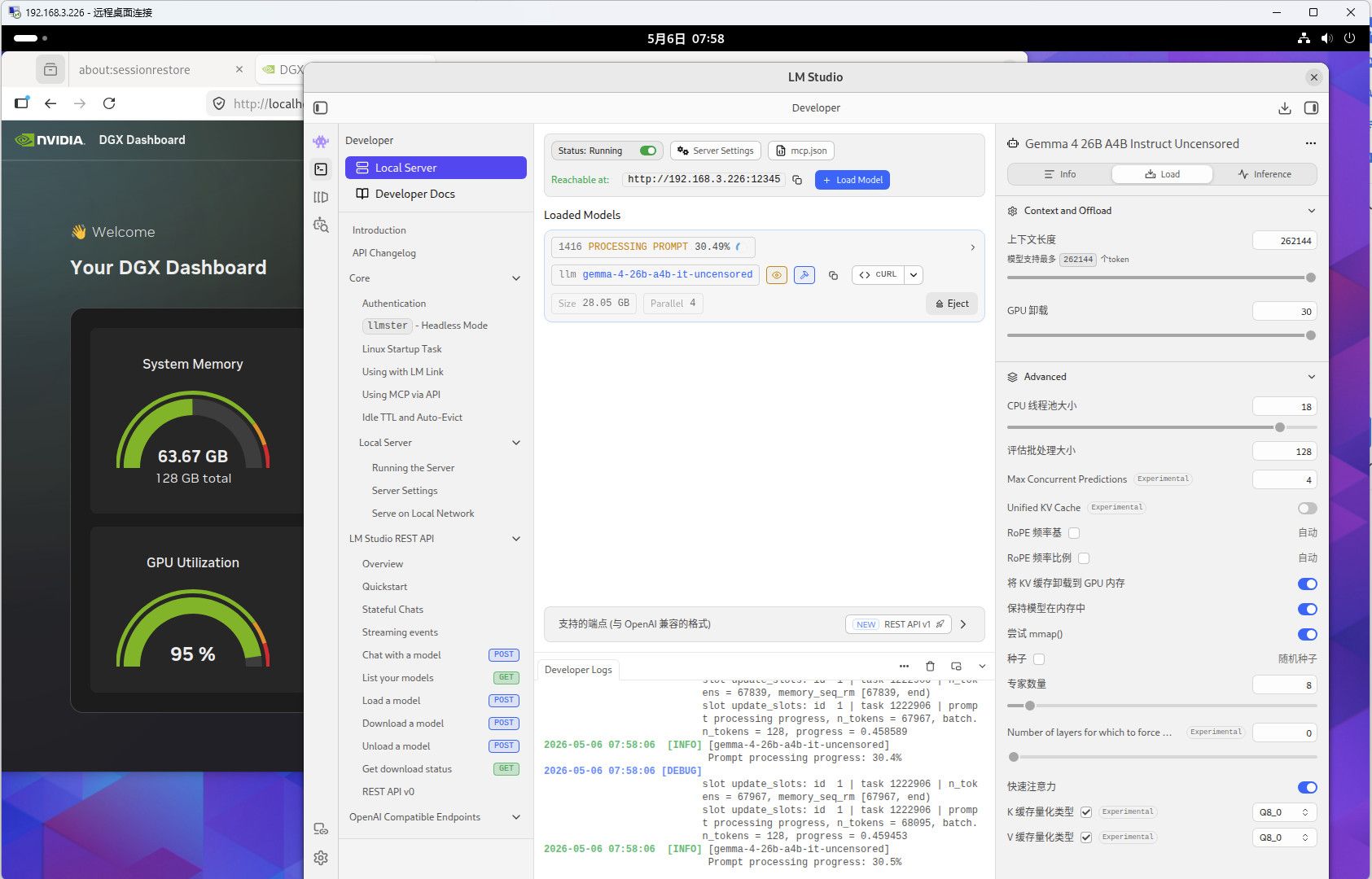
搞机Nvidia DGX Spark(128G 4T),累
-
@benton-yi
 好的,谢谢哥们。
好的,谢谢哥们。 -
剛折騰完nvidia thor128g
ollama在此環境不太友善
升級jetson 7.1之後,跑llama.cpp
使用nvfp4模型,跑起來飛快
大概比q4量化的快30%
測試完了
qwen3.6:35b moe約50 token/s
qwen3.6:27b dense約12 token/s
llama.cpp跑nvfp4還是比較適合這個平台
比起ollama int4量化同模型,快了30%左右之前ollama
qwen3.6:35b q4約35token/s
qwen3.6:27b q4約 9token/snvidia社群是說 nvfp4比mxfp4更適合在這台跑
目前順跑hermes串whatsapp
-
剛折騰完nvidia thor128g
ollama在此環境不太友善
升級jetson 7.1之後,跑llama.cpp
使用nvfp4模型,跑起來飛快
大概比q4量化的快30%
測試完了
qwen3.6:35b moe約50 token/s
qwen3.6:27b dense約12 token/s
llama.cpp跑nvfp4還是比較適合這個平台
比起ollama int4量化同模型,快了30%左右之前ollama
qwen3.6:35b q4約35token/s
qwen3.6:27b q4約 9token/snvidia社群是說 nvfp4比mxfp4更適合在這台跑
目前順跑hermes串whatsapp