
分享自己的經驗 # 7900 XTX 本地 LLM 優化實測報告(Qwen3.6-27B)
-
謝謝樓主分享,我也成功在W7900上面跑Qwen3.6 27b Q4 MTP模型了,也掛了圖形識別模型成功。我用實際路徑的設定成功。輸出速度部分從原本的20t/s有增加到50t/s左右,從速度勉強可接受變成速度感覺順暢。更重要的是我也同時學會用llama.cpp在windows11架server了! 這軟體穩定度比lmstudio更好,模型載入速度超順暢。
@echo off
"D:\llama.cpp\build\bin\llama-server.exe" ^
-m "D:\llama.cpp\Qwen3.6-27B-MTP-Q4_K_M.gguf" ^
--mmproj "D:\llama.cpp\mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf" ^
--device Vulkan0 -ngl 999 -c 262144 ^
--temp 0.4 ^
--no-mmap ^
--api-key "*******" ^
-ctk q4_0 -ctv q4_0 -np 1 ^
--spec-type draft-mtp --spec-draft-n-max 3 ^
--reasoning off -fa 1 ^
--port 8081 --host 0.0.0.0
pause@Kiner-Liu 老弟你这张卡48G,虽然在数据中心算是垃圾,但是在个人市场是神器啊,这卡可不便宜,应该相当于48G的xtx,给分享下数据呗。弄些截图,运行日志,comfyui LLM都测试下。我们也学习下,我好云一期。
-
@bin-flamebox 发测试结果来参考下。
@terry
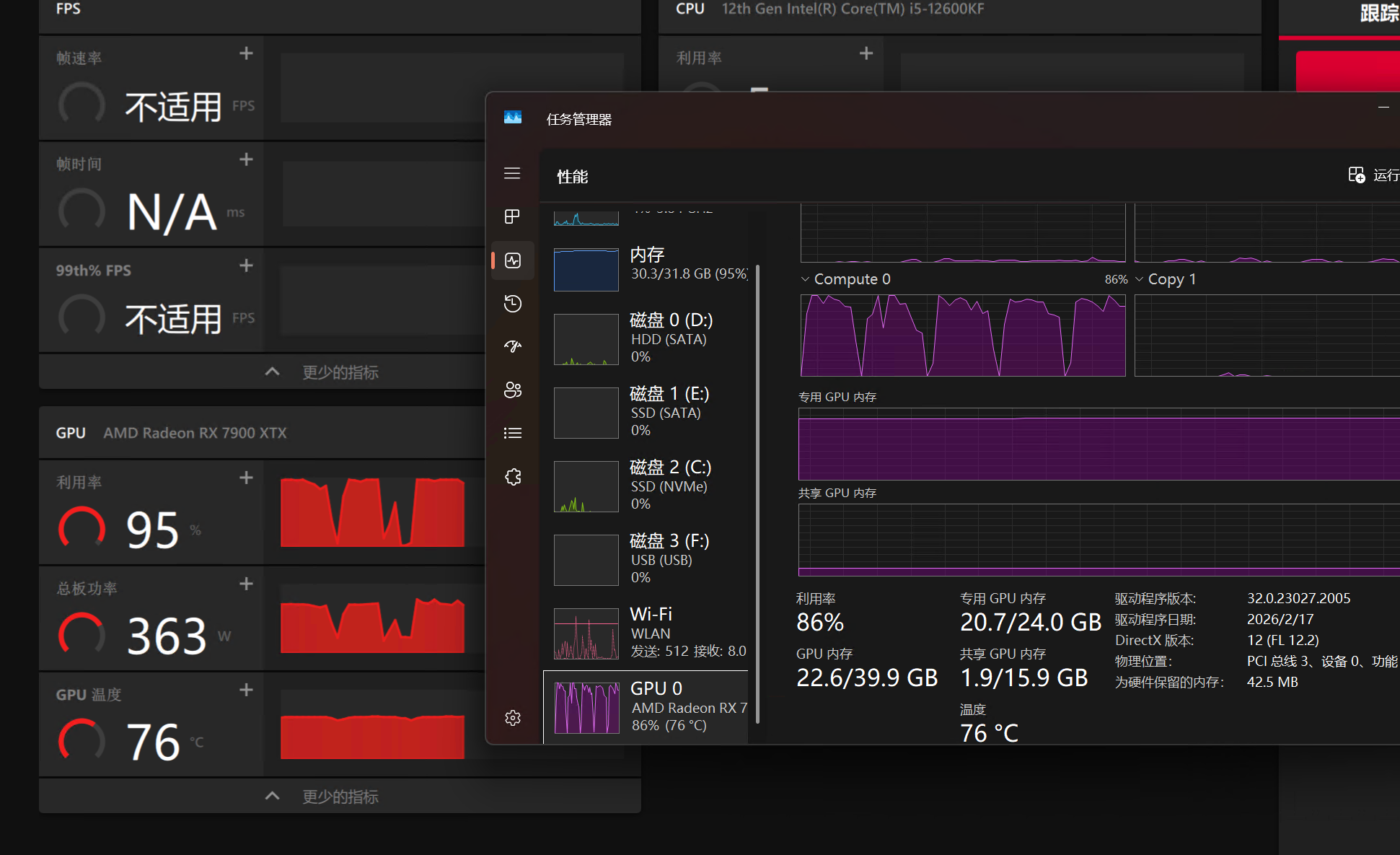
拿到手了。一开始用的是linux,一通环境全部装好了,什么rocm、vulkan乱七八糟的。本来挺顺的,但后来跑comfyui后却莫名卡死了,然后就不认驱动了 。怎么反复重装都没用,就算恢复到最开始的系统快照也是这样,莫名其妙!想一想,还是装回windows好了。。。
