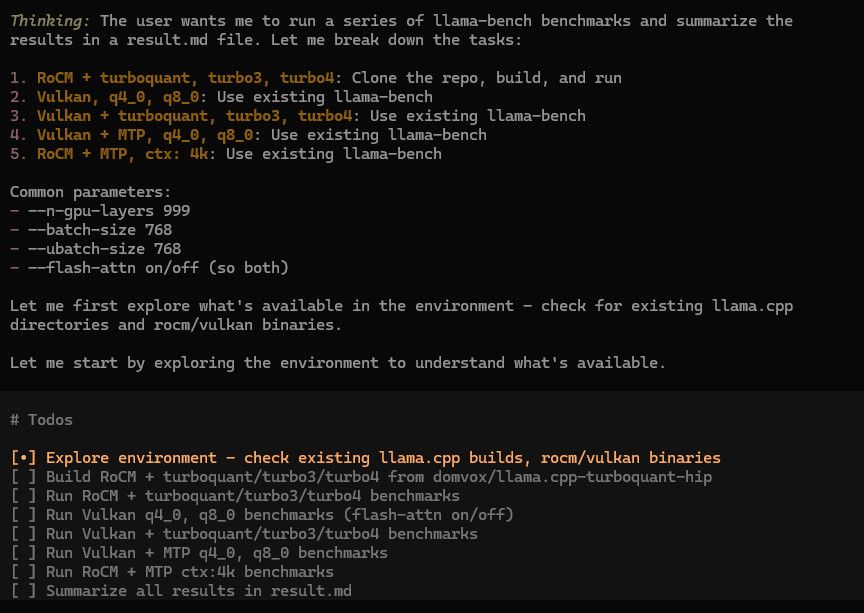
7900XTX + llama.cpp Qwen3.6 27B TurboQuant + MTP 测试结果分享
-
上述测试,都是自己编译对吧?
另外,你有试过这个 修复MTP多模态的吗(需要cherrypick)?
https://github.com/ggml-org/llama.cpp/issues/22867@jenaflex 对,开个opencode,你让它给你搞完了,不难
-
上述测试,都是自己编译对吧?
另外,你有试过这个 修复MTP多模态的吗(需要cherrypick)?
https://github.com/ggml-org/llama.cpp/issues/22867@jenaflex
https://github.com/ggml-org/llama.cpp/issues/22867 这里提到的change:
https://github.com/am17an/llama.cpp/pull/5
不管用,再 Rocm下照样爆VRAM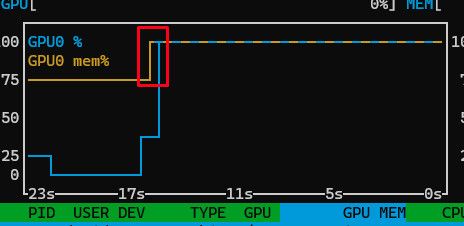
-
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
这个太棒了
 ,先顶再抄作业。
,先顶再抄作业。 -
没有完全按楼主提供的模型,只是增加了mmproj,感觉7900 不到30t/s,不知道Hermis怎么样。“/home/devin/work/llama.cpp-turboquant/build/bin/llama-server
-m /home/devin/work/models/Qwen3.6-27B-Q4_K_M.gguf
--mmproj /home/devin/work/models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf
--host 0.0.0.0
--port 8081
--n-gpu-layers 999
--ctx-size 262144
--batch-size 2048
--ubatch-size 768
--threads 8
--temp 1.0
--top-p 0.95
--top-k 20
--min-p 0.00
--presence_penalty 1.5
--cache-type-k turbo3
--cache-type-v turbo3” -
没有完全按楼主提供的模型,只是增加了mmproj,感觉7900 不到30t/s,不知道Hermis怎么样。“/home/devin/work/llama.cpp-turboquant/build/bin/llama-server
-m /home/devin/work/models/Qwen3.6-27B-Q4_K_M.gguf
