
关于INTEL 的B70 PRO。
-
你的这个信息很有价值,如果仅仅生图就能强过4090的话,已经可以有很多本地的事情能做了。LTX/WAN这边,不知道480P的测试数据如何?如果480P已经可行的话,对于一些手机短视频,我觉得已经满足了。
-
分享一下单卡跑llmscaler数据
周末把 Qwen3.6-27B 调到了一个对于 Agentic Loop 来说还算能接受的状态。比较系统的跑了一下单请求和并行 5 rep的benchmark。pp速度还可以,但 tg还是有点慢。不过配合 vLLM 的 continuous batching,并行 token 生成整体还比较稳定。目前专门用来给Hermes agent的delegate task去收集代码库context打下手目前唯一比较大的问题是:KV Cache 必须使用 BF16,才能达到可用的 token generation 速度,但ctx就只有43000了。另外还需要骗 vLLM,让它识别 layer architecture。希望未来能有优化过的 FP8 dequant kernel去支持fp8的kvcache。fp8的dequant比Q8_0慢很多,可惜官方docker的vllm版本还不支持除了fp8和bf16以外的kvcache dtype。可惜它和7900xtx都没有fp8的硬件支持,好像r9700有。另外autoround质量还是稍微比不过Q4的gguf
硬件比较旧 64g的ddr4 虽然比较慢,但总比 pcie4x16 快。proxmox 9.1
vLLM 单请求 qwen/qwen3.6-27b(int4 AutoRound):
PP TTFT:1,685 ms
PP2048 TPS:1,686 ± 66 tok/s
TG512:13.7 ± 1.4 tok/s
并行测试 pp2048 tg512
Conc: 1
• TTFT(ms): 1,261
• Prefill(tok/s): 1,400
• Decode(tok/s): 13.3
• Output(tok/s): 12.9• Conc: 2
• TTFT(ms): 1,907
• Prefill(tok/s): 925
• Decode(tok/s): 12.9
• Output(tok/s): 24.7• Conc: 4
• TTFT(ms): 3,319
• Prefill(tok/s): 532
• Decode(tok/s): 12.7
• Output(tok/s): 46.7• Conc: 8
• TTFT(ms): 6,231
• Prefill(tok/s): 283
• Decode(tok/s): 11.9
• Output(tok/s): 82.7docker run 命令:
