关于INTEL 的B70 PRO。
-
想请教一下,所谓的适配一塌糊涂,是完全跑不起来还是说跑起来很慢,或者说很多节点不能用?
@t68823878 可以看到intel官方对于 AIGC的前景还是看好的,他们有一个团队去做这方面的技术支持,在comfyui的官方有了一个新的版本的comfyui去支持INTEL的卡。 这是其1. 2 是在不同的模型适配上, wan/ltx2.3这些都OK了。有些LORA我还没试,可能有些弱, 至于视频放大和一些用到cuda 和 nv gpu 的这些插件/custom node 就不要想了,虽然有些有 xpu 的支持,但性能还是有不少欠缺的。
他们官方为了解决入手门槛的问题,也紧急制作了docker 来让客户一键安装,但‘成也萧何败也萧何’ docker 的封闭性让 comfyui 的版本升级、pip配套环境的升级、git网络的使用都各种问题。
我已经建议他们将 comfyui 目录完全给映射到本地了。但现在的还是用起来极度别扭,一旦更新costom node 版本不对 整个docker就崩溃,当然,这更多是我的问题。 我尝试着去部署刘悦的这几个流,部署4天了。还没成功。等成功后我来给大家汇报它的效率以及1、2、3甚至4张卡的联合使用的效率。
同时也会根据老特他儿子的建议去跑一下Qwen3.6-27B ,他的建议是Qwen3.6-27B IQ4_K_M,我还没更多去看这几个的区别。 但据他们官方说,这卡用 vllm 部署起来效率更高,请各位等我消息。
-
@t68823878 可以看到intel官方对于 AIGC的前景还是看好的,他们有一个团队去做这方面的技术支持,在comfyui的官方有了一个新的版本的comfyui去支持INTEL的卡。 这是其1. 2 是在不同的模型适配上, wan/ltx2.3这些都OK了。有些LORA我还没试,可能有些弱, 至于视频放大和一些用到cuda 和 nv gpu 的这些插件/custom node 就不要想了,虽然有些有 xpu 的支持,但性能还是有不少欠缺的。
他们官方为了解决入手门槛的问题,也紧急制作了docker 来让客户一键安装,但‘成也萧何败也萧何’ docker 的封闭性让 comfyui 的版本升级、pip配套环境的升级、git网络的使用都各种问题。
我已经建议他们将 comfyui 目录完全给映射到本地了。但现在的还是用起来极度别扭,一旦更新costom node 版本不对 整个docker就崩溃,当然,这更多是我的问题。 我尝试着去部署刘悦的这几个流,部署4天了。还没成功。等成功后我来给大家汇报它的效率以及1、2、3甚至4张卡的联合使用的效率。
同时也会根据老特他儿子的建议去跑一下Qwen3.6-27B ,他的建议是Qwen3.6-27B IQ4_K_M,我还没更多去看这几个的区别。 但据他们官方说,这卡用 vllm 部署起来效率更高,请各位等我消息。
我已经建议他们将 comfyui 目录完全给映射到本地了。但现在的还是用起来极度别扭,一旦更新costom node 版本不对 整个docker就崩溃,当然,这更多是我的问题。 我尝试着去部署刘悦的这几个流,部署4天了。还没成功。等成功后我来给大家汇报它的效率以及1、2、3甚至4张卡的联合使用的效率。
同时也会根据老特他儿子的建议去跑一下Qwen3.6-27B ,他的建议是Qwen3.6-27B IQ4_K_M,我还没更多去看这几个的区别。 但据他们官方说,这卡用 vllm 部署起来效率更高,请各位等我消息。
你还能给英特尔官方提建议?面子这么大吗?

-
-
@terry 不装逼,不想挨骂,应该说不是给人家建议,应该说给人家反馈吧。 哇哈哈哈。 一帮技术人员,对comfyui 对工作室对最终用户的流,对破限的这些不够‘落地’是可以理解的。
-
只是认识而已,每个技术公司的产品出来都会找一堆我们这种有些关系的公司去测试去调整。和机会啥的没关系。别想多了,很纯洁的合作关系!哇哈哈哈哈。
从大概5.1 拿到之后,comfyui 崩了不下20回了。我都快没信心去玩了。认真的头疼....
-
@terry 因为驱动程序/comfyui版本等问题,所以只能用docker来驱动comfyui。这就有挺恶心的问题:
- 不能升级comfyui版本--除非手动打补丁,而且还不一定可以搞定。
- 更新costum node 各种卡死。这个和我的系统关系比较大。
- 更新系统配套的环境,pip 起来也特别麻烦。
- 因为cuda的原因,所以好多的有cuda的流只可以转到xpa或者CPU上。这就有了更多其它的问题。
现在官方优先适配 wan/ltx 这些在comfyui 官方版本里的官方的流,但那些流都是’基础流‘没有优化的。 我试了锤哥推荐的刘悦的流、B站黑鹤的流、程序员萝卜、流光、原上咩等大佬比较新的流,基本上都没办法完善的运行。所以需要调节的还是很多的,甚至不如锤哥说的AMD的环境,这挺让人费劲。
但vllm 这个可能比较简单。我还在搞N卡的comfyui环境。搞好第一时间来发帖。
-
https://github.com/intel/llm-scaler/tree/main
这是INTEL 官方公开的支持 B50/60/70 系列显卡的 comfyui 的docker 地址。他们还是做了不少适配的。下边有表:
https://github.com/intel/llm-scaler/tree/main#supported-models
Model Name FP16 Dynamic Online FP8 Dynamic Online Int4 MXFP4 Notes
openai/gpt-oss-20b
openai/gpt-oss-120b
deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
deepseek-ai/DeepSeek-R1-Distill-Llama-8B
deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
deepseek-ai/DeepSeek-R1-Distill-Llama-70B
deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
deepseek-ai/DeepSeek-V2-Lite export VLLM_MLA_DISABLE=1
deepseek-ai/deepseek-coder-33b-instruct
Qwen/Qwen3-8B
Qwen/Qwen3-14B
Qwen/Qwen3-32B
Qwen/Qwen3-30B-A3B
Qwen/Qwen3-235B-A22B
Qwen/Qwen3-Coder-30B-A3B-Instruct
Qwen/Qwen3-Coder-Next
Qwen/Qwen3.5-27B
Qwen/Qwen3.5-35B-A3B
Qwen/Qwen3.5-122B-A10B
Qwen/QwQ-32B
mistralai/Ministral-8B-Instruct-2410
mistralai/Mixtral-8x7B-Instruct-v0.1
