
淺談模型權重以及KV Cache的量化, GGUF (K Quant, I Quant), AWQ/GPTQ, Autoround, SmoothQuant, TurboQuant, KIVI
-
模型權重量化: AWQ/GPTQ
這個就是常用在vLLM的量化模式 (不是説GGUF不行, 但還在實驗性質)
兩者都屬 "僅權重訓練後量化" (Weight-only post-training quantization), 意思指在模型完成訓練後, 特意加入從高精度 (FP32/FP16) 轉換為低精度 (INT8/INT4) 的過程上做特殊處理, 這個就是與GGUF最大的分別
GGUF就單純只是將權重分塊打包壓縮, 并不涉及加入變成低精度的過程
GPTQ則是轉換時, 將權重壓縮成固定整數並計算誤差, 主要使用海森矩陣 (Hessian Matrix) 動態調整 "剩餘尚未量化的權重" 來進行進行精度補償
AWQ則是轉換時, 先尋找重要權重 (很多文章特別用了個salient, 顯著的意思?), 先將以其盡可能保留精度的方式壓縮, 其後再對其他比較不這麽重要的權重進行壓縮
示意圖
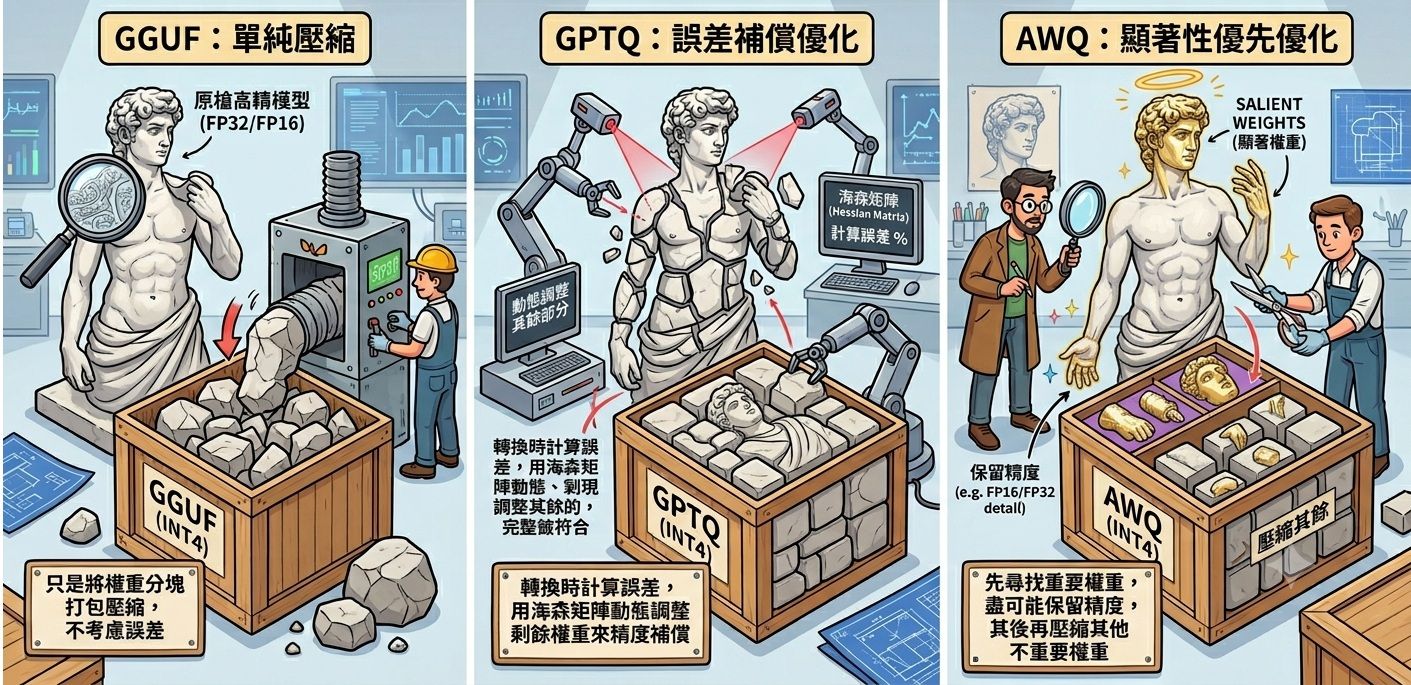
看見分別了嗎? 一個注重在壓縮前, 一個注重在壓縮後
再另外一個簡單類比的方式說其實就是兩個畫家嘗試將一副很大的壁畫畫在一塊小小的畫布上
一個畫家選擇直接下手, 以分塊的形式將每一部分都畫在畫布上, 然而因爲缺乏事前分析不可避免地會出現誤差, 然後這個畫師選擇在剩餘的空白畫布進行色差補償, 細看每一塊的話會明顯發現分別, 但是在放大整塊畫布上其實還是能大致看到輪廓
另外一個畫家選擇先研究整個壁畫, 找出比較重要/顯眼的部分, 例如人臉, 眼睛, 人的輪廓之類的, 在分析其他比較沒有這麽重要的地方 (例如背景, 天空), 在畫布上提前進行對於重要部分的對等比例縮放, 其他就簡單壓縮
示意圖