docker run -it --rm --name vllmb70 --ipc=host --shm-size=32g
--device=/dev/dri:/dev/dri --privileged -p 1234:8000
-v ~/.cache/huggingface:/root/.cache/huggingface
-e VLLM_TARGET_DEVICE=xpu
--entrypoint /bin/bash intel/llm-scaler-vllm:0.14.0-b8.2.1 -c "
source /opt/intel/oneapi/setvars.sh --force &&
sed -i 's/image_processor.max_pixels/getattr(image_processor, "max_pixels", 12845056)/g'
/usr/local/lib/python3.12/dist-packages/vllm/model_executor/models/qwen2_vl.py &&
python3 -m vllm.entrypoints.openai.api_server
--model Intel/Qwen3.6-27B-int4-AutoRound
--tokenizer Qwen/Qwen3.6-27B
--served-model-name qwen/qwen3.6-27b
--kv-cache-dtype auto
--max-model-len 65536
--gpu-memory-utilization 0.9
--enable-auto-tool-choice
--tool-call-parser qwen3_xml
--allow-deprecated-quantization
--trust-remote-code
--port 8000
--tensor-parallel-size 1
--pipeline-parallel-size 1
--enforce-eager
"也跑了一下ltx2.3 full gpu offload比4070需要dynamic loading快10%左右 custom node很多不支持 暂时不值得折腾
-
分享一下单卡跑llmscaler数据
周末把 Qwen3.6-27B 调到了一个对于 Agentic Loop 来说还算能接受的状态。比较系统的跑了一下单请求和并行 5 rep的benchmark。pp速度还可以,但 tg还是有点慢。不过配合 vLLM 的 continuous batching,并行 token 生成整体还比较稳定。目前专门用来给Hermes agent的delegate task去收集代码库context打下手目前唯一比较大的问题是:KV Cache 必须使用 BF16,才能达到可用的 token generation 速度,但ctx就只有43000了。