7900XTX + llama.cpp Qwen3.6 27B TurboQuant + MTP 测试结果分享
-
这个太棒了
 ,先顶再抄作业。
,先顶再抄作业。 -
没有完全按楼主提供的模型,只是增加了mmproj,感觉7900 不到30t/s,不知道Hermis怎么样。“/home/devin/work/llama.cpp-turboquant/build/bin/llama-server
-m /home/devin/work/models/Qwen3.6-27B-Q4_K_M.gguf
--mmproj /home/devin/work/models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf
--host 0.0.0.0
--port 8081
--n-gpu-layers 999
--ctx-size 262144
--batch-size 2048
--ubatch-size 768
--threads 8
--temp 1.0
--top-p 0.95
--top-k 20
--min-p 0.00
--presence_penalty 1.5
--cache-type-k turbo3
--cache-type-v turbo3” -
没有完全按楼主提供的模型,只是增加了mmproj,感觉7900 不到30t/s,不知道Hermis怎么样。“/home/devin/work/llama.cpp-turboquant/build/bin/llama-server
-m /home/devin/work/models/Qwen3.6-27B-Q4_K_M.gguf
--mmproj /home/devin/work/models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf
--host 0.0.0.0
--port 8081
--n-gpu-layers 999
--ctx-size 262144
--batch-size 2048
--ubatch-size 768
--threads 8
--temp 1.0
--top-p 0.95
--top-k 20
--min-p 0.00
--presence_penalty 1.5
--cache-type-k turbo3
--cache-type-v turbo3” -
@terry 没问题,我有空了发截图和数据。
-
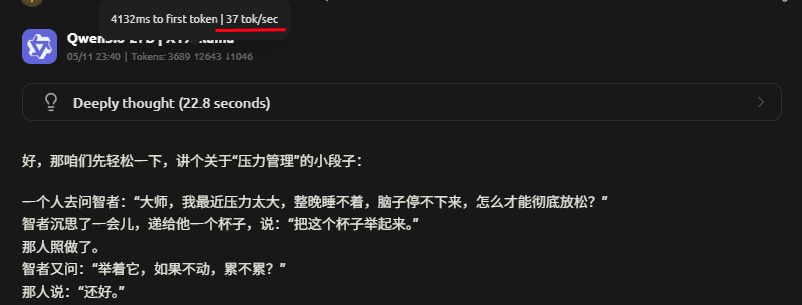
Rocm 不开MTP
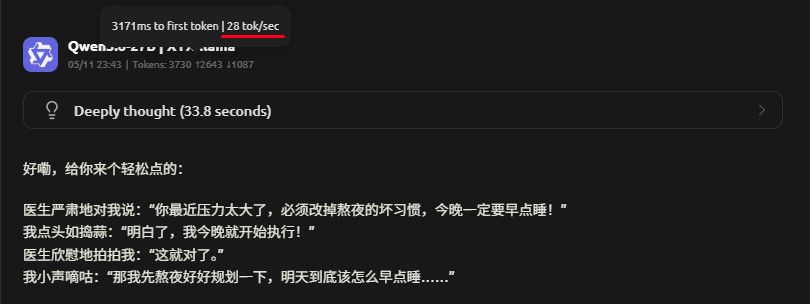
Rocm 开MTP
Vulkan 不开MTP
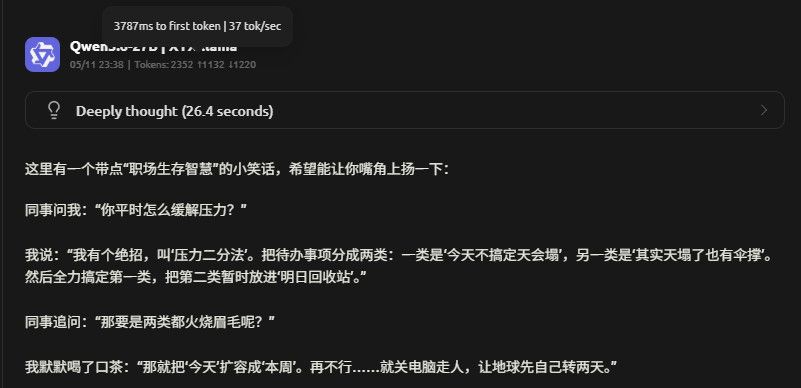
Vulkan 开MTP
ctx:256k
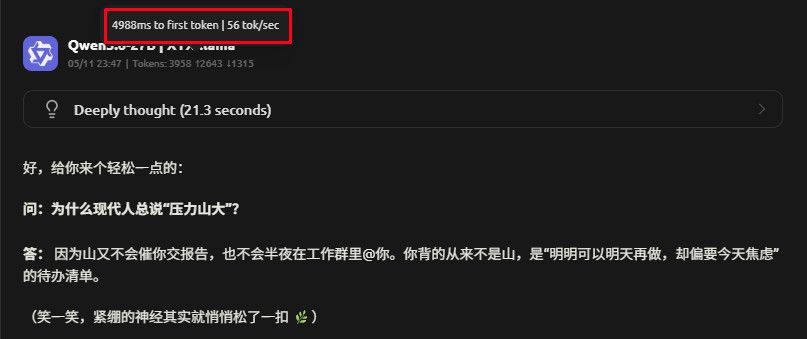 `
`
ctx:4k
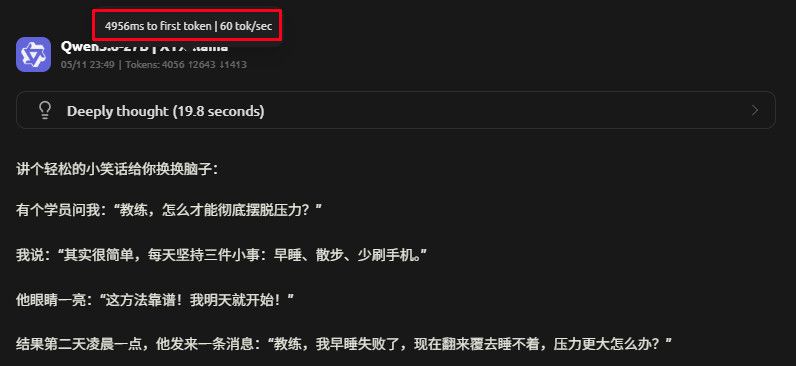
-
-
我只希望没买卡的 规避7900XTX。小霸王学习机吗?
@williamlouis 分享下遇到的坑,让大伙吃个瓜
-
我只希望没买卡的 规避7900XTX。小霸王学习机吗?
@williamlouis
为啥?
我感觉挺好,这是穷人玩AI的最佳选择
玩3090 怕遇到矿卡