meta-llama/Llama-3.1-8B
meta-llama/Llama-3.1-70B
baichuan-inc/Baichuan2-7B-Chat with chat_template
baichuan-inc/Baichuan2-13B-Chat with chat_template
THUDM/CodeGeex4-All-9B with chat_template
zai-org/GLM-4-9B-0414 use bfloat16
zai-org/GLM-4-32B-0414 use bfloat16
zai-org/GLM-4.5-Air
zai-org/GLM-4.7-Flash
ByteDance-Seed/Seed-OSS-36B-Instruct
miromind-ai/MiroThinker-v1.5-30B
tencent/Hunyuan-0.5B-Instruct follow the guide in here
tencent/Hunyuan-7B-Instruct follow the guide in here
Qwen/Qwen2-VL-7B-Instruct
Qwen/Qwen2.5-VL-7B-Instruct
Qwen/Qwen2.5-VL-32B-Instruct
Qwen/Qwen2.5-VL-72B-Instruct
Qwen/Qwen3-VL-4B-Instruct
Qwen/Qwen3-VL-8B-Instruct
Qwen/Qwen3-VL-30B-A3B-Instruct
openbmb/MiniCPM-V-2_6
openbmb/MiniCPM-V-4
openbmb/MiniCPM-V-4_5
OpenGVLab/InternVL2-8B
OpenGVLab/InternVL3-8B
OpenGVLab/InternVL3_5-8B
OpenGVLab/InternVL3_5-30B-A3B
rednote-hilab/dots.ocr
ByteDance-Seed/UI-TARS-7B-DPO
google/gemma-3-12b-it use bfloat16
google/gemma-3-27b-it use bfloat16
THUDM/GLM-4v-9B with --hf-overrides and chat_template
zai-org/GLM-4.1V-9B-Base
zai-org/GLM-4.1V-9B-Thinking
zai-org/Glyph
opendatalab/MinerU2.5-2509-1.2B
baidu/ERNIE-4.5-VL-28B-A3B-Thinking
zai-org/GLM-4.6V-Flash pip install transformers==5.0.0rc0 first
PaddlePaddle/PaddleOCR-VL follow the guide in here
deepseek-ai/DeepSeek-OCR
deepseek-ai/DeepSeek-OCR-2 There may be accuracy issues when using --quantization fp8
moonshotai/Kimi-VL-A3B-Thinking-2506
Qwen/Qwen2.5-Omni-7B
Qwen/Qwen3-Omni-30B-A3B-Instruct
openai/whisper-medium
openai/whisper-large-v3
Qwen/Qwen3-Embedding-8B
Qwen3-VL-Embedding-2B/8B follow the guide in here
BAAI/bge-m3
BAAI/bge-large-en-v1.5
Qwen/Qwen3-Reranker-8B
Qwen3-VL-Reranker-2B/8B follow the guide in here
BAAI/bge-reranker-large
BAAI/bge-reranker-v2-m3 -
https://github.com/intel/llm-scaler/tree/main
这是INTEL 官方公开的支持 B50/60/70 系列显卡的 comfyui 的docker 地址。他们还是做了不少适配的。下边有表:
https://github.com/intel/llm-scaler/tree/main#supported-models
Model Name FP16 Dynamic Online FP8 Dynamic Online Int4 MXFP4 Notes
openai/gpt-oss-20b
openai/gpt-oss-120b
deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
deepseek-ai/DeepSeek-R1-Distill-Llama-8B
deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
deepseek-ai/DeepSeek-R1-Distill-Llama-70B
deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
deepseek-ai/DeepSeek-V2-Lite export VLLM_MLA_DISABLE=1
deepseek-ai/deepseek-coder-33b-instruct
Qwen/Qwen3-8B
Qwen/Qwen3-14B
Qwen/Qwen3-32B
Qwen/Qwen3-30B-A3B
Qwen/Qwen3-235B-A22B
Qwen/Qwen3-Coder-30B-A3B-Instruct
Qwen/Qwen3-Coder-Next
Qwen/Qwen3.5-27B
Qwen/Qwen3.5-35B-A3B
Qwen/Qwen3.5-122B-A10B
Qwen/QwQ-32B
mistralai/Ministral-8B-Instruct-2410
mistralai/Mixtral-8x7B-Instruct-v0.1
meta-llama/Llama-3.1-8B
meta-llama/Llama-3.1-70B
baichuan-inc/Baichuan2-7B-Chat with chat_template
baichuan-inc/Baichuan2-13B-Chat with chat_template
THUDM/CodeGeex4-All-9B with chat_template
zai-org/GLM-4-9B-0414 use bfloat16
zai-org/GLM-4-32B-0414 use bfloat16
zai-org/GLM-4.5-Air
zai-org/GLM-4.7-Flash
ByteDance-Seed/Seed-OSS-36B-Instruct
miromind-ai/MiroThinker-v1.5-30B