另外还需要骗 vLLM,让它识别 layer architecture。希望未来能有优化过的 FP8 dequant kernel去支持fp8的kvcache。fp8的dequant比Q8_0慢很多,可惜官方docker的vllm版本还不支持除了fp8和bf16以外的kvcache dtype。可惜它和7900xtx都没有fp8的硬件支持,好像r9700有。另外autoround质量还是稍微比不过Q4的gguf
硬件比较旧 64g的ddr4 虽然比较慢,但总比 pcie4x16 快。proxmox 9.1
vLLM 单请求 qwen/qwen3.6-27b(int4 AutoRound):
PP TTFT:1,685 ms
PP2048 TPS:1,686 ± 66 tok/s
TG512:13.7 ± 1.4 tok/s
并行测试 pp2048 tg512
Conc: 1
• TTFT(ms): 1,261
• Prefill(tok/s): 1,400
• Decode(tok/s): 13.3
• Output(tok/s): 12.9• Conc: 2
• TTFT(ms): 1,907
• Prefill(tok/s): 925
• Decode(tok/s): 12.9
• Output(tok/s): 24.7• Conc: 4
• TTFT(ms): 3,319
• Prefill(tok/s): 532
• Decode(tok/s): 12.7
• Output(tok/s): 46.7• Conc: 8
• TTFT(ms): 6,231
• Prefill(tok/s): 283
• Decode(tok/s): 11.9
• Output(tok/s): 82.7docker run 命令:
docker run -it --rm --name vllmb70 --ipc=host --shm-size=32g
--device=/dev/dri:/dev/dri --privileged -p 1234:8000
-v ~/.cache/huggingface:/root/.cache/huggingface
-e VLLM_TARGET_DEVICE=xpu
--entrypoint /bin/bash intel/llm-scaler-vllm:0.14.0-b8.2.1 -c "
source /opt/intel/oneapi/setvars.sh --force &&
sed -i 's/image_processor.max_pixels/getattr(image_processor, "max_pixels", 12845056)/g'