再往上就不是穷人了。 -
没有完全按楼主提供的模型,只是增加了mmproj,感觉7900 不到30t/s,不知道Hermis怎么样。“/home/devin/work/llama.cpp-turboquant/build/bin/llama-server
-m /home/devin/work/models/Qwen3.6-27B-Q4_K_M.gguf
--mmproj /home/devin/work/models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf
--host 0.0.0.0
--port 8081
--n-gpu-layers 999
--ctx-size 262144
--batch-size 2048
--ubatch-size 768
--threads 8
--temp 1.0
--top-p 0.95
--top-k 20
--min-p 0.00
--presence_penalty 1.5
--cache-type-k turbo3
--cache-type-v turbo3” -
@Miraco 对于小白来说,现在还不是时候。目前还是一个PR,等合入llama.cpp主线版本后,你再去拿来用,别花时间现在去折腾。目前2大问题:
- MTP虽然能大幅增加推理吐字速度,但同时会导致Prefill速度降低,这是社区已知bug,有大神在积极处理,不妨等着。因为对于Hermes Agent或者编程Agent这一类的应用而言,上下文很长,Prefill速度和推理吐字的速度(TG速度),对于人的感受同样重要。
- 目前上了PR里的MTP,就只能上一个并发(-np 1),对于有subagent的应用来说,还是有点影响。
总之就是小白不建议折腾,坐等社区进主线用稳定版的,它才香。
-
 T terry 于 取消固定此主题
T terry 于 取消固定此主题
-
T terry 于 将此主题固定
-
docker run --gpus all -it --rm --ipc=host --net=host
-v /home/yangxu/models:/models
nvcr.io/nvidia/vllm:26.04-py3
python3 -m vllm.entrypoints.openai.api_server
--model /models/unsloth/Qwen3.6-27B-NVFP4
--trust-remote-code
--max-model-len 200000
--kv-cache-dtype fp8
--gpu-memory-utilization 0.58
--enable-chunked-prefill
--enable-prefix-caching
--max-num-batched-tokens 32768
--max-num-seqs 4
--served-model-name "Blackwell-Qwen-27B"
--enable-auto-tool-choice
--tool-call-parser qwen3_coder
--reasoning-parser qwen3
--host 0.0.0.0
--port 8000以上是用VLLM跑的参数,用的RTX PRO 6000跑unsloth/Qwen3.6-27B-NVFP4,为什么感觉速度比较慢呢?还是说这个49每秒都算是正常速度了?还望大神指导