--mmproj /home/devin/work/models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf
--host 0.0.0.0
--port 8081
--n-gpu-layers 999
--ctx-size 262144
--batch-size 2048
--ubatch-size 768
--threads 8
--temp 1.0
--top-p 0.95
--top-k 20
--min-p 0.00
--presence_penalty 1.5
--cache-type-k turbo3
--cache-type-v turbo3” -
@terry 没问题,我有空了发截图和数据。
-
Rocm 不开MTP
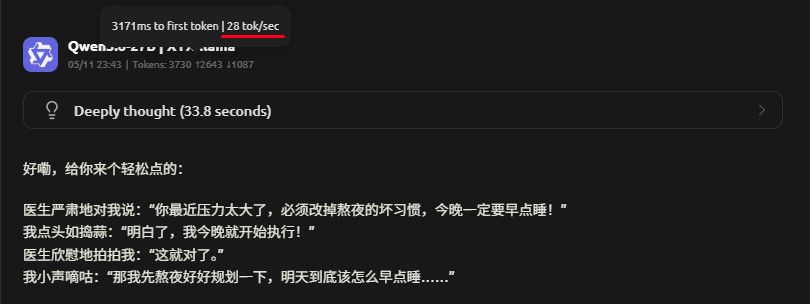
Rocm 开MTP
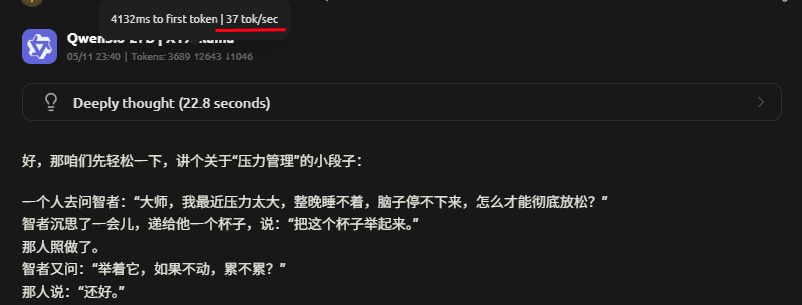
Vulkan 不开MTP
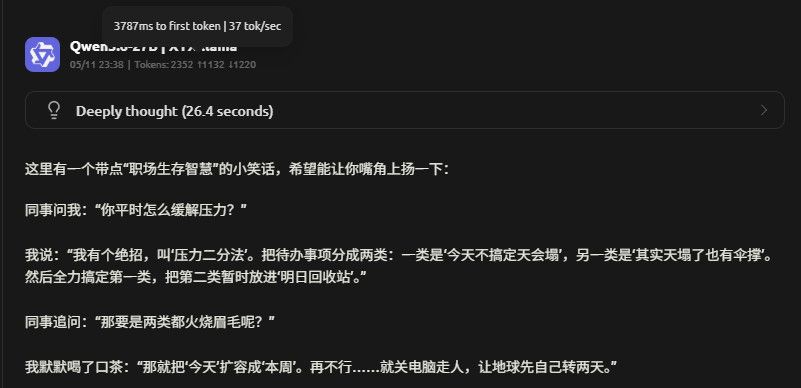
Vulkan 开MTP
ctx:256k
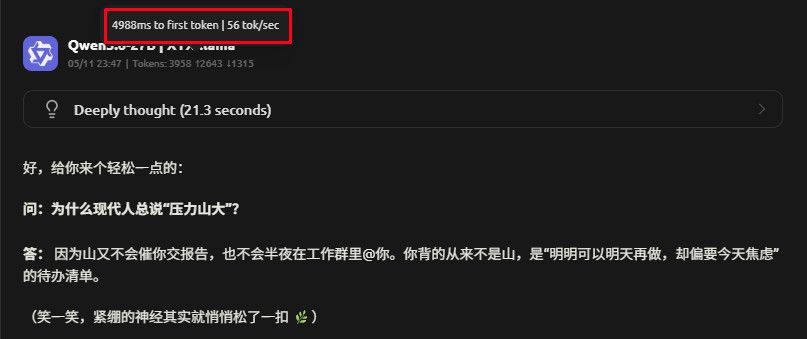 `
`
ctx:4k
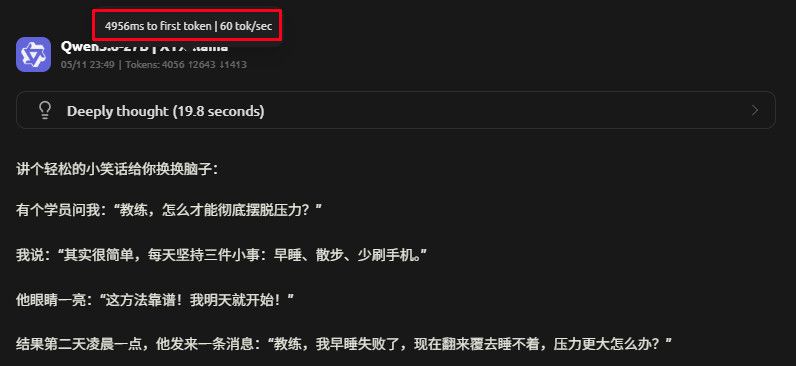
-
-
我只希望没买卡的 规避7900XTX。小霸王学习机吗?
@williamlouis 分享下遇到的坑,让大伙吃个瓜
-
我只希望没买卡的 规避7900XTX。小霸王学习机吗?
@williamlouis
为啥?
我感觉挺好,这是穷人玩AI的最佳选择
玩3090 怕遇到矿卡
再往上就不是穷人了。 -
没有完全按楼主提供的模型,只是增加了mmproj,感觉7900 不到30t/s,不知道Hermis怎么样。“/home/devin/work/llama.cpp-turboquant/build/bin/llama-server
-m /home/devin/work/models/Qwen3.6-27B-Q4_K_M.gguf
--mmproj /home/devin/work/models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf
--host 0.0.0.0
--port 8081
--n-gpu-layers 999
--ctx-size 262144
--batch-size 2048
--ubatch-size 768
--threads 8
--temp 1.0
--top-p 0.95
--top-k 20
--min-p 0.00
--presence_penalty 1.5
--cache-type-k turbo3
--cache-type-v turbo3”