/usr/local/lib/python3.12/dist-packages/vllm/model_executor/models/qwen2_vl.py &&
python3 -m vllm.entrypoints.openai.api_server
--model Intel/Qwen3.6-27B-int4-AutoRound
--tokenizer Qwen/Qwen3.6-27B
--served-model-name qwen/qwen3.6-27b
--kv-cache-dtype auto
--max-model-len 65536
--gpu-memory-utilization 0.9
--enable-auto-tool-choice
--tool-call-parser qwen3_xml
--allow-deprecated-quantization
--trust-remote-code
--port 8000
--tensor-parallel-size 1
--pipeline-parallel-size 1
--enforce-eager
"也跑了一下ltx2.3 full gpu offload比4070需要dynamic loading快10%左右 custom node很多不支持 暂时不值得折腾
-
想了想还是别另开贴了,搞的好像刷帖一样。
事情是这样的:我想深度的测一下这卡的稳定性。 如果长期去用,去批量跑任务,稳定性就很胆小。 于是就有了这个操作: 朋友让我帮忙处理一批图片,将图片 OCR 出来。 图片都是2K+分辨率的。 图片是一张大概有400-500行/10来列的表格。 用QWEN3.6-27B去反推直接给OCR到excel表格里,我也想看看这卡的能耐咋样,之前有飞浆这些要钱的。也有github上开源的那些,但批量处理这么大的,我没用过。 于是就写了代码,然后试了试这卡的能耐。只用了一张卡,从前天上午不到10点。到刚才。我截图也就是10分钟之前告诉我OK了。 代码如下:
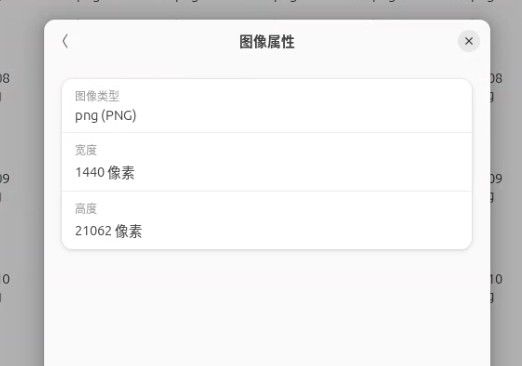
import base64 import os import glob import asyncio import aiohttp from io import BytesIO from PIL import Image API_URL = "http://localhost:8091/v1/chat/completions" IMAGE_DIR = "./cb*.png" OUTPUT_CSV = "./cb_data_full_fixed.csv" # B70 32G 显存并发数 CONCURRENCY = 6 def encode_image_from_bytes(image_bytes): return base64.b64encode(image_bytes).decode('utf-8') def slice_long_image(image_path, slice_height=1500): """ 核心修改:将超长图切片。 