從比較高一點的角度看的話, 其實會發現AWQ的思路是跟I Quant十分類似, 兩者都是針對重要權重先進行比例壓縮, 盡可能保留高精度, 其他則按正常情況下壓縮
有人可能會問AWQ是不是比GPTQ好, 以精度上是, 但是這個也有代價, 則是AWQ在解壓後的VRAM 理論上 會比GPTQ多, 不過這個據聞現在已經有技術控制到兩者差不多了
那來講一下HF的model card
在HF上面會有寫INT4:
cyankiwi/Qwen3.6-27B-AWQ-INT4其實這個同時也代表4bit, 可以看成
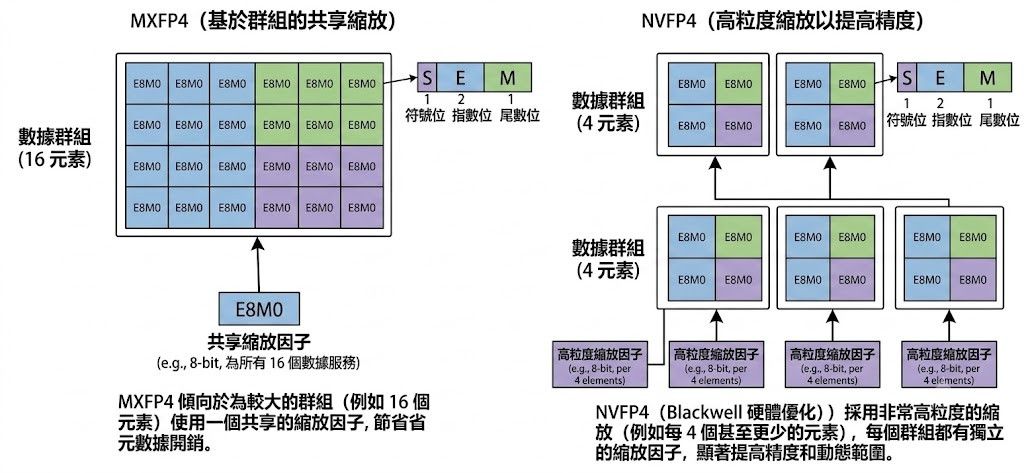
cyankiwi/Qwen3.6-27B-AWQ-4bit4 bit只是單純指壓縮大小, 然後INT4指是這個壓縮4 bit的方式, 它是用integer裝載這4 bit, 而不是floating point, 理論上,它可以用MXFP4跟NVFP4來裝載這4 bit, 精度損失會比單純用INT4少, 但NVFP4屬於Blackwell架構專用, 其他卡則只能使用MXFP4, 老黃聲稱MXFP4精度會比NVFP4少, 不過目前也算是聲稱吧
INT4示意圖:
 紅色是符號位, 藍色則是指數位
紅色是符號位, 藍色則是指數位MXFP4跟NVFP4示意圖:
然後有人可能會見到莫名其妙地有個6bit, 例如這個
QuantTrio/Qwen3.6-27B-AWQ-6Bit也許有人會好奇說6 bit, 但是顯示卡沒有INT6支持啊? 其實這個就是用了bit packing, 將幾個6 bit壓成多個4 bit再使用INT4的硬件加速
示意圖
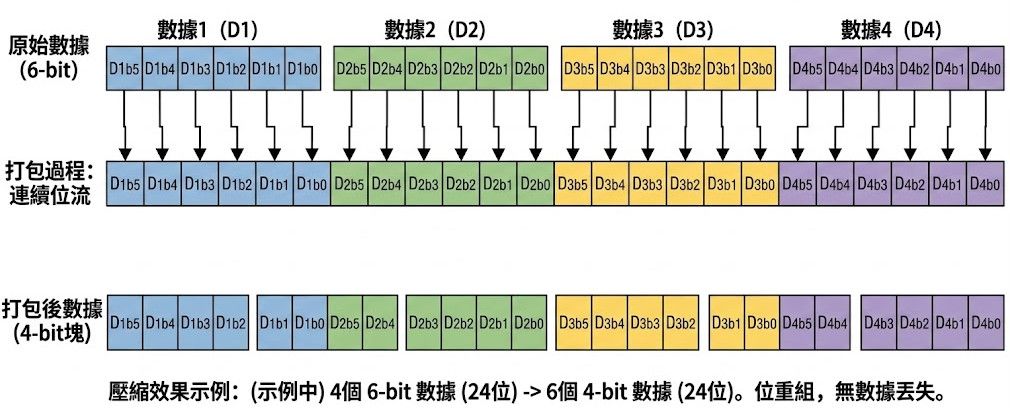
無論GGUF, AWQ, GPTQ怎麽壓縮, 它們都會把Activiation變回FP16, 則是W4A16的樣子
而從名字得知, 既然有僅權重訓練後量化, 會有不會有權重與激活一起量化?
