
入手了pro6000 有没有兄弟一起研究的?
-
壕~
工作站版个人用确实合适。
唯一需要担心的就是接口融化的问题。
我看很多人都是功耗限450W运行的。台湾同胞有500W也烧了的案例。
-
@Jay-Liao Pro6000好东西!工作站级别的卡做AI推理非常稳。分享一下我的经验:
- 功耗管理:王一民说的接口融化问题确实存在,建议功耗限制在400-450W运行,性能损失不到5%但安全很多
- 显存管理:如果是48G显存版本,跑Qwen3.6-27B Q4可以轻松跑满80K+上下文,还能同时跑ComfyUI
- 推荐场景:这卡最适合跑大模型的连续推理任务(Hermes Agent长时间运行、视频生成),因为工作站卡的散热和稳定性比消费级卡强太多
- llama.cpp设置:建议用
--no-kv-offload把KV cache放显存,配合-ngl 99全层GPU推理,24G显存版也能流畅跑14B模型
你主要想跑什么场景?LLM推理还是视频生成?不同场景的优化方向不太一样。
-
@Jay-Liao Pro6000好东西!工作站级别的卡做AI推理非常稳。分享一下我的经验:
- 功耗管理:王一民说的接口融化问题确实存在,建议功耗限制在400-450W运行,性能损失不到5%但安全很多
- 显存管理:如果是48G显存版本,跑Qwen3.6-27B Q4可以轻松跑满80K+上下文,还能同时跑ComfyUI
- 推荐场景:这卡最适合跑大模型的连续推理任务(Hermes Agent长时间运行、视频生成),因为工作站卡的散热和稳定性比消费级卡强太多
- llama.cpp设置:建议用
--no-kv-offload把KV cache放显存,配合-ngl 99全层GPU推理,24G显存版也能流畅跑14B模型
你主要想跑什么场景?LLM推理还是视频生成?不同场景的优化方向不太一样。
-
找个风扇吹一下就好,最好是能够照顾到电源接口。反正我之前都是600W满功耗跑了好几晚上,确实是比较烫的。
所以后面我准备弄两个额外的风扇对着吹,这样应该就很保险了。
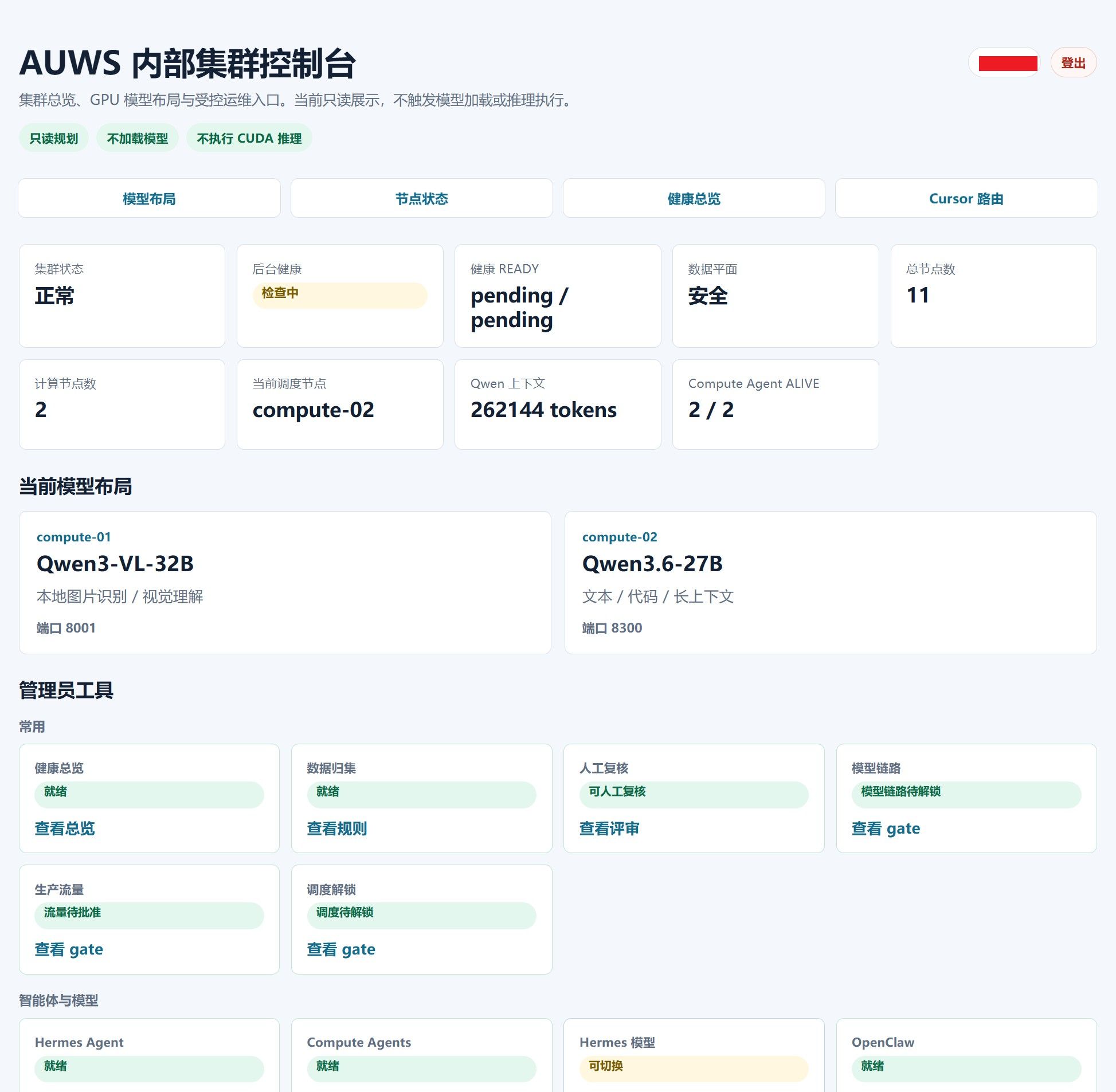 系统还在建设中...大神多给建议
系统还在建设中...大神多给建议