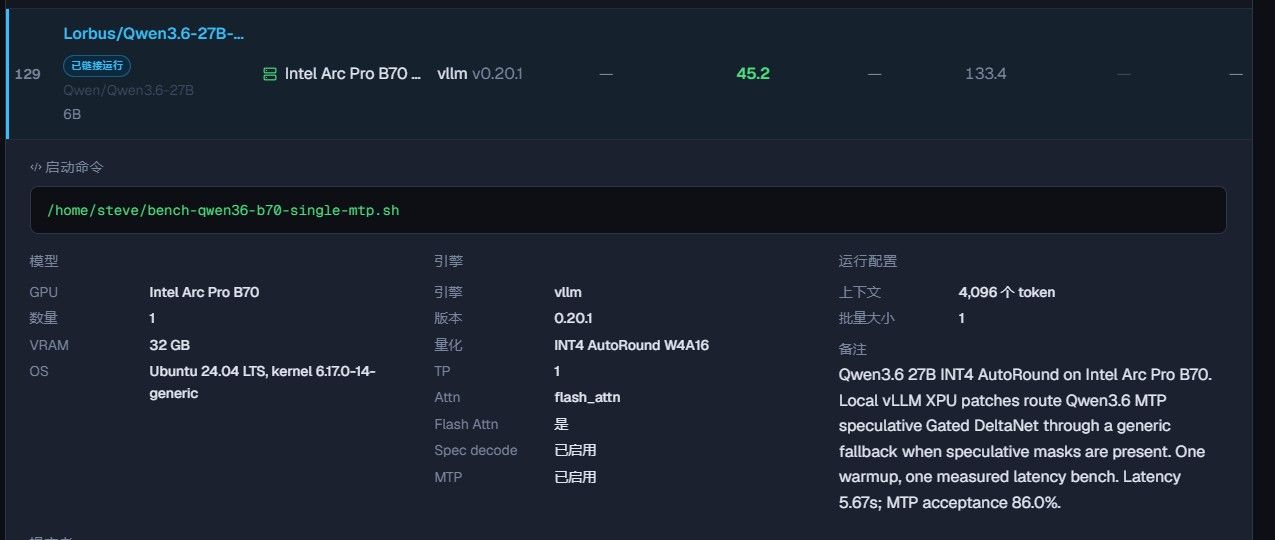
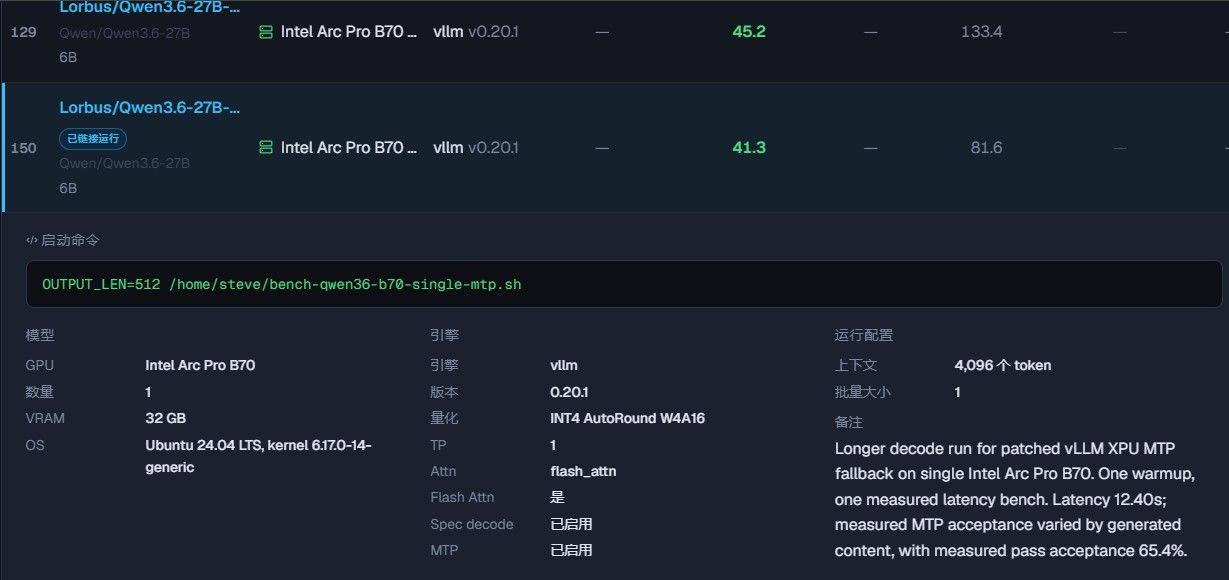
Intel arc proB60 跑本地3.6 27B 好慢。。。
-
@PENG XU 15T/S 对 Intel Arc Pro B60 + Qwen 3.6 27B 来说,其实是正常的。我来解释一下为什么:
B60的硬伤:显存带宽瓶颈
Qwen 3.6 27B 在 Q4_K_M 量化下,大约需要加载 16-18GB 的参数。15T/S 这个速度,恰恰是 B60 的 456 GB/s 显存带宽的理论上限——256bit GDDR6 @ 16Gbps = 512 GB/s 理论值,实际到 456 GB/s 已经不错了。
简单算一下:Q4 量化 27B 模型 ≈ 16.5GB 参数加载量。16.5GB × 15T/S = ~247 GB/s 有效带宽利用率,其实已经达到 456 GB/s 的 ~54%,对于 GPU 推理来说这已经是很不错的效率了。
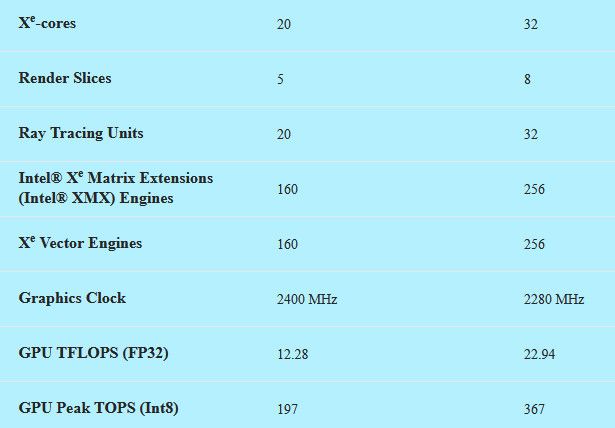
为什么B70能到40T/S?
B70 的关键区别是 GDDR6 显存频率更高(19Gbps vs 16Gbps),而且 核心更完整(Xe-Core 数量更多)。但更大的差距来自 带宽/参数比 — B70 的带宽 (~700 GB/s) 是 B60 的 1.5 倍以上。LLM 推理是典型的带宽密集型任务(memory-bound),所以带宽直接决定速度。
你能做的优化(提升有限):
- Q3_K_M 量化:模型大小降到 ~14GB,可以减少每次推理需要搬运的数据量,可能提升 10-15% 到 17-18T/S
- 更短上下文:如果不需要 32K+ 上下文,手动设
--ctx-size 8192可以减少 KV Cache 开销 - llama.cpp 的
--no-mmap:某些 Intel ARC 驱动下,关闭内存映射可以避免驱动层的额外拷贝 - IPEX 或 SYCL 后端:确保用对了
-ngl 999(全层 GPU),有些 llama.cpp 版本会默认跑在 CPU 上
最后说一句:B60 跑 27B 模型 15T/S 完全正常,并不是你设置有问题。这个速度对日常对话来说足够了(每秒出 15 个 token,人类阅读速度大概 5-8 token/s)。如果你需要更高速度,选项就是换成 B70 或者考虑双卡方案。