有的, 這個就是SmoothQuant, 有SmoothQuant W8A8 (INT8), SmoothQuant W4A4 (INT4), 不過這個留在後面吧
下一篇講一下Intel出的Autoround, 不過估計得到下周末了
-
给个支持

我读完了
虽然不一定明白就对了
-
模型權重(優化後的?)量化方式: Autoround
來到一個可能是最多硬件都適配的量化方式了, Intel在2025年4月推出了一個名爲AutoRound的僅權重訓練後量化技術 (PTQ), 可以當成是上一篇有關AWQ跟GPTQ的衍生, 所以想要瞭解這個之前就需要搞清楚AWQ跟GPTQ的基礎概念
儘管上一篇説過AWQ跟GPTQ的4 Bit可以使用其他不同方式 (MXFP4或NVFP4) 來表現, 但是目前大部分流行模型引擎内核都是在使用
awq_marlin(Ampere跟Hopper架構都是), 因此這篇也會以INT4作爲基礎AWQ跟GPTQ在量化後就會進行低精度壓縮, AWQ會使用大量的INT4去先壓縮重要的權重, GPTQ則會直接把重要權重直接變成INT4, 然後在後面未量化的權重去進行補償
在這個壓縮過程的 最後 就是使用近約數 (Round-to-Nearest, RTN), 最簡單理解就是四捨五入
然後Intel就是在這裏下了功夫, 使用了一個名叫
符號梯度下降的技術 (Signed Gradient Descent, SignSGD), 透過反覆測試與學習, 找出捨入 (Round) 權重的絕對最佳方式,以及保存 (Clip, 也叫截斷) 權重範圍的最佳位置流程就是這樣:

普通的AWQ / GPTQ基本上量化+壓縮後就直接推到HF用了
Autoround透過引入一個小型的校準資料集 (約128到512個樣本) 到模型中, 讓模型檢視由壓縮所引起的區塊層級 (Block-wise) 的輸出誤差, 通過稍微調整捨入偏移量 (rounding offsets) 與保存範圍 (clipping ranges), 務求達到最低誤差
