2080Ti 22G魔改版+llama.cpp pr-22673开启MTP Chat场景TPS提升20%左右
-
@Fred 我平时不加MTP是,utility基本都95%以上了, MTP再消耗一部分算力,在20这样的算力基础上,估计也就提升到这意思了。适合入门或者应用频率不高的chat场景。
-
入门耍耍呗。没有生产力。锤锤的核心是有项目再起飞。你现在就是熟悉这个折腾的流程就行。有项目了再搞硬件。
-
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
系统 于 取消固定此主题
-
前几天看到MTP的PR合并主线了,拉下来编译了一下,配合unsloth的带TPM的Q4量化模型,感觉这个显卡还可以再战。
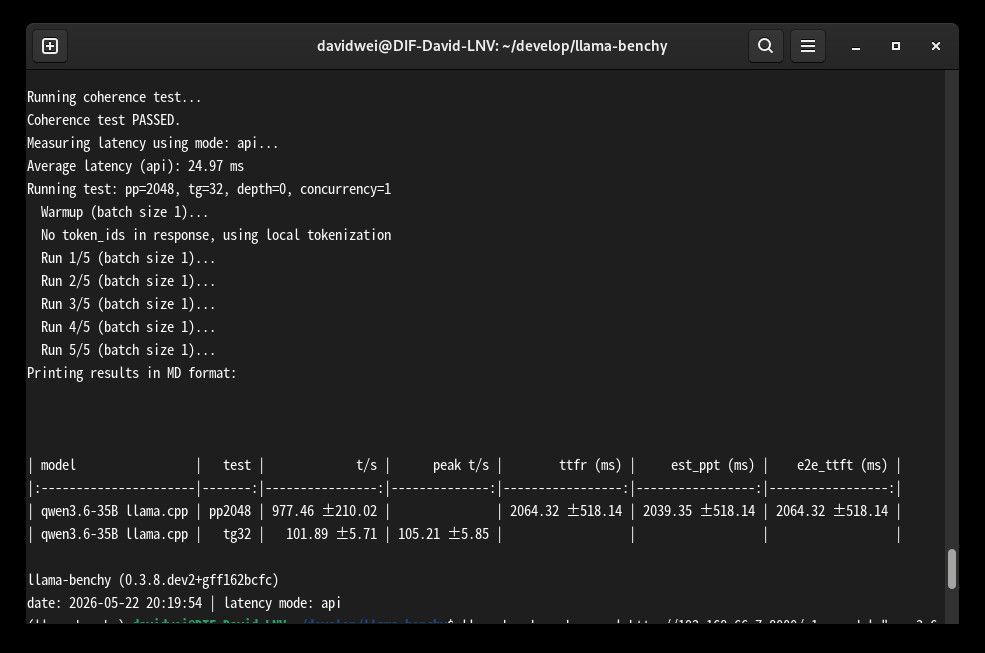
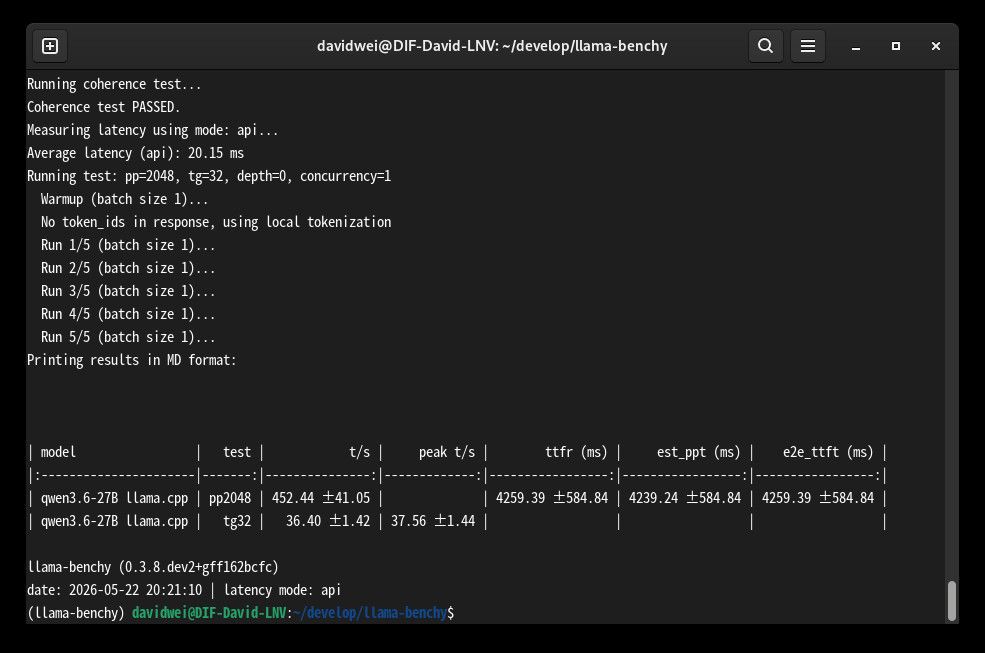
Qwen3.6-35B-A3B Q4_K_M, 双卡, 101.89 TPSmodel test t/s peak t/s ttfr (ms) est_ppt (ms) e2e_ttft (ms) qwen3.6-35B llama.cpp pp2048 977.46 ± 210.02 2064.32 ± 518.14 2039.35 ± 