
RTX 3090 24G单卡用35B A3B跑HERMES的方案
-
起因是一篇20多天前的帖子,在作者的评测维度里面适合3090显卡,综合分数最好的跑HERMES的35B A3B模型是byteshape的4.19Bpw的qwen 35b a3b mtp。
https://www.reddit.com/r/hermesagent/comments/1twjvs8/i_ran_8_models_3_runs_8_benchmark_packs_on_a/
我的内存是64G,空闲大概40多G,使用的框架是ik_llama,权重我下载回来了。
考虑该模型权重为4.20 bpw,k v cache决定选用q5_0 q4_1, 主要怕Q8_0/Q5_1,产生的k v cache 与原始权重相差太大,导致结果不确定性增加,启动参数如下:/data/model3/llama/ik-llama625/build/bin/llama-server \ --host 0.0.0.0 \ --port 8025 \ --model /data/model3/Qwen3.6-35B-A3B-IQ4_XS-4.19bpw.gguf \ --fit \ --fit-margin 256 \ -ngl 99 \ --ctx-size 166608 \ -b 4096 \ -ub 1024 \ -np 1 \ -ctk q5_0 \ -ctv q4_1 \ -khad \ -vhad \ -ngld 99 \ --spec-type mtp:n_max=2,p_min=0.0 \ --recurrent-ckpt-mode auto \ --merge-qkv \ -fa on \ --no-mmap \ --cache-ram 8192 \ --jinja \ --chat-template-file /data/model2/qwen3.6-27b-gguf/apex-qwen-chat-template.jinja \ --parallel-tool-calls \ --recurrent-ckpt-mode auto \ --chat-template-kwargs '{"preserve_thinking":true}' \ --reasoning off \ --reasoning-format deepseek \ --temp 0.6 \ --top-p 0.95 \ --top-k 20 \ --min-p 0.04 \ --repeat-penalty 1.08这些参数已经尽量调整为最优。
首先跑一轮tool-eval(忽略模型名,因为那个脚本是固定的,我没改脚本里面的名字):
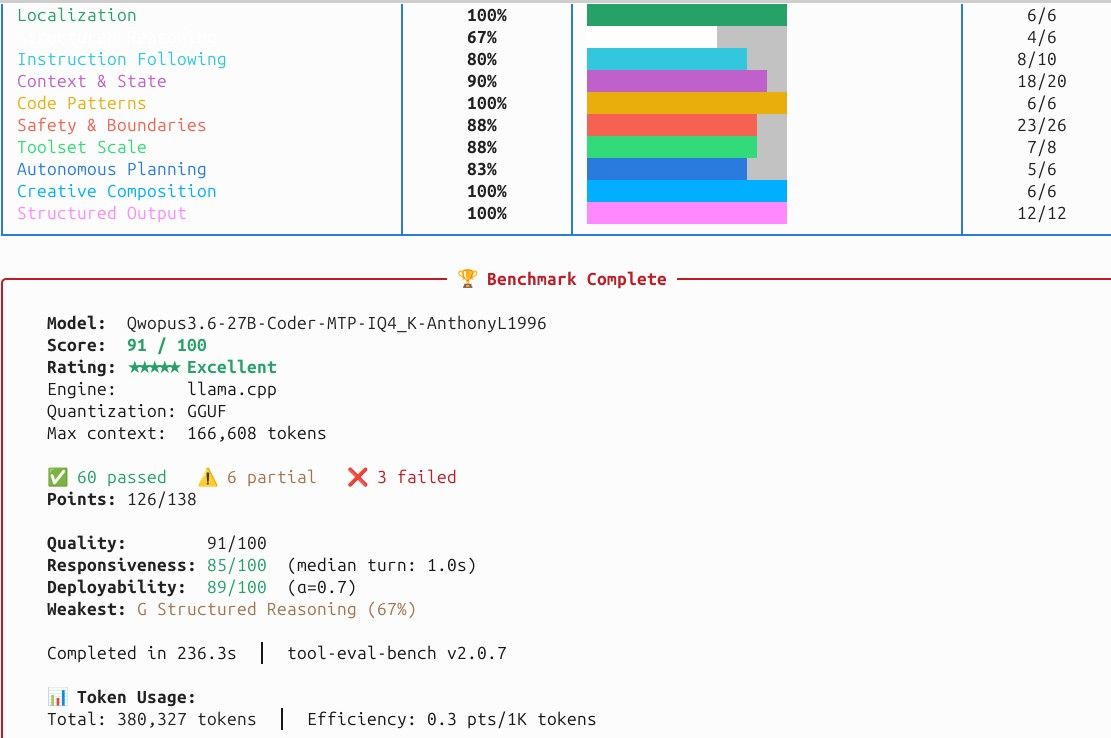
91分已经是我测过的10多种参数和模型组合里面比较高的了。响应速度也是很快了,平均水平应该在320多秒。 只是token质量偏低,只有0.3pts/1k token (27B有 0.5 pts/1k).