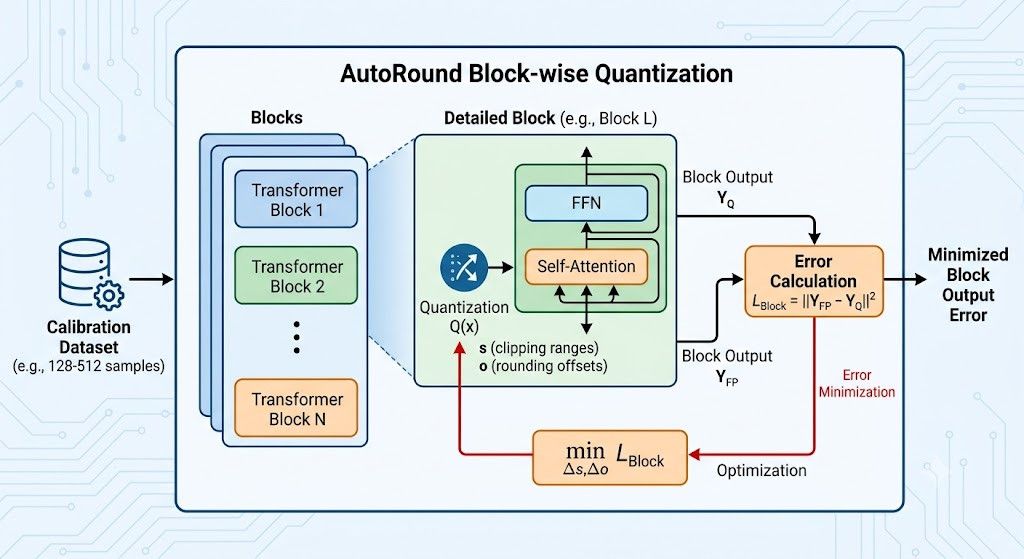
Autoround自己也支持混合Bit, 比較不重要的權重可以用少點Bit (1到2), 重要的話可以拉滿4個Bit
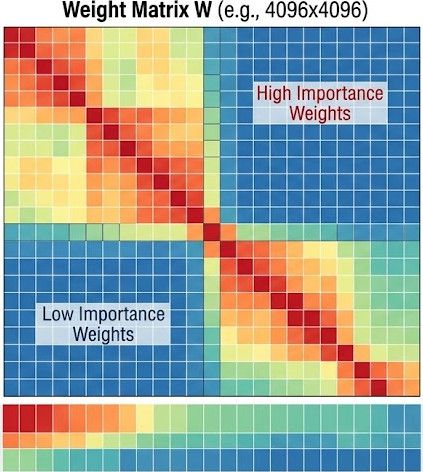
一個簡單的分佈圖, 然後壓縮後(下圖)會發現其實一個模型重要權重不會太多在輸出層(lm-head), 通常的量化方式都會保留最高精度 (FP16/FP32), Autoround也順道一并把這個壓縮了 (
雖然我覺得應該不會有太大影響就是了)正是以上的特點集合, Autoround在低Bit的情況下表現很出色, 很適合用在受限於INT4跟INT8的硬件 (尤其在Turing跟Ampere)
簡單類比下的話就是
GPTQ => 被動應變的畫家
AWQ => 主動應對的畫家, 會畫草稿
AutoRound => 操練過後的畫家本質上GPTQ跟AWQ就是單純使用色盤上顔色最近的顔料, AutoRound就再用一個更小的練習畫布嘗試畫畫看, 發現不對勁就會再調和整體色盤顔色 (例如簡單加黑或者加白來拉高或者拉低對比度), 通過小規模的反復試錯來找出畫整個畫像的規則, 最後用這個方法畫出整圖
Autoround嚴格上來説是一種屬於優化目前量化的思路, 所以也可以應用在GGUF上面, 所以我們會看到有應用Autoround的K Quant:
sphaela/Qwen3.6-27B-AutoRound-GGUF理論上I Quant也適用, 不過我還沒見到有人這麽做, 估計可能就是精度損失太大
Intel 自己也説了未來的方向就是低精度推算, SGLang配置INT2 到 INT8, MXFP4, NVFP4, FP8, and MXFP8的Autoround, 不過我是不太懂爲什麽特意拿SGLang作爲例子出來說, 可能有特別優化?