slice_height=1500 像素大约包含 30-50 行数据。 """ img = Image.open(image_path) width, height = img.size slices = [] for i in range(0, height, slice_height): # 截取切片区域 (left, upper, right, lower) box = (0, i, width, min(i + slice_height, height)) slice_img = img.crop(box) # 将切片保存在内存中转为 base64 buffered = BytesIO() slice_img.save(buffered, format="PNG") slices.append(buffered.getvalue()) return slices async def fetch_and_process_slice(session, date_str, slice_base64, slice_index, file_lock): payload = { "model": "/model", "messages": [ { "role": "system", "content": "你是一个无情的数据提取机器。直接输出CSV,不要任何多余文字。" }, { "role": "user", "content": [ { "type": "text", "text": "提取图片表格中所有可转债数据。请直接输出CSV格式。每行字段为:转债代码,转债名称,价格,涨幅,正股,正股价,溢价率。注意:不要包含表头,不要使用Markdown代码块(如 ```csv)。如果图片中没有完整数据行,请不要编造。" }, { "type": "image_url", "image_url": { "url": f"data:image/png;base64,{slice_base64}" } } ] } ], "max_tokens": 4096, "temperature": 0.0 } try: async with session.post(API_URL, json=payload) as response: if response.status != 200: print(f"⚠️ {date_str} (切片 {slice_index}) 请求失败") return