tencent/Hunyuan-0.5B-Instruct follow the guide in here
tencent/Hunyuan-7B-Instruct follow the guide in here
Qwen/Qwen2-VL-7B-Instruct
Qwen/Qwen2.5-VL-7B-Instruct
Qwen/Qwen2.5-VL-32B-Instruct
Qwen/Qwen2.5-VL-72B-Instruct
Qwen/Qwen3-VL-4B-Instruct
Qwen/Qwen3-VL-8B-Instruct
Qwen/Qwen3-VL-30B-A3B-Instruct
openbmb/MiniCPM-V-2_6
openbmb/MiniCPM-V-4
openbmb/MiniCPM-V-4_5
OpenGVLab/InternVL2-8B
OpenGVLab/InternVL3-8B
OpenGVLab/InternVL3_5-8B
OpenGVLab/InternVL3_5-30B-A3B
rednote-hilab/dots.ocr
ByteDance-Seed/UI-TARS-7B-DPO
google/gemma-3-12b-it use bfloat16
google/gemma-3-27b-it use bfloat16
THUDM/GLM-4v-9B with --hf-overrides and chat_template
zai-org/GLM-4.1V-9B-Base
zai-org/GLM-4.1V-9B-Thinking
zai-org/Glyph
opendatalab/MinerU2.5-2509-1.2B
baidu/ERNIE-4.5-VL-28B-A3B-Thinking
zai-org/GLM-4.6V-Flash pip install transformers==5.0.0rc0 first
PaddlePaddle/PaddleOCR-VL follow the guide in here
deepseek-ai/DeepSeek-OCR
deepseek-ai/DeepSeek-OCR-2 There may be accuracy issues when using --quantization fp8
moonshotai/Kimi-VL-A3B-Thinking-2506
Qwen/Qwen2.5-Omni-7B
Qwen/Qwen3-Omni-30B-A3B-Instruct
openai/whisper-medium
openai/whisper-large-v3
Qwen/Qwen3-Embedding-8B
Qwen3-VL-Embedding-2B/8B follow the guide in here
BAAI/bge-m3
BAAI/bge-large-en-v1.5
Qwen/Qwen3-Reranker-8B
Qwen3-VL-Reranker-2B/8B follow the guide in here
BAAI/bge-reranker-large
BAAI/bge-reranker-v2-m3 -
@terry 看怎么看了吧。 如果 文生图、文生视频、图生视频、 文生语音、图片反推、视频反推这几个都有相对较好的解决方案。INTEL的卡内存大,省电,最重要的还便宜的话。老大你是否觉得有够买欲望? 比如说32G的这个内存在1W块左右。
O。这个单张卡最高290瓦的电。
-
@sirwang 我1万块为什么不买AI Pro R9700,我不需要研究任何东西,直接弄回来就能跑,说实话,我宁可多花点钱上4080S 32G,其实我也折腾xtx,纯粹是因为想弄点素材,但是没想到这卡是真好用。
-
系统 于 取消固定此主题
-
OK。回来汇报来了。 四张卡都驱起来了。机器有256G内存,一张卡分64G。 前三张运行comfyui。后一张运行qwen3.6-27B. 测试大模型压力用的4并发。 脚本和结果如下:
import urllib.request import json import concurrent.futures import time URL = "http://127.0.0.1:8091/v1/chat/completions" HEADERS = {"Content-Type": "application/json"} # 模拟长文本生成请求 DATA = { "model": "/model", "messages": [{"role": "user", "content": "请写一篇800字的科幻小说,描述人类第一次登陆木星的场景。"}], "max_tokens": 1000, "temperature": 0.8 } def send_request(req_id): req = urllib.request.Request(URL, headers=HEADERS, data=json.dumps(DATA).encode('utf-8')) start_time = time.time() try: with urllib.request.urlopen(req) as response: res = json.loads(response.read().decode('utf-8')) tokens = res['usage']['completion_tokens'] cost_time = time.time() - start_time print(f"请求 {req_id} 完成 | 耗时: {cost_time:.2f}s | 生成 Token: {tokens} | 速度: {tokens/cost_time:.2f} tokens/s") except Exception as e: print(f"请求 {req_id} 失败: {e}") # 设置并发数,从 2 开始,逐步改成 4, 8, 16 试试极限 CONCURRENCY = 4 print(f"--- 开始 vLLM 并发压测 | 并发数: {CONCURRENCY} ---") with concurrent.futures.ThreadPoolExecutor(max_workers=CONCURRENCY) as executor: # 一次性发射 20 个请求排队 executor.map(send_request, range(20))以下是运行截图:
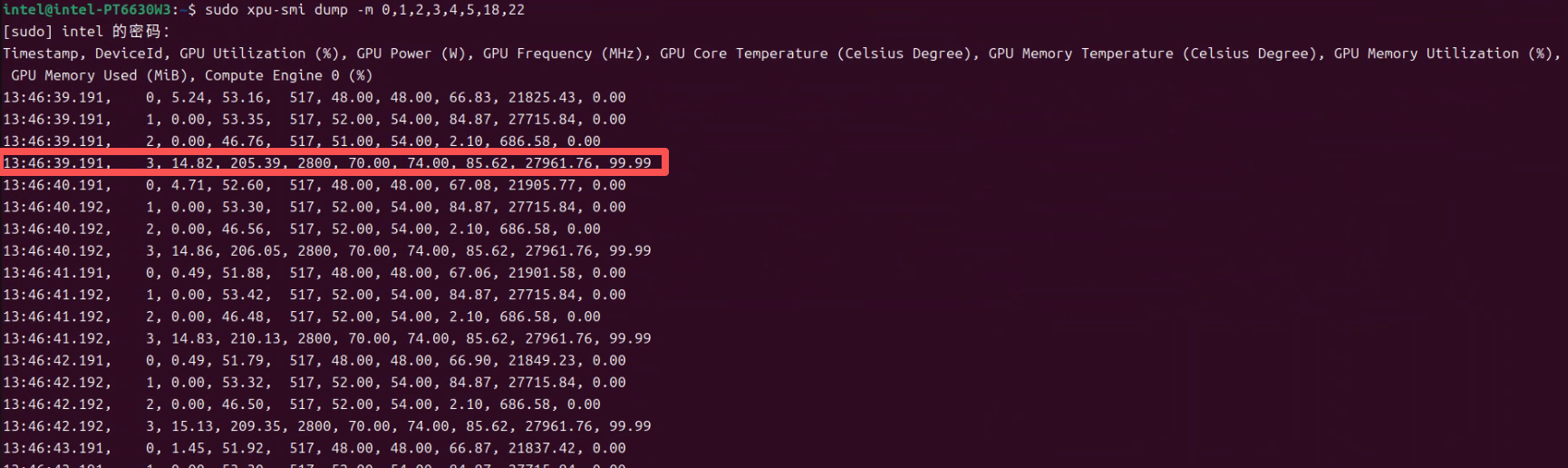
我画红线的是第4张卡运行vllm qwen3.6-27b的卡。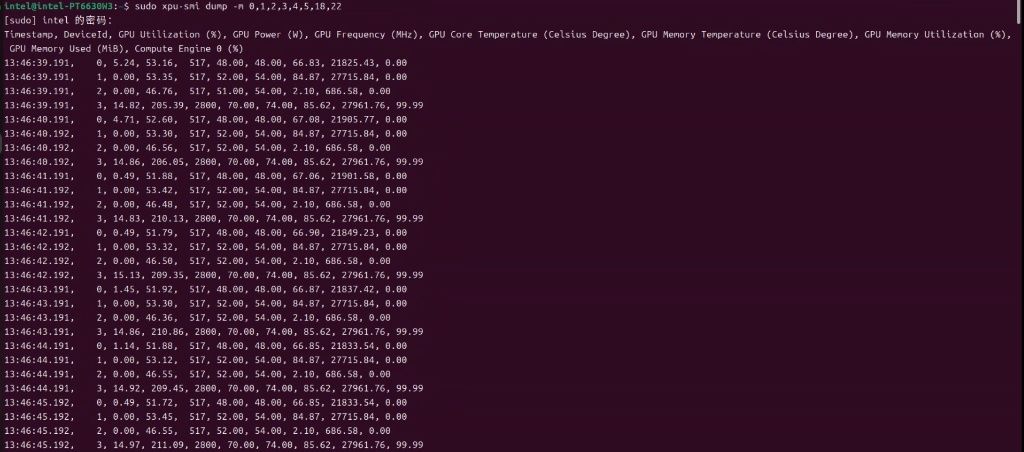
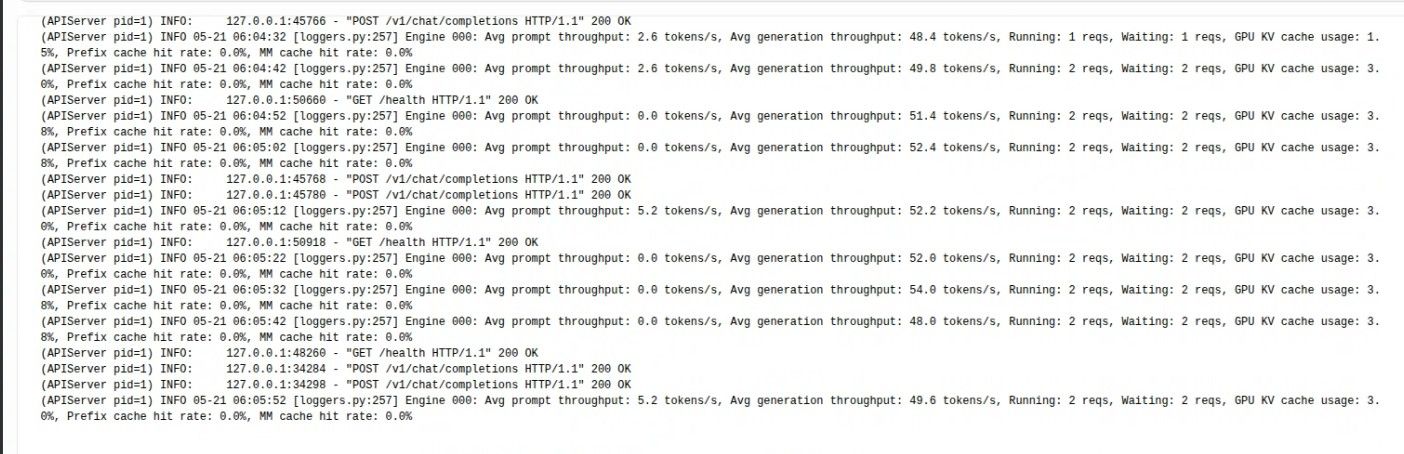 下边白底的这个是docker 的日志截图。
下边白底的这个是docker 的日志截图。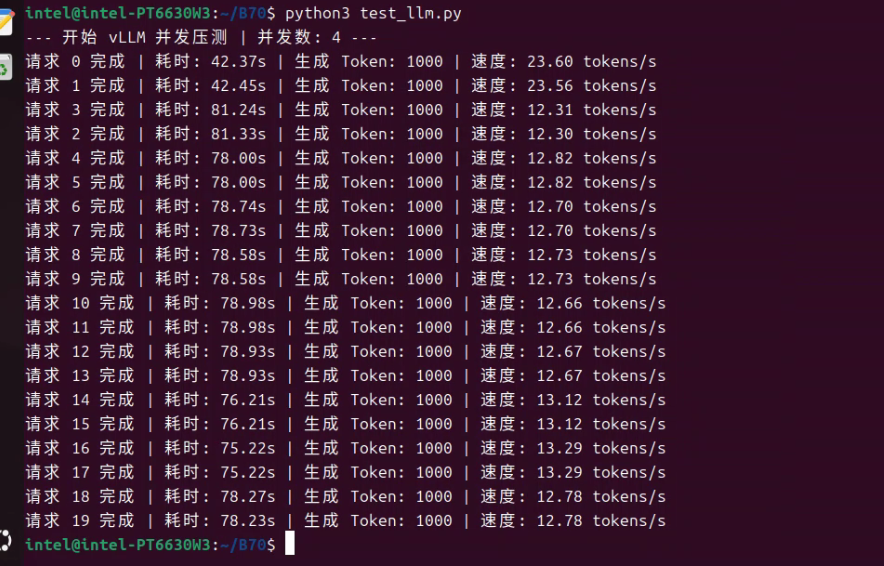 感觉还是相当稳的。 工作室和个人用,够了。 comfyui 我去找个‘公平’的测试方法。或者大家有啥测试方法不?