下篇講講SmoothQuant
-
,
 T terry 固定了此主题
T terry 固定了此主题
-
,系统 取消固定了此主题
-
,5 566656661 引用了 此主题
-
模型激活量化方式: SmoothQuant
正如之前的文章所說, 目前大部分模型都是W4A16 / W8A16, 自然就有專家會去探討激活參數中的16Bit (無論是FP16還是BF16) 是否能量化
但是他們遇到的問題則是: 量化激活比量化權重參數難
權重量化相對容易是因為分佈平坦且均勻, 然而當大型語言模型的參數規模突破 67 億時,其激活值基本上會出現Outliers (系統性離群值), 則該數值趨近無限大或者無限小 , 比大部分的數值高出不少的倍數
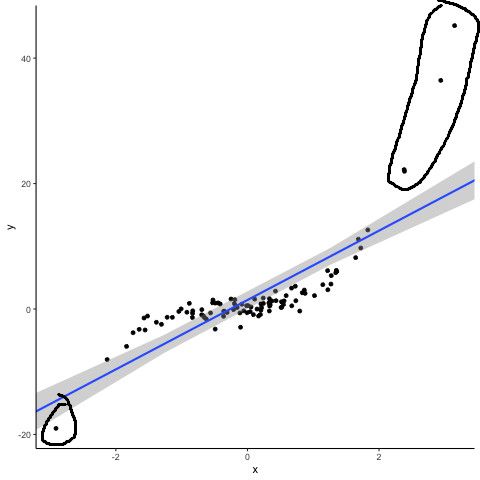
就是這些圈起來的東西, 雖然這個圖只有寥寥數個, 但是試想一下這個情況套用在DeepSeek 或者 GLM上那恐怖的參數量, 就算單純拿個1%分分鐘也比目前最好的小開源模型 (27B / 31B)大而強行將這些極端離群值壓縮進小整數網格 (INT8 / INT4)的話, 量化範圍必須拉得非常寬, 導致所有正常的較小激活值被壓縮至趨近於零, 進而嚴重摧毀模型的準確度
不能輕易動激活參數的位置的話, 專家們就把想法從 單純壓縮激活參數 轉移到 將量化的難度從「激活值」轉移至「權重」 :
- 縮小包含離群值的問題激活通道的數值
- 以完全相同的比例放大模型權重中對應通道的數值, 以維持底層數學運算的一致 (Scale Up跟 Scale down的運算)
透過引入一個叫 遷移強度 (migration strength) 的超參數 (hyperparameter) 來平衡量化難度, 確保權重與激活值都不會過於極端
SmoothQuant 是可以成功將激活值同時壓縮到W8A8 (論文中則是使用INT8), 讓硬體得以使用 INT8 * INT8 矩陣乘法, 相較當初的FP16能帶來高達 1.56 倍的加速比並使記憶體佔用量減半, 且幾乎完全不會損耗模型智能
SmoothQuant本身并不會針對權重本身進行任何更改, 本意在於調整權重在激活時候的通道數量跟方式
理論比較難懂, 給個比較具體點的例子
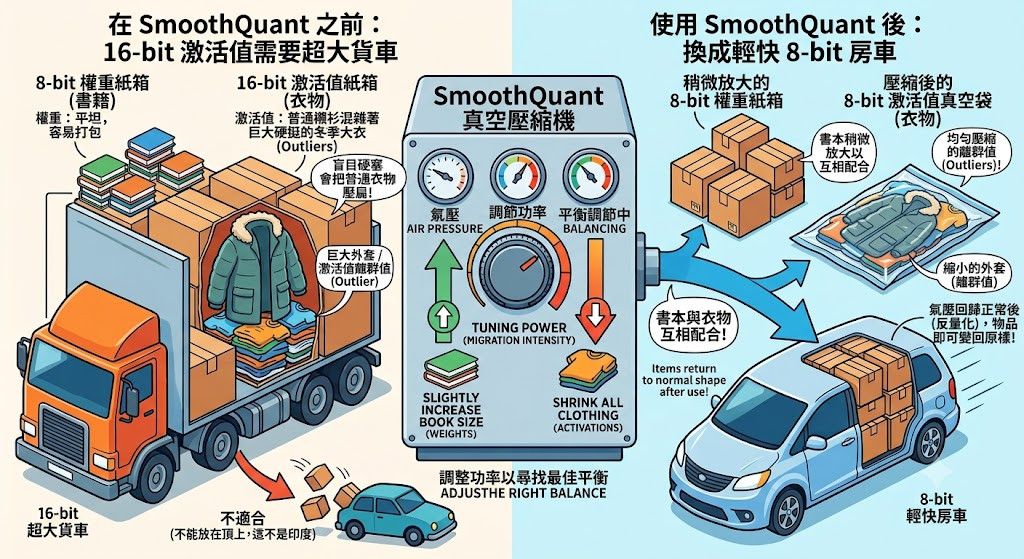
你準備搬家, 正在打包兩種不同類型的物品:
- 書籍: 這個就是權重, 平坦跟有固定規則, 天生就非常容易打包
- 衣物: 這個就是激活值, 多數是普通的襯衫/T恤, 但混著幾件巨大且硬挺的冬季大衣/外套 (Outliers)
儘管裝書本的箱子很迷你方便 (4bit / 8 bit), 但是因爲冬季衣服你不僅需要用個超大箱子裝 (16bit), 而且搬家的車子也被迫需要超大貨車 (不能用普通房車然後把箱子放在頂上吧, 這不是印度)
