
雙 RX 7900 XTX + Ubuntu 24.04 + ROCm 6.3 實戰報告
-
 T terry 于 将此主题固定
T terry 于 将此主题固定
-



硬件:
- 主板:HUANANZHI X99-CD3 GAMING(X99)
- CPU:Xeon E5-2666 v3(10C/20T)
- RAM:128GB DDR3 ECC @ 1600
- GPU:2× RX 7900 XTX(PULSE,各 24GB)
- 儲存:NVMe 1.9TB(Win + Ubuntu + Shared)
- OS:Ubuntu 24.04.4 / kernel 6.17.0
軟件:
- ROCm 6.3 / Python 3.12.3
- llama.cpp b9198(自編譯 ROCm)
- ComfyUI + ComfyUI-Manager
- Shell scripts 管理全部操作(~/bin/)
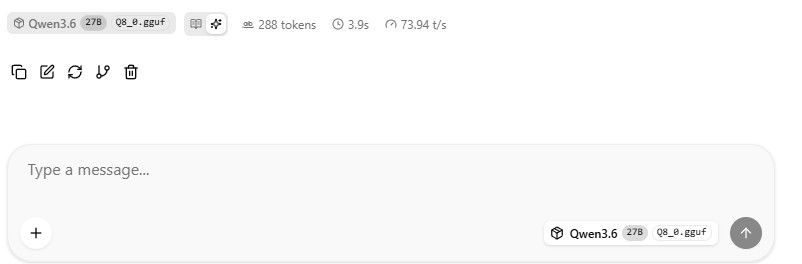
LLM Benchmark(Qwen3.6-27B Q4_K_M):
單卡
• 配置: 單卡
• Context: 8K
• Token Gen: 27.2 t/s
單卡
• 配置: 單卡
• Context: 128K
• Token Gen: 27.0 t/s
雙卡 tensor-split
• 配置: 雙卡 tensor-split
• Context: 8K
• Token Gen: 19.8 t/s
雙卡 tensor-split
• 配置: 雙卡 tensor-split
• Context: 128K
• Token Gen: 21.4 t/s
→ 單卡打贏雙卡 tensor-split!27B Q4_K_M fit 入 24GB VRAM 單卡已經最快。雙卡只係 >64K context 先用得著。
投機解碼:
Qwen3.6 用 M-RoPE,同 llama.cpp 投機解碼唔相容(全部 spec type 失敗,accept rate < 13%)。Skip,27 t/s 已經夠快。ComfyUI 雙 Instance:
兩張卡各一個獨立 ComfyUI(port 8188/8189),systemd 管理自動開機。Flux.1 dev:78.9s(雙 instance)vs 73.4s(tensor-split)
LTX Video:13.5s(雙 instance)vs 22.9s(tensor-split)→ 雙 instance 整體完勝,尤其 LTX 快接近一倍,仲可以同時跑兩個 workflow。
ROCm 6.3 tips:
- 記得 delete blacklist-amdgpu.conf
- 唔使 HSA_OVERRIDE_GFX_VERSION(gfx1100 原生支援)
- tensor-split 用 --tensor-split 24,24(absolute GiB)
- ROCm 6.3 對 RX 7900 XTX 支援完善
@Chan-Ivan 估计是两张显卡的 pcie 带宽瓶颈,如果3.0 x16, 向量并行,我猜应该不止这个速度,reddit上也有人跑过双xtx。
-
@Chan-Ivan 估计是两张显卡的 pcie 带宽瓶颈,如果3.0 x16, 向量并行,我猜应该不止这个速度,reddit上也有人跑过双xtx。
-
系统 于 取消固定此主题
-
T terry 于 将此主题固定

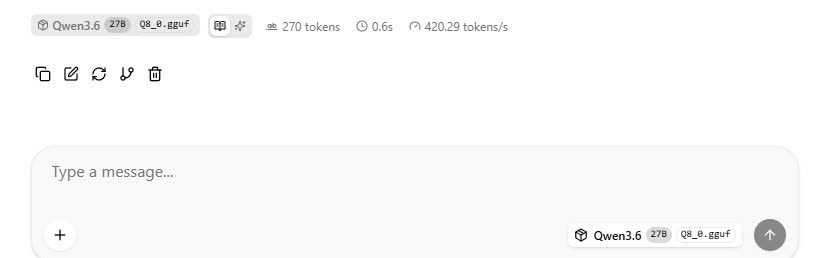 ,
,
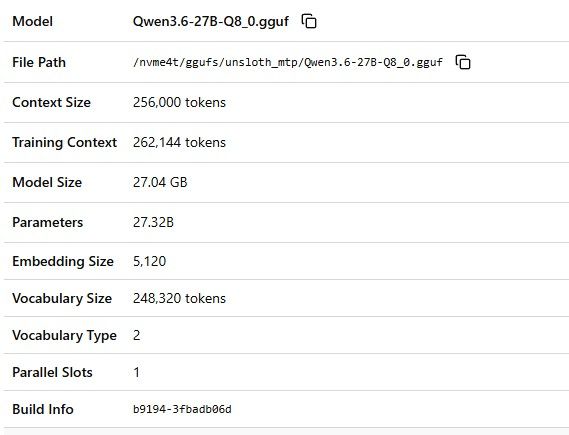
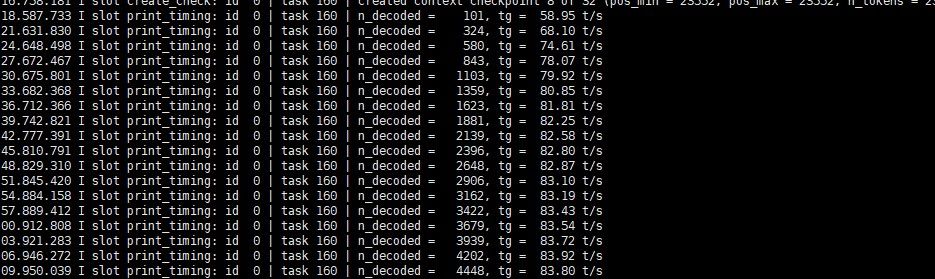 ,生产力相当可以了
,生产力相当可以了