res_json = await response.json() result = res_json['choices'][0]['message']['content'].strip() async with file_lock: with open(OUTPUT_CSV, "a", encoding="utf-8-sig") as f: for line in result.split('\n'): # 过滤掉可能的空行和重复生成的表头 if line.strip() and "," in line and "代码" not in line: f.write(f"{date_str},{line.strip()}\n") except Exception as e: print(f"❌ 处理 {date_str} (切片 {slice_index}) 发生异常: {e}") async def main(): image_list = sorted(glob.glob(IMAGE_DIR)) if not image_list: print(f"❌ 错误:没有找到符合 {IMAGE_DIR} 的图片!") return print(f"🔥 找到 {len(image_list)} 张超长图,准备进行切片并高并发推断...") if not os.path.exists(OUTPUT_CSV): with open(OUTPUT_CSV, "w", encoding="utf-8-sig") as f: f.write("日期,转债代码,转债名称,价格,涨幅,正股,正股价,溢价率\n") semaphore = asyncio.Semaphore(CONCURRENCY) file_lock = asyncio.Lock() async def sem_task(session, date_str, slice_bytes, index): async with semaphore: slice_b64 = encode_image_from_bytes(slice_bytes) await fetch_and_process_slice(session, date_str, slice_b64, index, file_lock) timeout = aiohttp.ClientTimeout(total=None) async with aiohttp.ClientSession(timeout=timeout) as session: tasks = [] for img_path in image_list: date_str = os.path.basename(img_path).replace("cb", "").replace(".jpg", "").replace(".png", "") # 