518.14 2064.32 ± 518.14 qwen3.6-35B llama.cpp tg32 101.89 ± 5.71 105.21 ± 5.85 Qwen3.6-27B Q4_K_M, 双卡, 36.4 TPS
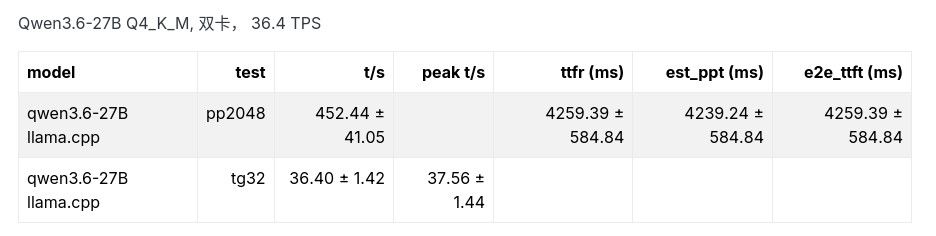
model test t/s peak t/s ttfr (ms) est_ppt (ms) e2e_ttft (ms) qwen3.6-27B llama.cpp pp2048 452.44 ± 41.05 4259.39 ± 584.84 4239.24 ± 584.84 4259.39 ± 584.84 qwen3.6-27B llama.cpp tg32 36.40 ± 1.42 37.56 ± 1.44 Qwen3.6-35B-A3B,有没有NVLink速度都差不多; Qwen3.6-27B,没有NVLINK的话, TPS稍微少一点,在30左右,不如单卡。
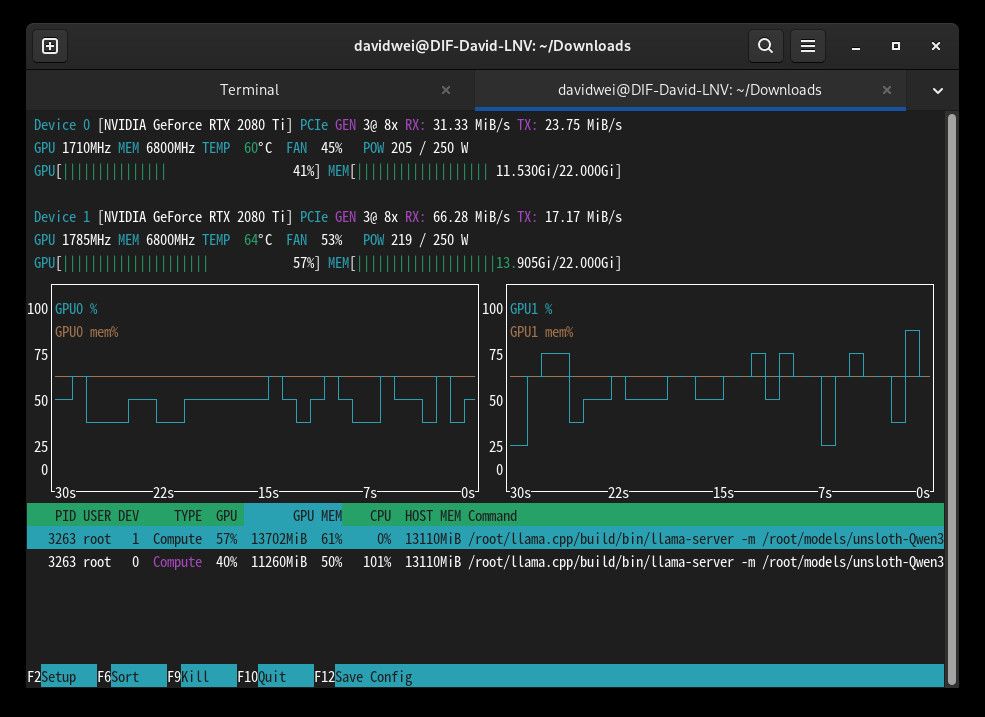
但是2080Ti 22G这个卡,单卡跑不了Qwen3.6-35B-A3B Q4_K_M, 我上面帖子那个跑27B模型的,也不是特别稳定,一周遇到两次OOM. 所以如果不是双卡,就不要挂mmproj了,很容易OOM.