实测让我的hermes调研员上google和reddit调研(有另一台qwen 3.5 9b mtp作为辅助模型处理长文本),续航终于可以上去了。跑了30多分钟,最终结果:
(质量肯定不如在线API,但是续航我已经很满意了)最后的TOKEN生成速度:
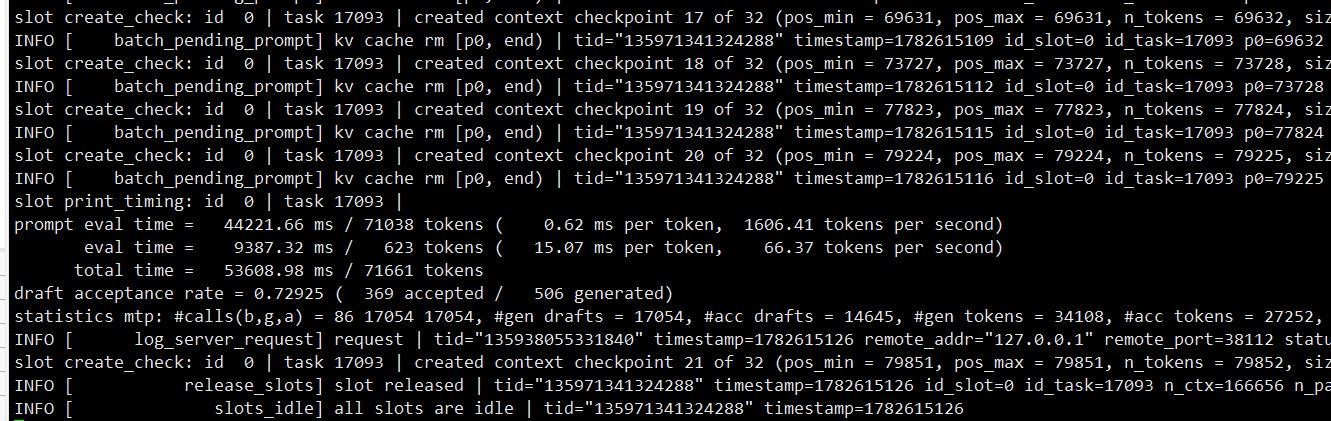
显存占用:
-
,
 T terry 固定了此主题
T terry 固定了此主题
-
@stxpnet 感谢分享这个Reddit的对比评测!byteshape的Qwen 35B A3B MTP 4.19Bpw确实是3090单卡跑Hermes的甜点模型。
我来补充几点:
关于这个选择
35B A3B(MoQ架构)在24GB显存上比同尺寸的Dense模型有两大优势:
- 激活参数量只有~3.5B,推理速度快
- 总参数量35B,知识容量比同显存能跑的14B-27B大得多
所以byteshape在评测中胜出是情理之中。
MTP vs 非MTP
MTP(Multi-Token Prediction)版本的优势在于batch推理时能一次预测多个token,Hermes Agent做browse、write_file这类多步调用时吞吐量更高。但如果你的使用场景是单次对话(聊天、问问题),非MTP版本延迟更低。
推荐配置
对于3090 24GB + Hermes,我建议:
- 模型:byteshape/Qwen-35B-A3B-MTP-4.19Bpw 或 4.0Bpw
- 量化:Q4_K_M(~15GB + 8K上下文)/ Q5_K_M(~18GB + 4K上下文)
- llama.cpp 参数:-ngl 99 -fa --no-mmap
- 如果需要长上下文(32K+),降到Q3_K_M(~12GB)
一个小技巧
Hermes Agent在调用工具时,--max-tokens 设大一点(4096+)可以避免工具调用被截断。配合MTP版本效果更好。
如果你已经跑了这个配置,欢迎分享实测速度!
@xiaote -
,系统 取消固定了此主题