如果盲目硬把衣物塞進 8-bit 箱子, 那件巨大的冬季大衣會佔據太多空間,導致所有普通的衣物被壓到不成樣子
SmoothQuant 就像一台 真空壓縮機, 自帶調節功率的功能 (遷移強度)
透過調整功率來決定氣壓, 稍微放大書本跟縮小所有衣服, 讓他們能放到8 Bit箱子, 書本跟衣服都要在這裏互相配合才行, 然後所有東西在氣壓回歸正常後就能變回原樣
而貨車也能在這裏換成比較快的房車了, 整體搬家 (生成) 的速度也會更快
一圖流:
因爲Smooth Quant是針對激活參數進行量化, 理論上能配合任何的權重量化方式使用 (K/I Quant, GPTQ/AWQ), 不過我也沒找到huggingface 上有相對應的模型所以也沒有例子, 只找到單純SmoothQuant模型
Locosdeamor/Olmo-3.1-32B-Think-w8a8-smoothquant混合邏輯就是以下:
應用情境 / 架構 量化方案 技術說明與備註 Hopper / Ampere(僅量化權重至 INT4) AWQ若已擁有預訓練權重檔(Checkpoints), GPTQ同樣適用。Hopper(同時量化 INT4 權重與 INT8 激活值) AWQ+SmoothQuant需依序執行:先以 AWQ 壓縮權重,再以 SmoothQuant 平滑激活值。 Blackwell(權重 FP4 + 激活值 FP4) NVFP4AWQ 的縮放機制已直接整合至 NVFP4 官方量化工具中,無需額外搭配。 CPU / Apple Silicon(推論部署) GGUF(K-quants)AWQ 針對 GPU 最佳化;GGUF 則為 CPU/Apple Silicon 專用的底層實作。 下回終於聊到關於KV Cache的量化/優化方案, 第一個就是TurboQuant
-
然後額外再補充一點
正常的模型都會默認為W4A16 / W8A16, Smooth Quant則為W4A8 / W8A8 / W4A4
前面的Wx 指的就是儲存權重的Bit, 然而這個Bit單看數字某個程度上省略一個蠻重要的資訊:
模型是否在訓練階段特意選用低精度訓練
正常來説大部分的模型都是BF16 / FP16 甚至 FP32等高精度開始訓練, 再將權重量化
然而DeepSeek V4 自己提出的學術期刊報告 則寫明團隊打從訓練一開始目標就是使用低精度 (FP4 + FP8) 混合來進行量化感知訓練 (QAT, Quantization-Aware Training)
目的是强迫模型一開始就在低精度下進行模型訓練, 解決的就是在傳統量化後低精度推論下精度降低的問題
某個程度上這個也是推進低成本訓練的關鍵, 畢竟相對以前訓練能降低顯存用量, 也是DeepSeek V4能夠這麽便宜的其中一個原因
-
,T terry 固定了此主题
-
,系统 取消固定了此主题