感觉还是相当稳的。 工作室和个人用,够了。 comfyui 我去找个‘公平’的测试方法。或者大家有啥测试方法不? -
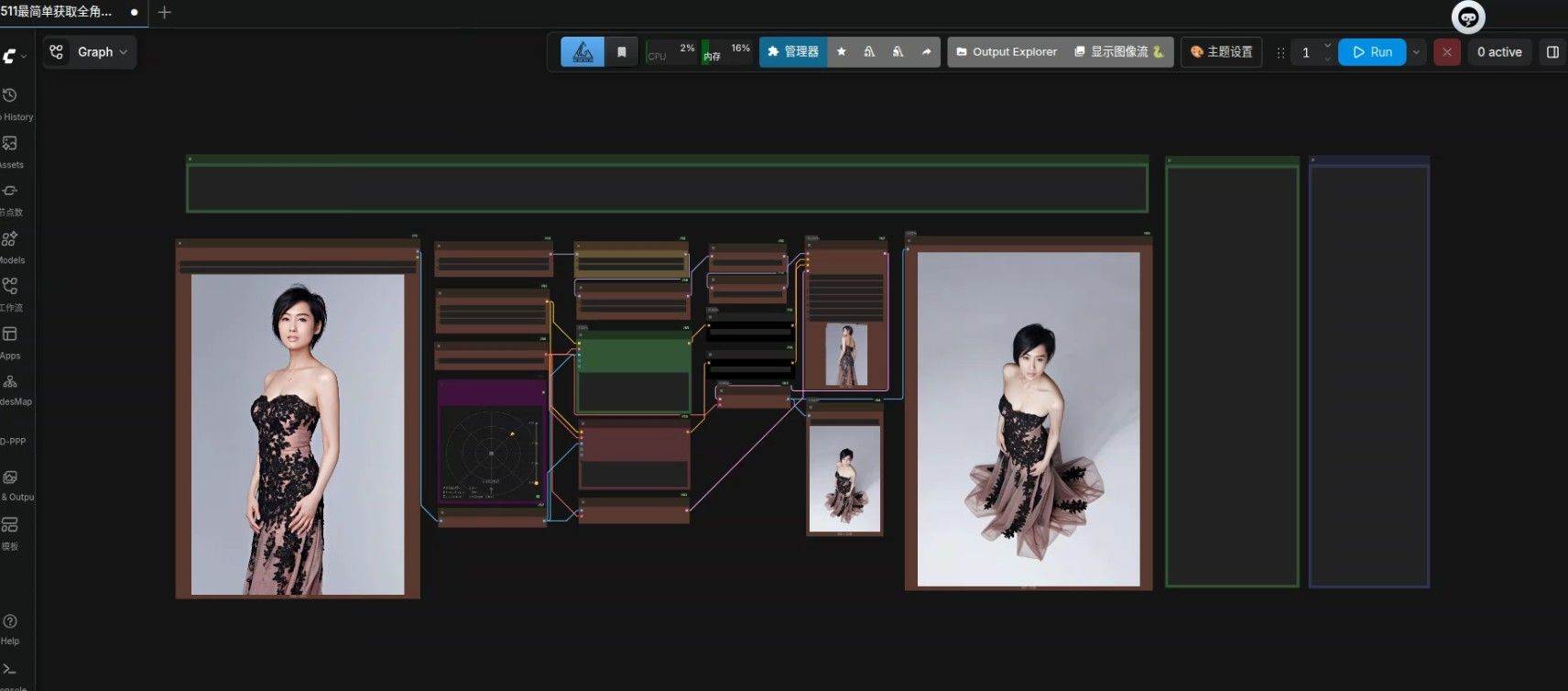
为了方便大家测试,我把流共享出来:
{ "id": "803716fc-9d9d-4d02-817c-855cdd6b4855", "revision": 0, "last_node_id": 27, "last_link_id": 30, "nodes": [ { "id": 2, "type": "FluxKontextMultiReferenceLatentMethod", "pos": [ 797.1906256982577, 12.11786329545784 ], "size": [ 309.6734375, 70 ], "flags": {}, "order": 15, "mode": 0, "inputs": [ { "label": "条件", "name": "conditioning", "type": "CONDITIONING", "link": 2 }, { "label": "参考Latent方法", "name": "reference_latents_method", "type": "COMBO", "widget": { "name": "reference_latents_method" }, "link": null } ], "outputs": [ { "label": "条件", "name": "CONDITIONING", "type": "CONDITIONING", "links": [ 13 ] } ], "properties": { "cnr_id": "comfy-core", "ver": "0.5.1", "Node name for S&R": "FluxKontextMultiReferenceLatentMethod", "ue_properties": { "widget_ue_connectable": { "reference_latents_method": true }, "version": "7.5.2", "input_ue_unconnectable": {} }, "enableTabs": false, "tabWidth": 65, "tabXOffset": 10, "hasSecondTab": false, "secondTabText": "Send Back", "secondTabOffset": 80, "secondTabWidth": 65 }, "widgets_values": [ "index_timestep_zero" ], "color": "#222", "bgcolor": "#000" }, { "id": 3, "type": "FluxKontextMultiReferenceLatentMethod", "pos": [ 797.1906256982577, -117.88213670454216 ], "size": [ 309.6734375, 70 ], "flags": {}, "order": 16, "mode": 0, "inputs": [ { "label": "条件", "name": "conditioning", "type": "CONDITIONING", "link": 3 }, { "label": "参考Latent方法", "name": "reference_latents_method", "type": "COMBO", "widget": { "name": "reference_latents_method" }, "link": null } ], "outputs": [ { "label": "条件", "name": "CONDITIONING", "type": "CONDITIONING", "links": [ 12 ] } ], "properties": { "cnr_id": "comfy-core", "ver": "0.5.1", "Node name for S&R": "FluxKontextMultiReferenceLatentMethod", "ue_properties": { "widget_ue_connectable": { "reference_latents_method": true }, "version": "7.5.2", "input_ue_unconnectable": {} }, "enableTabs": false, "tabWidth": 65, "tabXOffset": 10, "hasSecondTab": false, "secondTabText": "Send Back", "secondTabOffset": 80, "secondTabWidth": 65 }, "widgets_values": [ "index_timestep_zero" ], "color": "#222", "bgcolor": "#000" }, { "id": 4, "type": "CFGNorm", "pos": [ 807.1906256982578, -247.88213670454212 ], "size": [ 270, 68.33333333333334 ], "flags": {}, "order": 17, "mode": 0, "inputs": [ { "label": "模型", "name": "model", "type": "MODEL", "link": 4 }, { "label": "强度", "name": "strength", "type": "FLOAT", "widget": { "name": "strength" }, "link": null } ], "outputs": [ { "label": "修正后的模型", "name": "patched_model", "type": "MODEL", "links": [ 11 ] } ], "properties": { "cnr_id": "comfy-core", "ver": "0.5.1", "Node name for S&R": "CFGNorm", "ue_properties": { "widget_ue_connectable": { "strength": true }, "version": "7.5.2", "input_ue_unconnectable": {} }, "enableTabs": false, "tabWidth": 65, "tabXOffset": 10, "hasSecondTab": false, "secondTabText": "Send Back", "secondTabOffset": 80, "secondTabWidth": 65, "ttNbgOverride": { "color": "#332922", "bgcolor": "#593930", "groupcolor": "#b06634" } }, "widgets_values": [ 1 ], "color": "#332922", "bgcolor": "#593930" }, { "id": 17, "type": "UNETLoader", "pos": [ -145.99967296522877, -365.28072730924794 ], "size": [ 412.4183876274179, 93.12632424766274 ], "flags": {}, "order": 0, "mode": 0, "inputs": [ { "label": "UNET名称", "name": "unet_name", "type": "COMBO", "widget": { "name": "unet_name" }, "link": null }, { "label": "剪枝类型", "name": "weight_dtype", "type": "COMBO", "widget": { "name": "weight_dtype" }, "link": null } ], "outputs": [ { "label": "模型", "name": "MODEL", "type": "MODEL", "slot_index": 0, "links": [ 23 ] } ], "properties": { "cnr_id": "comfy-core", "ver": "0.5.1", "Node name for S&R": "UNETLoader", "ue_properties": { "widget_ue_connectable": { "unet_name": true, "weight_dtype": true }, "version": "7.5.2", "input_ue_unconnectable": {} }, "models": [ { "name": "qwen_image_edit_2511_bf16.safetensors", "url": "https://huggingface.co/Comfy-Org/Qwen-Image-Edit_ComfyUI/resolve/main/split_files/diffusion_models/qwen_image_edit_2511_bf16.safetensors", "directory": "diffusion_models" } ], "enableTabs": false, "tabWidth": 65, "tabXOffset": 10, "hasSecondTab": false, "secondTabText": "Send Back", "secondTabOffset": 80, "secondTabWidth": 65, "ttNbgOverride": { "color": "#332922", "bgcolor": "#593930", "groupcolor": "#b06634" } }, "widgets_values": [ "qwen_image_edit_2511_fp8mixed.safetensors", "default" ], "color": "#332922", "bgcolor": "#593930" }, { "id": 16, "type": "LoraLoaderModelOnly", "pos": [ 339.08373304272516, -365.4385152699498 ], "size": [ 396.1328125, 96.66666666666667 ], "flags": {}, "order": 8, "mode": 0, "inputs": [ { "label": "模型", "name": "model", "type": "MODEL", "link": 23 }, { "label": "LoRA名称", "name": "lora_name", "type": "COMBO", "widget": { "name": "lora_name" }, "link": null }, { "label": "模型强度", "name": "strength_model", "type": "FLOAT", "widget": { "name": "strength_model" }, "link": null } ], "outputs": [ { "label": "模型", "name": "MODEL", "type": "MODEL", "links": [ 22 ] } ], "properties": { "cnr_id": "comfy-core", "ver": "0.5.1", "Node name for S&R": "LoraLoaderModelOnly", "ue_properties": { "widget_ue_connectable": { "lora_name": true, "strength_model": true }, "version": "7.5.2", "input_ue_unconnectable": {} }, "models": [ { "name": "Qwen-Image-Edit-2511-Lightning-4steps-V1.0-bf16.safetensors", "url": "https://huggingface.co/lightx2v/Qwen-Image-Edit-2511-Lightning/resolve/main/Qwen-Image-Edit-2511-Lightning-4steps-V1.0-bf16.safetensors", "directory": "loras" } ], "enableTabs": false, "tabWidth": 65, "tabXOffset": 10, "hasSecondTab": false, "secondTabText": "Send Back", "secondTabOffset": 80, "secondTabWidth": 65 }, "widgets_values": [ "角度切换(VNCSS)-qwen-image-edit-2511-multiple-angles-lora.safetensors", 1 ], "color": "#432", "bgcolor": "#653" }, { "id": 18, "type": "CLIPLoader", "pos": [ -142.2511206355773, -201.03371333749183 ], "size": [ 396.1328125, 125 ], "flags": {}, "order": 1, "mode": 0, "inputs": [ { "label": "CLIP名称", "name": "clip_name", "type": "COMBO", "widget": { "name": "clip_name" }, "link": null }, { "label": "类型", "name": "type", "type": "COMBO", "widget": { "name": "type" }, "link": null } ], "outputs": [ { "label": "CLIP", "name": "CLIP", "type": "CLIP", "links": [ 5, 18 ] } ], "properties": { "cnr_id": "comfy-core", "ver": "0.5.1", "Node name for S&R": "CLIPLoader", "ue_properties": { "widget_ue_connectable": { "clip_name": true, "type": true, "device": true }, "version": "7.5.2", "input_ue_unconnectable": {} }, "models": [ { "name": "qwen_2.5_vl_7b_fp8_scaled.safetensors", "url": "https://huggingface.co/Comfy-Org/HunyuanVideo_1.5_repackaged/resolve/main/split_files/text_encoders/qwen_2.5_vl_7b_fp8_scaled.safetensors", "directory": "text_encoders" } ], "enableTabs": false, "tabWidth": 65, "tabXOffset": 10, "hasSecondTab": false, "secondTabText": "Send Back", "secondTabOffset": 80, "secondTabWidth": 65, "ttNbgOverride": { "color": "#332922", "bgcolor": "#593930", "groupcolor": "#b06634" } }, "widgets_values": [ "qwen_2.5_vl_7b_fp8_scaled.safetensors", "qwen_image", "default" ], "color": "#332922", "bgcolor": "#593930" }, { "id": 14, "type": "VAELoader", "pos": [ -146.39059612263827, -17.514527994231976 ], "size": [ 396.1328125, 68.33333333333334 ], "flags": {}, "order": 2, "mode": 0, "inputs": [ { "label": "vae名称", "name": "vae_name", "type": "COMBO", "widget": { "name": "vae_name" }, "link": null } ], "outputs": [ { "name": "VAE", "type": "VAE", "slot_index": 0, "links": [ 6, 9, 16, 19 ] } ], "properties": { "cnr_id": "comfy-core", "ver": "0.5.1", "Node name for S&R": "VAELoader", "ue_properties": { "widget_ue_connectable": { "vae_name": true }, "version": "7.5.2", "input_ue_unconnectable": {} }, "models": [ { "name": "qwen_image_vae.safetensors", "url": "https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI/resolve/main/split_files/vae/qwen_image_vae.safetensors", "directory": "vae" } ], "enableTabs": false, "tabWidth": 65, "tabXOffset": 10, "hasSecondTab": false, "secondTabText": "Send Back", "secondTabOffset": 80, "secondTabWidth": 65, "ttNbgOverride": { "color": "#332922", "bgcolor": "#593930", "groupcolor": "#b06634" } }, "widgets_values": [ "qwen_image_vae.safetensors" ], "color": "#332922", "bgcolor": "#593930" }, { "id": 8, "type": "FluxKontextImageScale", "pos": [ -133.49182202879047, 560.4714628108627 ], "size": [ 377.0828198681851, 37.03860129882946 ], "flags": {}, "order": 9, "mode": 0, "inputs": [ { "label": "图像", "name": "image", "type": "IMAGE", "link": 10 } ], "outputs": [ { "label": "图像", "name": "IMAGE", "type": "IMAGE", "links": [ 7, 8, 20 ] } ], "properties": { "cnr_id": "comfy-core", "ver": "0.5.1", "Node name for S&R": "FluxKontextImageScale", "ue_properties": { "widget_ue_connectable": {}, "version": "7.5.2", "input_ue_unconnectable": {} }, "enableTabs": false, "tabWidth": 65, "tabXOffset": 10, "hasSecondTab": false, "secondTabText": "Send Back", "secondTabOffset": 80, "secondTabWidth": 65, "ttNbgOverride": { "color": "#332922", "bgcolor": "#593930", "groupcolor": "#b06634" } }, "widgets_values": [], "color": "#332922", "bgcolor": "#593930" }, { "id": 15, "type": "LoraLoaderModelOnly", "pos": [ 347.0952420840532, -220.09228397794982 ], "size": [ 396.1328125, 96.66666666666667 ], "flags": {}, "order": 10, "mode": 0, "inputs": [ { "label": "模型", "name": "model", "type": "MODEL", "link": 22 }, { "label": "LoRA名称", "name": "lora_name", "type": "COMBO", "widget": { "name": "lora_name" }, "link": null }, { "label": "模型强度", "name": "strength_model", "type": "FLOAT", "widget": { "name": "strength_model" }, "link": null } ], "outputs": [ { "label": "模型", "name": "MODEL", "type": "MODEL", "links": [ 1 ] } ], "properties": { "cnr_id": "comfy-core", "ver": "0.5.1", "Node name for S&R": "LoraLoaderModelOnly", "ue_properties": { "widget_ue_connectable": { "lora_name": true, "strength_model": true }, "version": "7.5.2", "input_ue_unconnectable": {} }, "models": [ { "name": "Qwen-Image-Edit-2511-Lightning-4steps-V1.0-bf16.safetensors", "url": "https://huggingface.co/lightx2v/Qwen-Image-Edit-2511-Lightning/resolve/main/Qwen-Image-Edit-2511-Lightning-4steps-V1.0-bf16.safetensors", "directory": "loras" } ], "enableTabs": false, "tabWidth": 65, "tabXOffset": 10, "hasSecondTab": false, "secondTabText": "Send Back", "secondTabOffset": 80, "secondTabWidth": 65, "ttNbgOverride": { "color": "#332922", "bgcolor": "#593930", "groupcolor": "#b06634" } }, "widgets_values": [ "Qwen-Image-Edit-2511-Lightning-4steps-V1.0-fp32.safetensors", 1 ], "color": "#332922", "bgcolor": "#593930" }, { "id": 5, "type": "TextEncodeQwenImageEditPlus", "pos": [ 354.4459050818072, 251.866217681473 ], "size": [ 388.2640212658655, 214.48069935058538 ], "flags": {}, "order": 11, "mode": 0, "inputs": [ { "label": "CLIP", "name": "clip", "type": "CLIP", "link": 5 }, { "label": "VAE", "name": "vae", "shape": 7, "type": "VAE", "link": 6 }, { "label": "图像1", "name": "image1", "shape": 7, "type": "IMAGE", "link": 7 }, { "label": "图像2", "name": "image2", "shape": 7, "type": "IMAGE", "link": null }, { "label": "图像3", "name": "image3", "shape": 7, "type": "IMAGE", "link": null }, { "label": "提示词", "name": "prompt", "type": "STRING", "widget": { "name": "prompt" }, "link": null } ], "outputs": [ { "label": "条件", "name": "CONDITIONING", "type": "CONDITIONING", "links": [ 2 ] } ], "properties": { "cnr_id": "comfy-core", "ver": "0.5.1", "Node name for S&R": "TextEncodeQwenImageEditPlus", "ue_properties": { "widget_ue_connectable": { "prompt": true }, "version": "7.5.2", "input_ue_unconnectable": {} }, "enableTabs": false, "tabWidth": 65, "tabXOffset": 10, "hasSecondTab": false, "secondTabText": "Send Back", "secondTabOffset": 80, "secondTabWidth": 65 }, "widgets_values": [ "" ], "color": "#322", "bgcolor": "#533" }, { "id": 7, "type": "VAEEncode", "pos": [ 354.7124804040489, 524.2547847261422 ], "size": [ 384.81499821657553, 60 ], "flags": {}, "order": 12, "mode": 0, "inputs": [ { "label": "图像", "name": "pixels", "type": "IMAGE", "link": 8 }, { "label": "VAE", "name": "vae", "type": "VAE", "link": 9 } ], "outputs": [ { "label": "Latent", "name": "LATENT", "type": "LATENT", "links": [ 14 ] } ], "properties": { "cnr_id": "comfy-core", "ver": "0.5.1", "Node name for S&R": "VAEEncode", "ue_properties": { "widget_ue_connectable": {}, "version": "7.5.2", "input_ue_unconnectable": {} }, "enableTabs": false, "tabWidth": 65, "tabXOffset": 10, "hasSecondTab": false, "secondTabText": "Send Back", "secondTabOffset": 80, "secondTabWidth": 65, "ttNbgOverride": { "color": "#332922", "bgcolor": "#593930", "groupcolor": "#b06634" } }, "widgets_values": [], "color": "#332922", "bgcolor": "#593930" }, { "id": 1, "type": "ModelSamplingAuraFlow", "pos": [ 807.1906256982578, -357.88213670454206 ], "size": [ 270, 68.33333333333334 ], "flags": {}, "order": 14, "mode": 0, "inputs": [ { "label": "模型", "name": "model", "type": "MODEL", "link": 1 }, { "label": "偏移", "name": "shift", "type": "FLOAT", "widget": { "name": "shift" }, "link": null } ], "outputs": [ { "label": "模型", "name": "MODEL", "type": "MODEL", "links": [ 4 ] } ], "properties": { "cnr_id": "comfy-core", "ver": "0.5.1", "Node