。怎么反复重装都没用,就算恢复到最开始的系统快照也是这样,莫名其妙!想一想,还是装回windows好了。。。
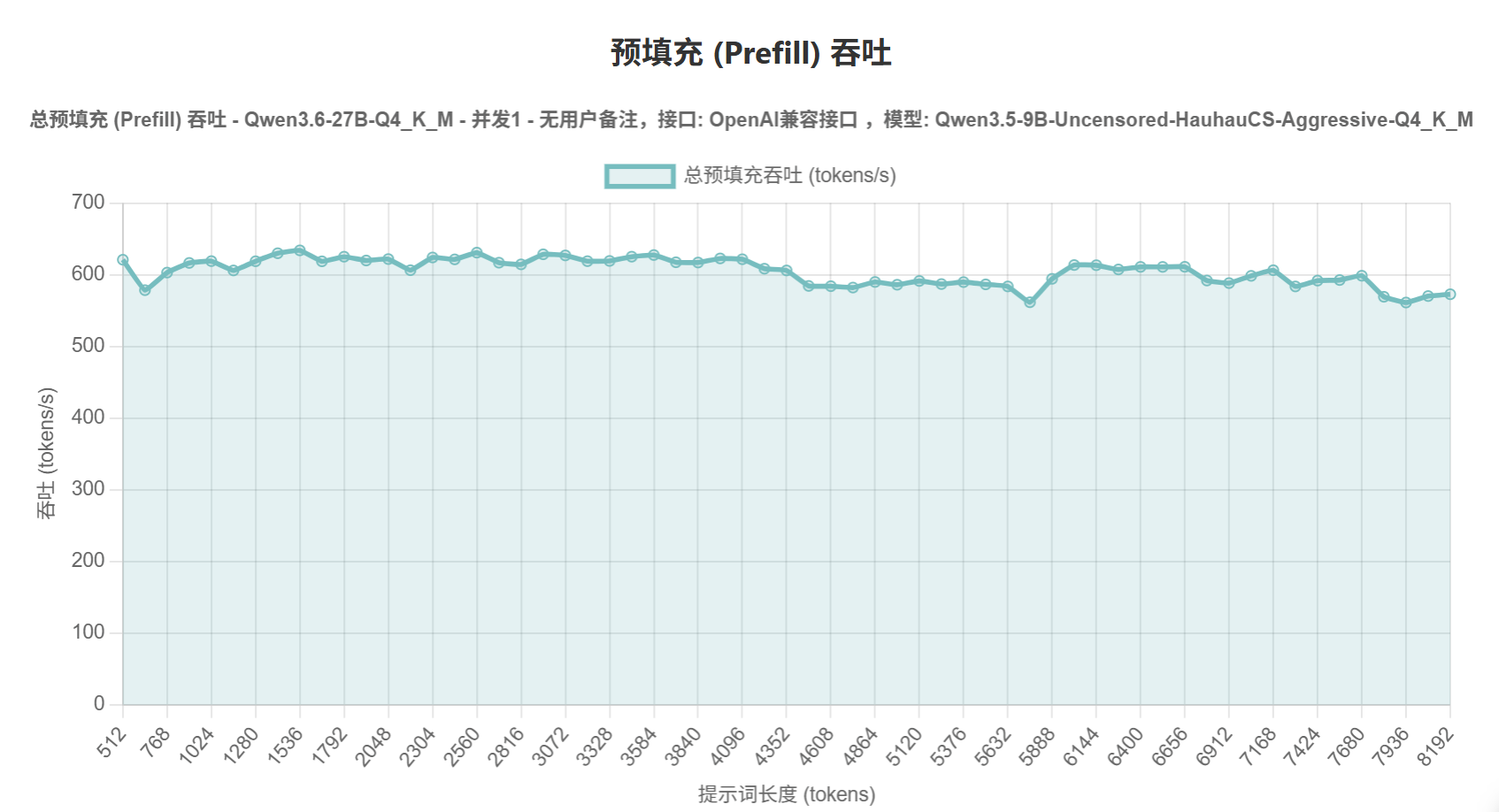
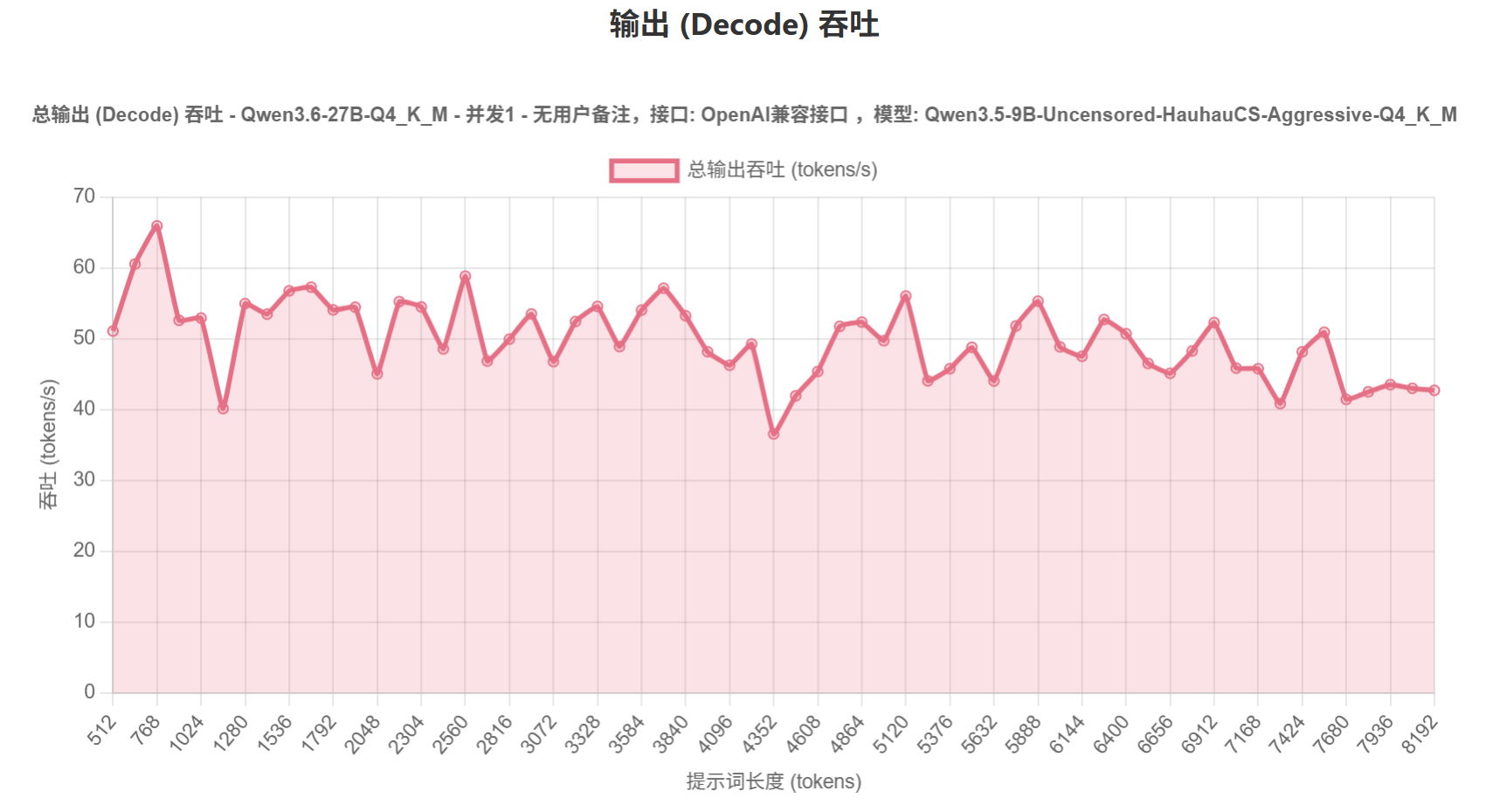
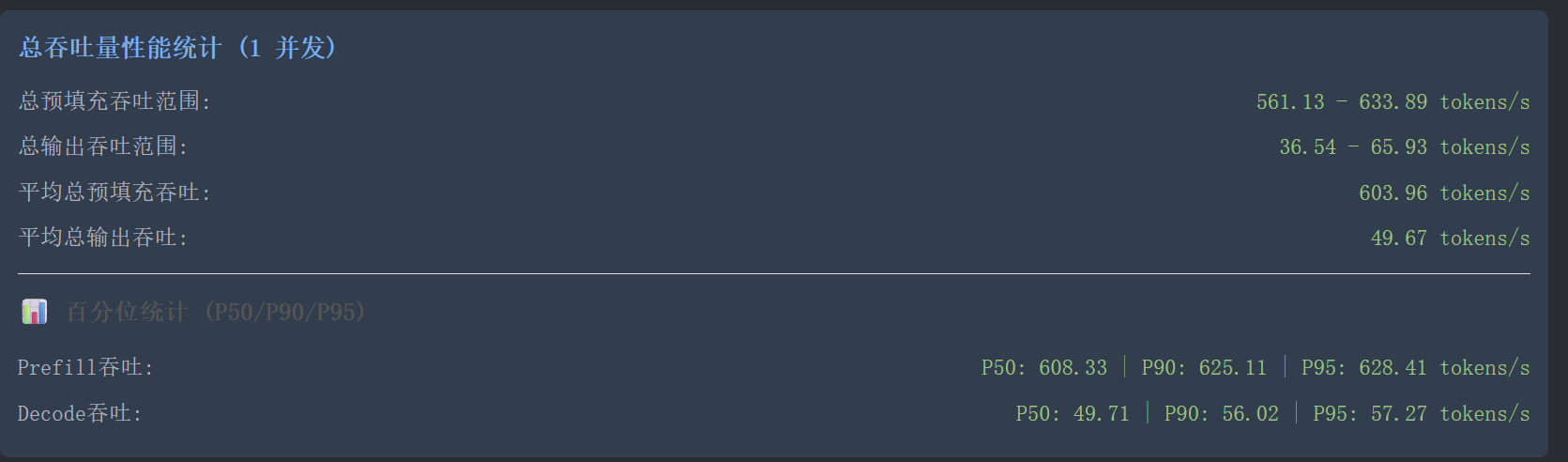
使用llama.cpp的vulkan后端,配合最新整合mtp的主线编译+mtp专用的量化模型。跑出的成绩还行吧。预填充500-600tk/s,输出有36-65tk/s。上下文我只拉到128k,显存占用不到21个G。
接入到claud code后,实际用起来比预期还好一点。果然预填充速度才是最重要的,如果当初买r9700,可能要差一截 -
@terry
拿到手了。一开始用的是linux,一通环境全部装好了,什么rocm、vulkan乱七八糟的。本来挺顺的,但后来跑comfyui后却莫名卡死了,然后就不认驱动了 。怎么反复重装都没用,就算恢复到最开始的系统快照也是这样,莫名其妙!想一想,还是装回windows好了。。。
使用llama.cpp的vulkan后端,配合最新整合mtp的主线编译+mtp专用的量化模型。跑出的成绩还行吧。预填充500-600tk/s,输出有36-65tk/s。上下文我只拉到128k,显存占用不到21个G。
接入到claud code后,实际用起来比预期还好一点。果然预填充速度才是最重要的,如果当初买r9700,可能要差一截 -
@bin-flamebox 你Linux有什么问题?脚本去下载AMD官方的一键安装脚本,问Gemini,和它说清楚,肯定没问题的。
@terry 一开始没有问题,啥都装好了,跑llm一切正常。就是跑了个comfyui后不认驱动了。。。
之前测试过,如果跑llm的话,现在vulkan比rocm好太多了。
现在还是觉得装回windows方便不少,性能基本差不了多少,关键我不是24小时开机使用,偶尔直接玩玩游戏,win更合适
现在comfyui有windows桌面版一键直装了,直接内置装好rocm需要的python虚拟环境,比自己github clone方便很多了 -
系统 取消固定了该主题