还有, 最近用Qwen3.6-35B-A3B 配合Hermes,感觉没有想象的那么拉。任务简单一点,基本都能做,结果也能接受。太复杂的任务,在另一个连着GLM-5.1或者MINIMAX2.7的Hermes上跑一下,然后复制过来就行了,私密场景的,也没有特别复杂的任务。配合100多TPS的速度,整体感觉很爽。PS: 这两张卡是去年买了,总成本5k,现在我看4k就能拿下了,建议如果只跑Hermes,能接受Qwen3.6-35B-A3B 智商的,可以入,还能战。
-
请问27B的prompt处理速度是多少?我现在峰值600,慢慢就到500左右了,体感不好。35BA3B可以上千。按理说都在显存里,应该很快呀。
Q4KM的还行,UD的不行,说多了爆显存
version = 1 [*] parallel = 1 n-gpu-layers = 999 ctx-size = 65536 predict = 8192 flash-attn = on cache-type-k = q4_0 cache-type-v = q4_0 threads = 8 threads-batch = 16 batch-size = 8192 ubatch-size = 512 jinja = true reasoning = off reasoning-budget = 0 cache-prompt = true cache-reuse = 256 kv-offload = true kv-unified = true context-shift = true no-mmap = true temp = 0.6 top-p = 0.9 top-k = 40 min-p = 0.0 presence-penalty = 0.0 repeat-penalty = 1.03 load-on-startup = false stop-timeout = 10 [default] model = C:\models\Qwen3.6-27B-Q4_K_M.gguf ; 128k ctx-size = 131072 spec-type = draft-mtp spec-draft-n-max = 2 cache-type-k-draft = q4_0 cache-type-v-draft = q4_0 batch-size = 8192 ubatch-size = 1024 [qwen36-27b-ud-q4k-xl-hermes-fast-read] model = C:\models\Qwen3.6-27B-UD-Q4_K_XL.gguf ; 128k ctx-size = 131072 spec-type = draft-mtp spec-draft-n-max = 1 cache-type-k-draft = q4_0 cache-type-v-draft = q4_0 batch-size = 16384 ubatch-size = 1024 -
你是说prefill? pp2048:452.44 ± 41.05 。 35B-A3B可以到977.46 ± 210.02
-
请问27B的prompt处理速度是多少?我现在峰值600,慢慢就到500左右了,体感不好。35BA3B可以上千。按理说都在显存里,应该很快呀。
Q4KM的还行,UD的不行,说多了爆显存
version = 1 [*] parallel = 1 n-gpu-layers = 999 ctx-size = 65536 predict = 8192 flash-attn = on cache-type-k = q4_0 cache-type-v = q4_0 threads = 8 threads-batch = 16 batch-size = 8192 ubatch-size = 512 jinja = true reasoning = off reasoning-budget = 0 cache-prompt = true cache-reuse = 256 kv-offload = true kv-unified = true context-shift = true no-mmap = true temp = 0.6 top-p = 0.9 top-k = 40 min-p = 0.0 presence-penalty = 0.0 repeat-penalty = 1.03 load-on-startup = false stop-timeout = 10 [default] model = C:\models\Qwen3.6-27B-Q4_K_M.gguf ; 128k ctx-size = 131072 spec-type = draft-mtp spec-draft-n-max = 2 cache-type-k-draft = q4_0 cache-type-v-draft = q4_0 batch-size = 8192 ubatch-size = 1024 [qwen36-27b-ud-q4k-xl-hermes-fast-read] model = C:\models\Qwen3.6-27B-UD-Q4_K_XL.gguf ; 128k ctx-size = 131072 spec-type = draft-mtp spec-draft-n-max = 1 cache-type-k-draft = q4_0 cache-type-v-draft = q4_0 batch-size = 16384 ubatch-size = 1024 -
你是说prefill? pp2048:452.44 ± 41.05 。 35B-A3B可以到977.46 ± 210.02
@davidwei0826 我跟你这差不多,看来到极限了
-
@Tony-Wang 看来没啥好优化的了,但是没得说,27b干活是真爽
-
T terry 于 将此主题固定
-
根据https://www.youtube.com/watch?v=nU9c-PffHPg&t=361s,我用2080ti22G可以跑qwen3.6-35b模型24token/s
cuda下载是12.4
启动参数
@echo off
chcp 65001 >nul
cd /d C:\llmllama-server.exe ^
-m "models\Qwen3.6-35B-A3B-UD-Q4_K_M.gguf" ^
--mmproj "models\mmproj-BF16.gguf" ^
-ngl 99 ^
--n-cpu-moe 999 ^
--flash-attn on ^
--jinja ^
-c 65536 ^
-t 10 ^
-b 4096 ^
-ub 128 ^
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
--mlock ^
--host 127.0.0.1 ^
--port 8080pause
-
系统 于 取消固定此主题