name for S&R": "ModelSamplingAuraFlow", "ue_properties": { "widget_ue_connectable": { "shift": true }, "version": "7.5.2", "input_ue_unconnectable": {} }, "enableTabs": false, "tabWidth": 65, "tabXOffset": 10, "hasSecondTab": false, "secondTabText": "Send Back", "secondTabOffset": 80, "secondTabWidth": 65, "ttNbgOverride": { "color": "#332922", "bgcolor": "#593930", "groupcolor": "#b06634" } }, "widgets_values": [ 3.1 ], "color": "#332922", "bgcolor": "#593930" }, { "id": 9, "type": "KSampler", "pos": [ 1140.647653458271, -367.5409128410178 ], "size": [ 286.8991258117685, 486 ], "flags": {}, "order": 18, "mode": 0, "inputs": [ { "label": "模型", "name": "model", "type": "MODEL", "link": 11 }, { "label": "正面条件", "name": "positive", "type": "CONDITIONING", "link": 12 }, { "label": "负面条件", "name": "negative", "type": "CONDITIONING", "link": 13 }, { "label": "Latent", "name": "latent_image", "type": "LATENT", "link": 14 }, { "label": "随机种", "name": "seed", "type": "INT", "widget": { "name": "seed" }, "link": null }, { "label": "步数", "name": "steps", "type": "INT", "widget": { "name": "steps" }, "link": null }, { "label": "CFG", "name": "cfg", "type": "FLOAT", "widget": { "name": "cfg" }, "link": null }, { "label": "采样器", "name": "sampler_name", "type": "COMBO", "widget": { "name": "sampler_name" }, "link": null }, { "label": "调度器", "name": "scheduler", "type": "COMBO", "widget": { "name": "scheduler" }, "link": null }, { "label": "降噪", "name": "denoise", "type": "FLOAT", "widget": { "name": "denoise" }, "link": null } ], "outputs": [ { "label": "Latent", "name": "LATENT", "type": "LATENT", "links": [ 15 ] } ], "properties": { "cnr_id": "comfy-core", "ver": "0.5.1", "Node name for S&R": "KSampler", "ue_properties": { "widget_ue_connectable": { "seed": true, "steps": true, "cfg": true, "sampler_name": true, "scheduler": true, "denoise": true }, "version": "7.5.2", "input_ue_unconnectable": {} }, "enableTabs": false, "tabWidth": 65, "tabXOffset": 10, "hasSecondTab": false, "secondTabText": "Send Back", "secondTabOffset": 80, "secondTabWidth": 65, "ttNbgOverride": { "color": "#332922", "bgcolor": "#593930", "groupcolor": "#b06634" } }, "widgets_values": [ 173815537092855, "randomize", 4, 1, "euler", "simple", 1 ], "color": "#332922", "bgcolor": "#593930" }, { "id": 10, "type": "VAEDecode", "pos": [ 835.9280787755798, 137.81632044395135 ], "size": [ 255.0718204517343, 46 ], "flags": { "collapsed": false }, "order": 19, "mode": 0, "inputs": [ { "label": "Latent", "name": "samples", "type": "LATENT", "link": 15 }, { "label": "VAE", "name": "vae", "type": "VAE", "link": 16 } ], "outputs": [ { "label": "图像", "name": "IMAGE", "type": "IMAGE", "slot_index": 0, "links": [ 17, 29 ] } ], "properties": { "cnr_id": "comfy-core", "ver": "0.5.1", "Node name for S&R": "VAEDecode", "ue_properties": { "widget_ue_connectable": {}, "version": "7.5.2", "input_ue_unconnectable": {} }, "enableTabs": false, "tabWidth": 65, "tabXOffset": 10, "hasSecondTab": false, "secondTabText": "Send Back", "secondTabOffset": 80, "secondTabWidth": 65, "ttNbgOverride": { "color": "#332922", "bgcolor": "#593930", "groupcolor": "#b06634" } }, "widgets_values": [], "color": "#332922", "bgcolor": "#593930" },
貌似不行,那就再开一个贴再贴一半吧。 我没有权限上传文件,只能贴代码了。
-
请把俩代码合一块。就可以了。
{ "id": 26, "type": "SaveImage", "pos": [ 1145.1501729206636, 195.07454751045992 ], "size": [ 267.9266338657344, 433.279270302052 ], "flags": {}, "order": 21, "mode": 0, "inputs": [ { "label": "图像组", "name": "images", "type": "IMAGE", "link": 29 }, { "label": "文件名前缀", "name": "filename_prefix", "type": "STRING", "widget": { "name": "filename_prefix" }, "link": null } ], "outputs": [], "properties": { "cnr_id": "comfy-core", "ver": "0.6.0", "Node name for S&R": "SaveImage", "ue_properties": { "widget_ue_connectable": {}, "input_ue_unconnectable": {}, "version": "7.5.2" }, "ttNbgOverride": { "color": "#332922", "bgcolor": "#593930", "groupcolor": "#b06634" } }, "widgets_values": [ "ComfyUI" ], "color": "#332922", "bgcolor": "#593930" }, { "id": 11, "type": "PreviewImage", "pos": [ 1487.4226159090695, -382.86645688700804 ], "size": [ 861.0544444444449, 1199.7606666666666 ], "flags": {}, "order": 20, "mode": 0, "inputs": [ { "label": "图像组", "name": "images", "type": "IMAGE", "link": 17 } ], "outputs": [], "properties": { "cnr_id": "comfy-core", "ver": "0.6.0", "Node name for S&R": "PreviewImage", "ue_properties": { "widget_ue_connectable": {}, "version": "7.5.2", "input_ue_unconnectable": {} }, "ttNbgOverride": { "color": "#332922", "bgcolor": "#593930", "groupcolor": "#b06634" } }, "widgets_values": [], "color": "#332922", "bgcolor": "#593930" }, { "id": 25, "type": "Note", "pos": [ 2890.282933565041, -663.9119545246833 ], "size": [ 421.42547299979583, 1472.8439775316037 ], "flags": {}, "order": 3, "mode": 0, "inputs": [], "outputs": [], "properties": { "ue_properties": { "widget_ue_connectable": {}, "version": "7.5.2", "input_ue_unconnectable": {} } }, "widgets_values": [ "正面视图低角度特写:<sks> front view low-angle shot close-up\n\n右前侧视图低角度特写:<sks> front-right quarter view low-angle shot close-up\n\n右侧视图低角度特写:<sks> right side view low-angle shot close-up\n\n右后侧视图低角度特写:<sks> back-right quarter view low-angle shot close-up\n\n背面视图低角度特写:<sks> back view low-angle shot close-up\n\n左后侧视图低角度特写:<sks> back-left quarter view low-angle shot close-up\n\n左侧视图低角度特写:<sks> left side view low-angle shot close-up\n\n左前侧视图低角度特写:<sks> front-left quarter view low-angle shot close-up\n\n正面视图平视特写:<sks> front view eye-level shot close-up\n\n右前侧视图平视特写:<sks> front-right quarter view eye-level shot close-up\n\n右侧视图平视特写:<sks> right side view eye-level shot close-up\n\n右后侧视图平视特写:<sks> back-right quarter view eye-level shot close-up\n\n背面视图平视特写:<sks> back view eye-level shot close-up\n\n左后侧视图平视特写:<sks> back-left quarter view eye-level shot close-up\n\n左侧视图平视特写:<sks> left side view eye-level shot close-up\n\n左前侧视图平视特写:<sks> front-left quarter view eye-level shot close-up\n\n正面视图高位拍摄特写:<sks> front view elevated shot close-up\n\n右前侧视图高位拍摄特写:<sks> front-right quarter view elevated shot close-up\n\n右侧视图高位拍摄特写:<sks> right side view elevated shot close-up\n\n右后侧视图高位拍摄特写:<sks> back-right quarter view elevated shot close-up\n\n背面视图高位拍摄特写:<sks> back view elevated shot close-up\n\n左后侧视图高位拍摄特写:<sks> back-left quarter view elevated shot close-up\n\n左侧视图高位拍摄特写:<sks> left side view elevated shot close-up\n\n左前侧视图高位拍摄特写:<sks> front-left quarter view elevated shot close-up\n\n正面视图高角度特写:<sks> front view high-angle shot close-up\n\n右前侧视图高角度特写:<sks> front-right quarter view high-angle shot close-up\n\n右侧视图高角度特写:<sks> right side view