对超长图进行切片 slices_bytes = slice_long_image(img_path) print(f"✂️ {date_str} 被切分为 {len(slices_bytes)} 块,加入队列...") for index, slice_bytes in enumerate(slices_bytes): tasks.append(sem_task(session, date_str, slice_bytes, index)) # 将所有切片任务并发执行 await asyncio.gather(*tasks) print("🎉 全部长图切片处理完成!去检查数据量吧!") if __name__ == "__main__": asyncio.run(main())具体处理的图片不方便粘贴,但文件夹内的样子可以放一下。两个箭头一个是这个代码文件,一个是需要处理的图片有240多张。每一个图片都是1440宽,大概20000+像素高。

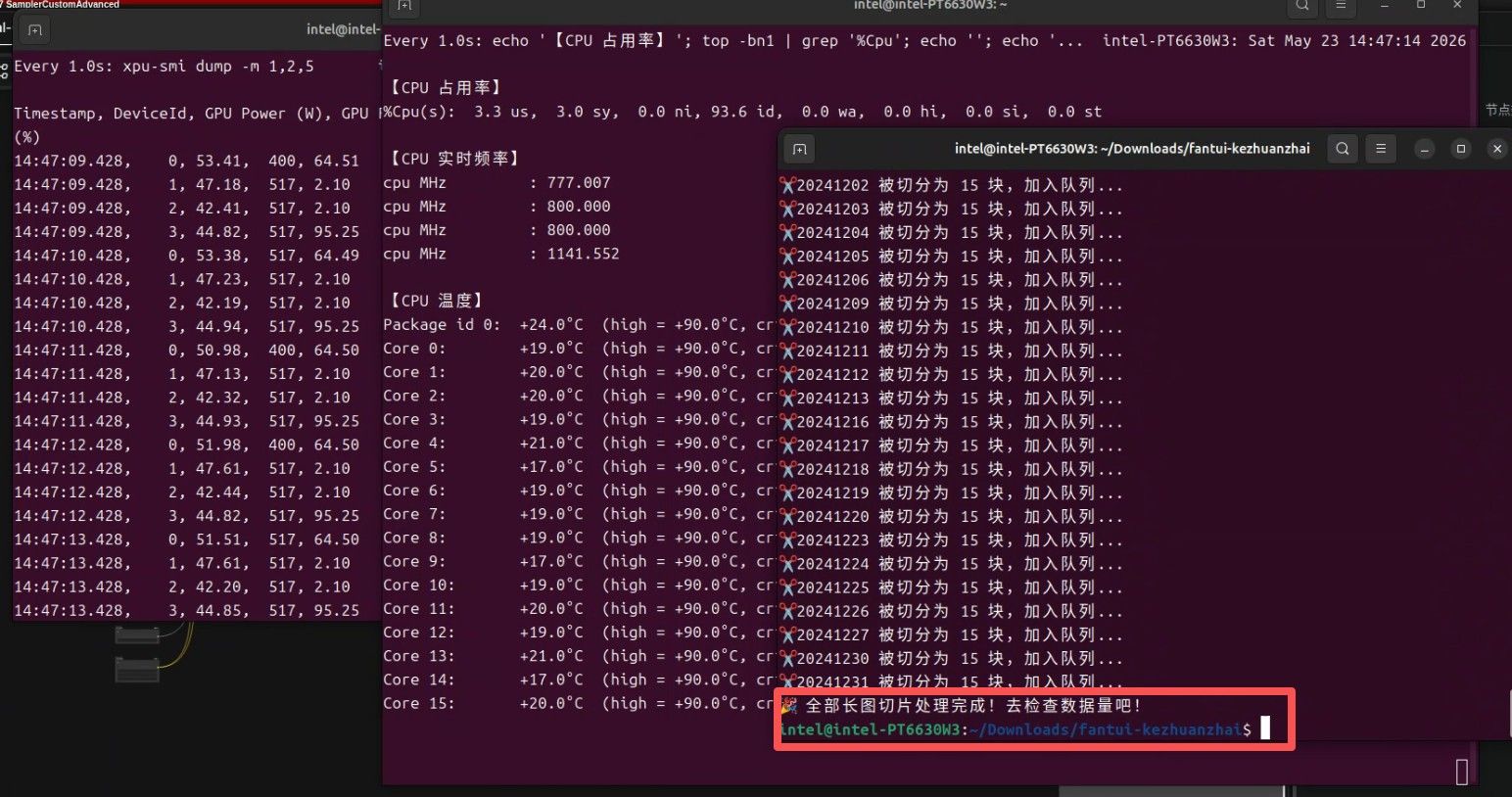
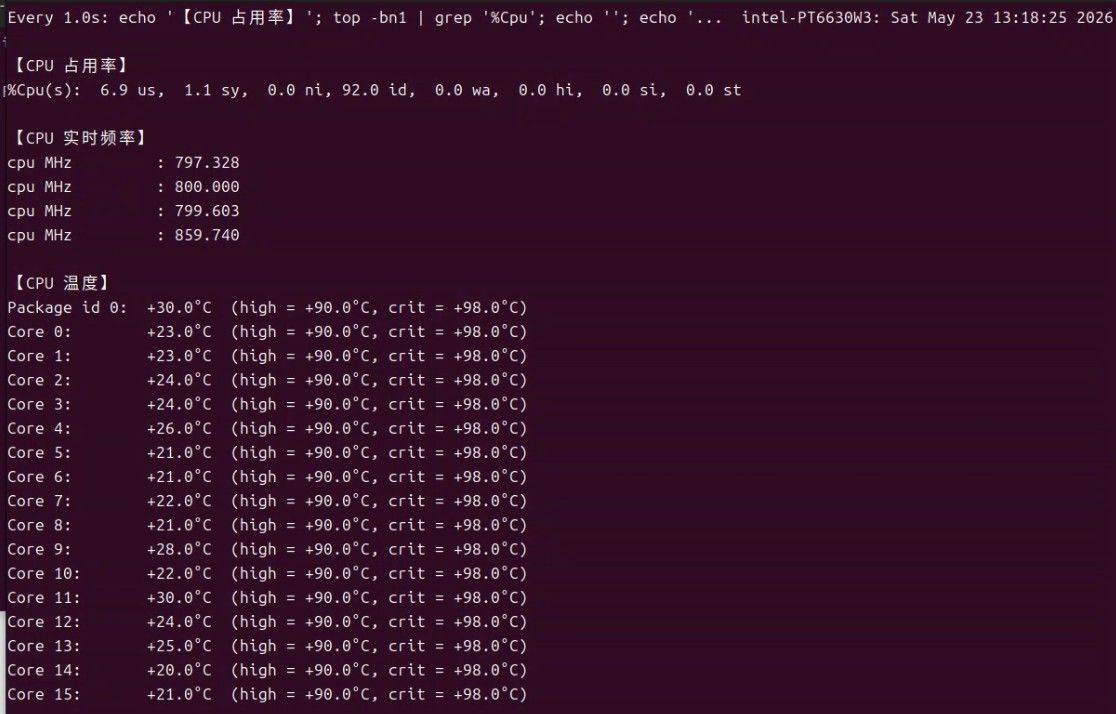
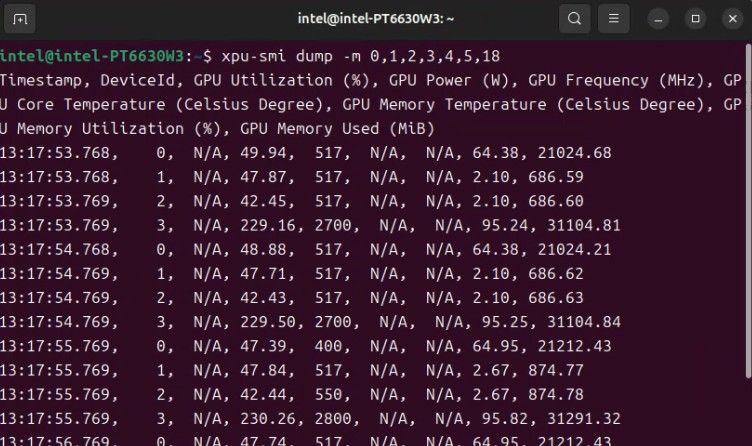
显卡的温度和占用,只用看ID 3就行。:
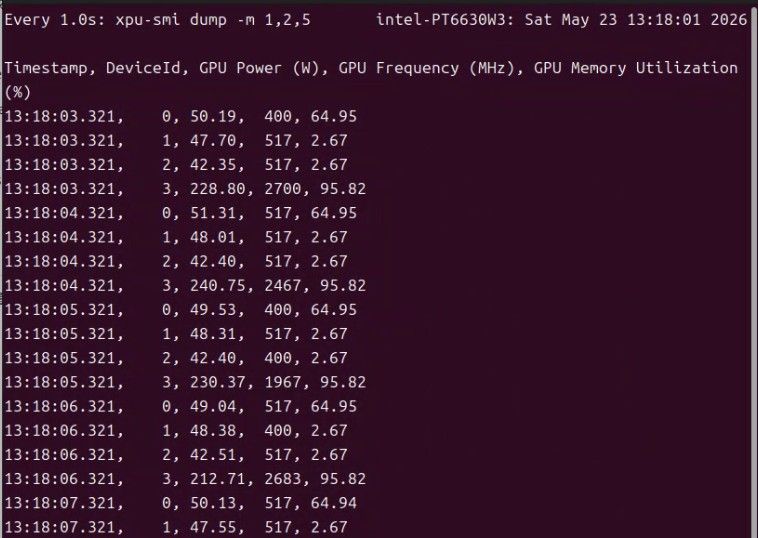
显卡的占用。不同的命令显示的有所区别。 只用看ID 3就行。
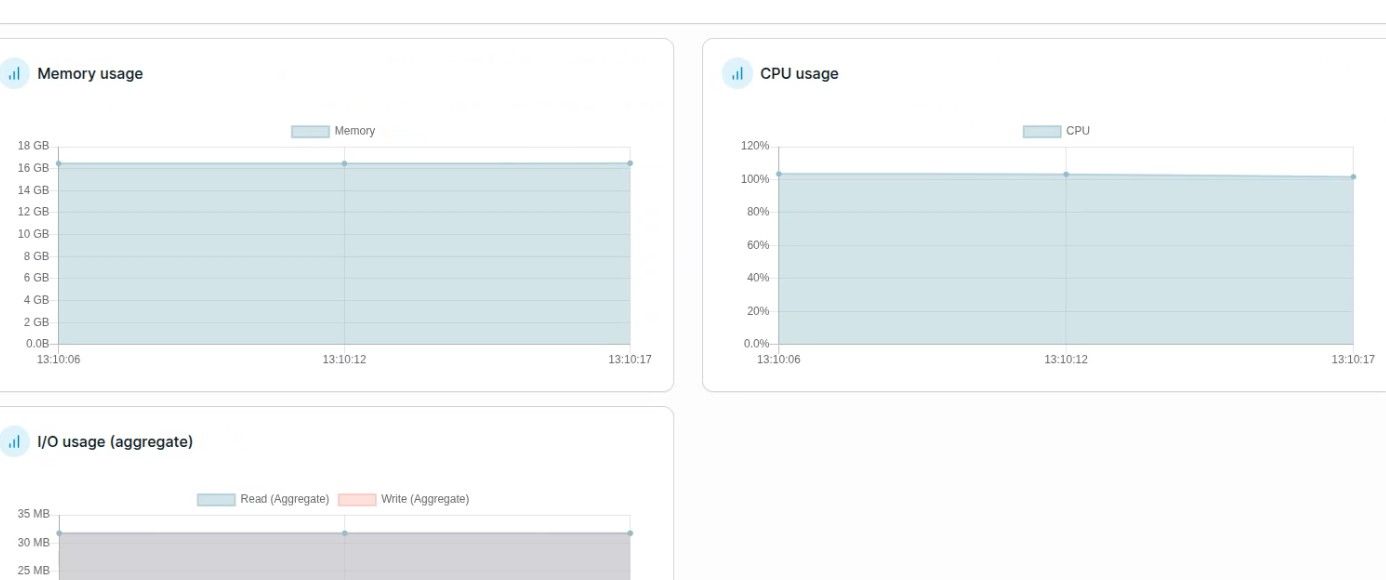
portainer 监控 docker 的截图
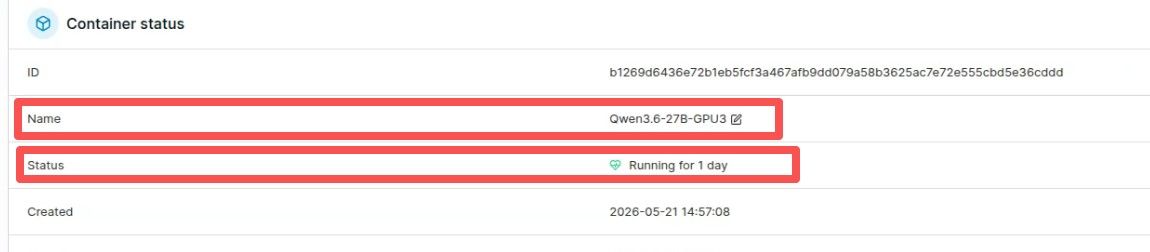
模型信息和docker运行的时间
可以看到全程这个GPU的占用率都在95%以上。 时间用了16个小时。 一直没停。 结论是:这卡目前稳定性还是相当NB的,当然,也可能是和我的任务复杂程度有关系?现在是6个并发数,同时处理6个图片。这是第一批。第二批我会尝试加大并发处理量来再跑跑。
-
系统 于 取消固定此主题
-
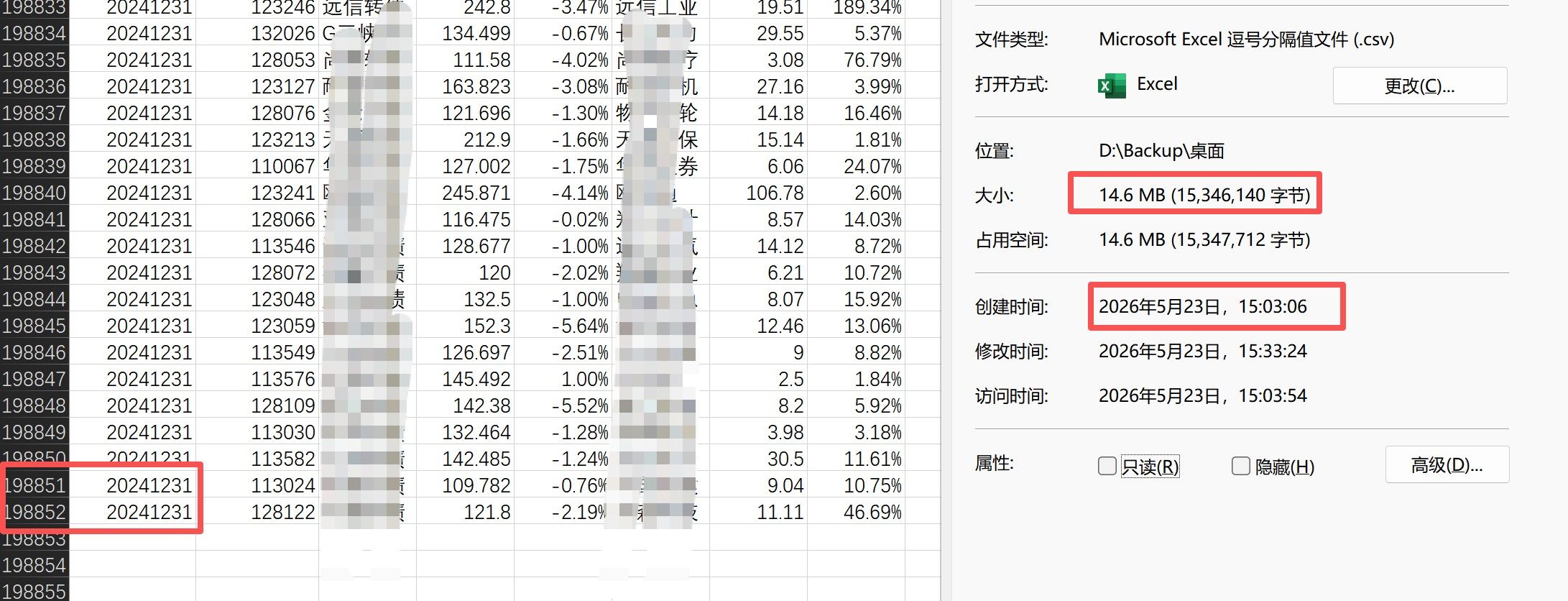
忘了贴最终的数据量了。 请原谅我的打码效果.... 哇哈哈哈
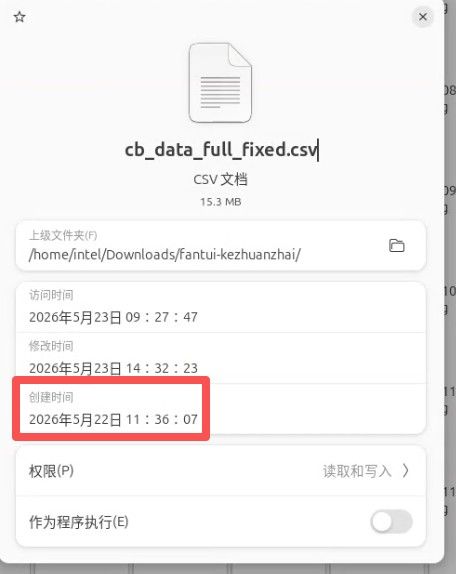
下边这张,是在linux上的截图,文件的创建时间是昨天上午的11.36,但在创建文件之前,代码已经运行了一个小时了,它得去把这200多个文件全部都截取成一个一个的小块才能读取数据OCR数据。所以文件时间就晚了一个小时。
-
 S sirwang 于 引用了 此主题
S sirwang 于 引用了 此主题