high-angle shot close-up\n\n右后侧视图高角度特写:<sks> back-right quarter view high-angle shot close-up\n\n背面视图高角度特写:<sks> back view high-angle shot close-up\n\n左后侧视图高角度特写:<sks> back-left quarter view high-angle shot close-up\n\n左侧视图高角度特写:<sks> left side view high-angle shot close-up\n\n左前侧视图高角度特写:<sks> front-left quarter view high-angle shot close-up\n\n正面视图低角度中景:<sks> front view low-angle shot medium shot\n\n右前侧视图低角度中景:<sks> front-right quarter view low-angle shot medium shot\n\n右侧视图低角度中景:<sks> right side view low-angle shot medium shot\n\n右后侧视图低角度中景:<sks> back-right quarter view low-angle shot medium shot\n\n背面视图低角度中景:<sks> back view low-angle shot medium shot\n\n左后侧视图低角度中景:<sks> back-left quarter view low-angle shot medium shot\n\n左侧视图低角度中景:<sks> left side view low-angle shot medium shot\n\n左前侧视图低角度中景:<sks> front-left quarter view low-angle shot medium shot\n\n正面视图平视中景:<sks> front view eye-level shot medium shot\n\n右前侧视图平视中景:<sks> front-right quarter view eye-level shot medium shot\n\n右侧视图平视中景:<sks> right side view eye-level shot medium shot\n\n右后侧视图平视中景:<sks> back-right quarter view eye-level shot medium shot\n\n背面视图平视中景:<sks> back view eye-level shot medium shot\n\n左后侧视图平视中景:<sks> back-left quarter view eye-level shot medium shot\n\n左侧视图平视中景:<sks> left side view eye-level shot medium shot\n\n左前侧视图平视中景:<sks> front-left quarter view eye-level shot medium shot\n\n正面视图高位拍摄中景:<sks> front view elevated shot medium shot\n\n右前侧视图高位拍摄中景:<sks> front-right quarter view elevated shot medium shot\n\n右侧视图高位拍摄中景:<sks> right side view elevated shot medium shot\n\n右后侧视图高位拍摄中景:<sks> back-right quarter view elevated shot medium shot\n\n背面视图高位拍摄中景:<sks> back view elevated shot medium shot\n\n左后侧视图高位拍摄中景:<sks> back-left quarter view elevated shot medium shot\n\n左侧视图高位拍摄中景:<sks> left side view elevated shot medium shot\n\n左前侧视图高位拍摄中景:<sks> front-left quarter view elevated shot medium shot\n\n正面视图高角度中景:<sks> front view high-angle shot medium shot\n\n右前侧视图高角度中景:<sks> front-right quarter view high-angle shot medium shot\n\n右侧视图高角度中景:<sks> right side view high-angle shot medium shot\n\n右后侧视图高角度中景:<sks> back-right quarter view high-angle shot medium shot\n\n背面视图高角度中景:<sks> back view high-angle shot medium shot\n\n左后侧视图高角度中景:<sks> back-left quarter view high-angle shot medium shot\n\n左侧视图高角度中景:<sks> left side view high-angle shot medium shot\n\n左前侧视图高角度中景:<sks> front-left quarter view high-angle shot medium shot\n\n正面视图低角度广角:<sks> front view low-angle shot wide shot\n\n右前侧视图低角度广角:<sks> front-right quarter view low-angle shot wide shot\n\n右侧视图低角度广角:<sks> right side view low-angle shot wide shot\n\n右后侧视图低角度广角:<sks> back-right quarter view low-angle shot wide shot\n\n背面视图低角度广角:<sks> back view low-angle shot wide shot\n\n左后侧视图低角度广角:<sks> back-left quarter view low-angle shot wide shot\n\n左侧视图低角度广角:<sks> left side view low-angle shot wide shot\n\n左前侧视图低角度广角:<sks> front-left quarter view low-angle shot wide shot" ], "color": "#223", "bgcolor": "#335" }, { "id": 27, "type": "Note", "pos": [ -1009.7430949133999, -667.218084639018 ], "size": [ 3344.867777777771, 172.79096969696934 ], "flags": {}, "order": 4, "mode": 0, "inputs": [], "outputs": [], "properties": { "ue_properties": { "widget_ue_connectable": {}, "version": "7.8", "input_ue_unconnectable": {} } }, "widgets_values": [ "可以使用comfuyi-lumi-batcher 来跑各个角度的,一下子跑出去90条。\n在这个流里,直接换位置,也就是把位置选成节点19,之后把参数选成左边复制的提示信息就行. william" ], "color": "#232", "bgcolor": "#353" }, { "id": 20, "type": "Note", "pos": [ 2392.2425113410113, -661.9303860055464 ], "size": [ 466.503515625, 1468.5173727560402 ], "flags": {}, "order": 5, "mode": 0, "inputs": [], "outputs": [], "title": "All prompt possible for the Lora Qwen image edit multiple angles", "properties": { "ue_properties": { "widget_ue_connectable": {}, "version": "7.5.2", "input_ue_unconnectable": {} } }, "widgets_values": [ "<sks> front view low-angle shot close-up\n<sks> front-right quarter view low-angle shot close-up\n<sks> right side view low-angle shot close-up\n<sks> back-right quarter view low-angle shot close-up\n<sks> back view low-angle shot close-up\n<sks> back-left quarter view low-angle shot close-up\n<sks> left side view low-angle shot close-up\n<sks> front-left quarter view low-angle shot close-up\n<sks> front view eye-level shot close-up\n<sks> front-right quarter view eye-level shot close-up\n<sks> right side view eye-level shot close-up\n<sks> back-right quarter view eye-level shot close-up\n<sks> back view eye-level shot close-up\n<sks> back-left quarter view eye-level shot close-up\n<sks> left side view eye-level shot close-up\n<sks> front-left quarter view eye-level shot close-up\n<sks> front view elevated shot close-up\n<sks> front-right quarter view elevated shot close-up\n<sks> right side view elevated shot close-up\n<sks> back-right quarter view elevated shot close-up\n<sks> back view elevated shot close-up\n<sks> back-left quarter view elevated shot close-up\n<sks> left side view elevated shot close-up\n<sks> front-left quarter view elevated shot close-up\n<sks> front view high-angle shot close-up\n<sks> front-right quarter view high-angle shot close-up\n<sks> right side view high-angle shot close-up\n<sks> back-right quarter view high-angle shot close-up\n<sks> back view high-angle shot close-up\n<sks> back-left quarter view high-angle shot close-up\n<sks> left side view high-angle shot close-up\n<sks> front-left quarter view high-angle shot close-up\n<sks> front view low-angle shot medium shot\n<sks> front-right quarter view low-angle shot medium shot\n<sks> right side view low-angle shot medium shot\n<sks> back-right quarter view low-angle shot medium shot\n<sks> back view low-angle shot medium shot\n<sks> back-left quarter view low-angle shot medium shot\n<sks> left side view low-angle shot medium shot\n<sks> front-left quarter view low-angle shot medium shot\n<sks> front view eye-level shot medium shot\n<sks> front-right quarter view eye-level shot medium shot\n<sks> right side view eye-level shot medium shot\n<sks> back-right quarter view eye-level shot medium shot\n<sks> back view eye-level shot medium shot\n<sks> back-left quarter view eye-level shot medium shot\n<sks> left side view eye-level shot medium shot\n<sks> front-left quarter view eye-level shot medium shot\n<sks> front view elevated shot medium shot\n<sks> front-right quarter view elevated shot medium shot\n<sks> right side view elevated shot medium shot\n<sks> back-right quarter view elevated shot medium shot\n<sks> back view elevated shot medium shot\n<sks> back-left quarter view elevated shot medium shot\n<sks> left side view elevated shot medium shot\n<sks> front-left quarter view elevated shot medium shot\n<sks> front view high-angle shot medium shot\n<sks> front-right quarter view high-angle shot medium shot\n<sks> right side view high-angle shot medium shot\n<sks> back-right quarter view high-angle shot medium shot\n<sks> back view high-angle shot medium shot\n<sks> back-left quarter view high-angle shot medium shot\n<sks> left side view high-angle shot medium shot\n<sks> front-left quarter view high-angle shot medium shot\n<sks> front view low-angle shot wide shot\n<sks> front-right quarter view low-angle shot wide shot\n<sks> right side view low-angle shot wide shot\n<sks> back-right quarter view low-angle shot wide shot\n<sks> back view low-angle shot wide shot\n<sks> back-left quarter view low-angle shot wide shot\n<sks> left side view low-angle shot wide shot\n<sks> front-left quarter view low-angle shot wide shot\n<sks> front view eye-level shot wide shot\n<sks> front-right quarter view eye-level shot wide shot\n<sks> right side view eye-level shot wide shot\n<sks> back-right quarter view eye-level shot wide shot\n<sks> back view eye-level shot wide shot\n<sks> back-left quarter view eye-level shot wide shot\n<sks> left side view eye-level shot wide shot\n<sks> front-left quarter view eye-level shot wide shot\n<sks> front view elevated shot wide shot\n<sks> front-right quarter view elevated shot wide shot\n<sks> right side view elevated shot wide shot\n<sks> back-right quarter view elevated shot wide shot\n<sks> back view elevated shot wide shot\n<sks> back-left quarter view elevated shot wide shot\n<sks> left side view elevated shot wide shot\n<sks> front-left quarter view elevated shot wide shot\n<sks> front view high-angle shot wide shot\n<sks> front-right quarter view high-angle shot wide shot\n<sks> right side view high-angle shot wide shot\n<sks> back-right quarter view high-angle shot wide shot\n<sks> back view high-angle shot wide shot\n<sks> back-left quarter view high-angle shot wide shot\n<sks> left side view high-angle shot wide shot\n<sks> front-left quarter view high-angle shot wide shot" ], "color": "#232", "bgcolor": "#353" }, { "id": 13, "type": "TextEncodeQwenImageEditPlus", "pos": [ 346.3903358490907, -56.08507473664949 ], "size": [ 400.4109260819468, 258.660770021565 ], "flags": {}, "order": 13, "mode": 0, "inputs": [ { "label": "CLIP", "name": "clip", "type": "CLIP", "link": 18 }, { "label": "VAE", "name": "vae", "shape": 7, "type": "VAE", "link": 19 }, { "label": "图像1", "name": "image1", "shape": 7, "type": "IMAGE", "link": 20 }, { "label": "图像2", "name": "image2", "shape": 7, "type": "IMAGE", "link": null }, { "label": "图像3", "name": "image3", "shape": 7, "type": "IMAGE", "link": null }, { "label": "提示词", "name": "prompt", "type": "STRING", "widget": { "name": "prompt" }, "link": 30 } ], "outputs": [ { "label": "条件", "name": "CONDITIONING", "type": "CONDITIONING", "links": [ 3 ] } ], "title": "TextEncodeQwenImageEditPlus (Positive)", "properties": { "cnr_id": "comfy-core", "ver": "0.5.1", "Node name for S&R": "TextEncodeQwenImageEditPlus", "ue_properties": { "widget_ue_connectable": { "prompt": true }, "version": "7.5.2", "input_ue_unconnectable": {} }, "enableTabs": false, "tabWidth": 65, "tabXOffset": 10, "hasSecondTab": false, "secondTabText": "Send Back", "secondTabOffset": 80, "secondTabWidth": 65 }, "widgets_values": [ "<sks> front view low-angle shot close-up" ], "color": "#232", "bgcolor": "#353" }, { "id": 19, "type": "VNCCS_VisualPositionControl", "pos": [ -135.64643889289317, 113.93573315518134 ], "size": [ 377.25527938354924, 400.69737743530504 ], "flags": {}, "order": 6, "mode": 0, "inputs": [], "outputs": [ { "name": "prompt", "type": "STRING", "links": [ 30 ] } ], "properties": { "cnr_id": "vnccs-utils", "ver": "e8899e8fda5e72744198efecdc6f74f7d88a3b6a", "Node name for S&R": "VNCCS_VisualPositionControl", "ue_properties": { "widget_ue_connectable": { "camera_data": true }, "version": "7.5.2", "input_ue_unconnectable": {} }, "ttNbgOverride": { "color": "#332922", "bgcolor": "#593930", "groupcolor": "#b06634" } }, "widgets_values": [ "{\"azimuth\":225,\"elevation\":-30,\"distance\":\"close-up\",\"include_trigger\":true}", "" ], "color": "#332922", "bgcolor": "#593930" }, { "id": 12, "type": "LoadImage", "pos": [ -1045.7126666666695, -374.68955555555544 ], "size": [ 850, 1220 ], "flags": {}, "order": 7, "mode": 0, "inputs": [ { "label": "图像", "name": "image", "type": "COMBO", "widget": { "name": "image" }, "link": null }, { "label": "上传", "name": "upload", "type": "IMAGEUPLOAD", "widget": { "name": "upload" }, "link": null } ], "outputs": [ { "label": "图像", "name": "IMAGE", "type": "IMAGE", "links": [ 10 ] }, { "label": "遮罩", "name": "MASK", "type": "MASK", "links": null } ], "properties": { "cnr_id": "comfy-core", "ver": "0.5.1", "Node name for S&R": "LoadImage", "ue_properties": { "widget_ue_connectable": { "image": true, "upload": true }, "version": "7.5.2", "input_ue_unconnectable": {} }, "enableTabs": false, "tabWidth": 65, "tabXOffset": 10, "hasSecondTab": false, "secondTabText": "Send Back", "secondTabOffset": 80, "secondTabWidth": 65, "ttNbgOverride": { "color": "#332922", "bgcolor": "#593930", "groupcolor": "#b06634" }, "#sdppp_variant": "default", "#sdppp_simple_content": "canvas", "#sdppp_simple_mask": "canvas", "#sdppp_simple_boundary": "canvas", "#sdppp_label": "" }, "widgets_values": [ "微信图片_20260515114607_5418_3.png", "image" ], "color": "#332922", "bgcolor": "#593930" } ], "links": [ [ 1, 15, 0, 1, 0, "MODEL" ], [ 2, 5, 0, 2, 0, "CONDITIONING" ], [ 3, 13, 0, 3, 0, "CONDITIONING" ], [ 4, 1, 0, 4, 0, "MODEL" ], [ 5, 18, 0, 5, 0, "CLIP" ], [ 6, 14, 0, 5, 1, "VAE" ], [ 7, 8, 0, 5, 2, "IMAGE" ], [ 8, 8, 0, 7, 0, "IMAGE" ], [ 9, 14, 0, 7, 1, "VAE" ], [ 10, 12, 0, 8, 0, "IMAGE" ], [ 11, 4, 0, 9, 0, "MODEL" ], [ 12, 3, 0, 9, 1, "CONDITIONING" ], [ 13, 2, 0, 9, 2, "CONDITIONING" ], [ 14, 7, 0, 9, 3, "LATENT" ], [ 15, 9, 0, 10, 0, "LATENT" ], [ 16, 14, 0, 10, 1, "VAE" ], [ 17, 10, 0, 11, 0, "IMAGE" ], [ 18, 18, 0, 13, 0, "CLIP" ], [ 19, 14, 0, 13, 1, "VAE" ], [ 20, 8, 0, 13, 2, "IMAGE" ], [ 22, 16, 0, 15, 0, "MODEL" ], [ 23, 17, 0, 16, 0, "MODEL" ], [ 29, 10, 0, 26, 0, "IMAGE" ], [ 30, 19, 0, 13, 5, "STRING" ] ], "groups": [], "config": {}, "extra": { "workflowRendererVersion": "LG", "ue_links": [], "links_added_by_ue": [], "ds": { "scale": 0.40909090909091006, "offset": [ 1435.9227173859654, 918.2021927921285 ] }, "frontendVersion": "1.43.18", "VHS_latentpreview": false, "VHS_latentpreviewrate": 0, "VHS_MetadataImage": true, "VHS_KeepIntermediate": true }, "version": 0.4 }