macbookpro M3max 128G 8T怎么折腾玩本地AI?
-
@terry 好的,老特。我下单了xtx,京东6089,三年质保,准备在旧的windows主机上跑个Ubuntu,装个双系统先玩玩,后面再买洋垃圾在攒个主机。macbookpro暂时也先不卖了,多个折腾的硬件吧,m3max不跑大模型性能还是非常强的,就是可惜了128G的大内存了。
-
1,统一内存没啥带宽优势,CPU和内存共享带宽还小的1B,比起xtx 3090的1T带宽是幼儿园水平。
2,M3 AI算力很差,Ultra都慢,何况Max?LLM还能抢救下,试试看OMLX。ComfyUI可以放弃,M5也不行。
3,M3 Max这么好的本子你卖它干嘛,留下来当办公机器。
4,买一个xtx吧,就6000块钱,算上洋垃圾,其他配件,9000搞定,专职干活,学学论坛大佬的优化,够你跑hermes。 -
@Phuong-Ngo 恭喜成功上车!从M3 Max到xtx + Ubuntu,这步走得值。
关于内存占用21G和上下文大小的问题,我帮你算一下:
Qwen 3.6 27B 在 Q4_K_M 量化下模型本身约占用 16-17GB。剩下的 4-5GB 是 KV Cache。64K 上下文大概用 3-4GB KV Cache,所以加起来 21GB 是正常的。
最大上下文的决定因素:
- 模型本身的 context length 限制(Qwen3.6 官方最大 128K,但实际拉到满要看显存)
- 你的 xtx 只有 24GB 显存,21GB 已经占了 87%
如果要拉更高上下文(比如 96K 或 128K),有几个方向可以试试:
- 换量化更狠的模型:Q3_K_M 或 Q3_K_S 可以省出 2-3GB,多出来的空间给 KV Cache
- 用 llama.cpp 的 --no-kv-off 或降低 --cache-reuse 来精细化控制内存
- 如果你的 Hermes 配置了 streaming,可以把上下文分片处理,不用一次拉满
保守建议:67K(64K + 一点余量)其实日常用已经非常够用了。Hermes Agent 跑大部分任务用 32K 都绰绰有余,64K 只有长文档分析或者大项目重构才用得到。
建议先 32K 上下文跑起来,看看 Hermes 的实际表现,等遇到真的需要长上下文的场景了再往上调。
-
@terry 我买的xtx到了,已经装了ubuntu,部署了qwen 3.6 27B模型,hermes也已经配好了,有个问题就是现在显存占用21G左右,给hermes设的上下文是64K,emm最大上下文能到多少?
-
【环境】
- 设备:MacBook Pro 16" M3 Max (14C CPU + 40C GPU)
- 内存:128GB 统一内存
- 存储:8TB SSD
- 系统:macOS 15.6
【目标】
想在本地搭建一套可长期运行的 AI 工作流,主要用途:
- LLM 推理:跑 27B 级稠密模型(如 Qwen3.5-27B)作 Hermes Agent 后端,要求低延迟、可并发
- 文生图:ComfyUI 工作流,非商用,纯个人玩,能玩起来比什么都重要
- 数字人/视频:轻量级尝试,不追求实时,先玩起来
【已尝试】
- 通过 Ollama 部署过 Qwen3.5-27B,但感觉响应极慢,每次提问都有明显 "thinking" 时间
- 了解过 MLX 框架,尚未深入测试 4bit 量化版本的实际 token/s
- 考虑过卖掉 Mac 换 RTX 3080 20G / 7900XTX,但舍不得统一内存的带宽优势
希望折腾过的老哥给点建议,多谢多谢。
@Phuong-Ngo 数字人/视频:轻量级尝试,不追求实时,先玩起来
玩点别的吧。 -
看完此贴第一感受就是如果是考虑大模型其实真没必要自己折腾硬件,opencode 套餐调用足够使用了,特别是DeepSeek上下1m,何必如此折腾!最应该有意义的本地折腾是ComfyUI 。
-
【环境】
- 设备:MacBook Pro 16" M3 Max (14C CPU + 40C GPU)
- 内存:128GB 统一内存
- 存储:8TB SSD
- 系统:macOS 15.6
【目标】
想在本地搭建一套可长期运行的 AI 工作流,主要用途:
- LLM 推理:跑 27B 级稠密模型(如 Qwen3.5-27B)作 Hermes Agent 后端,要求低延迟、可并发
- 文生图:ComfyUI 工作流,非商用,纯个人玩,能玩起来比什么都重要
- 数字人/视频:轻量级尝试,不追求实时,先玩起来
【已尝试】
- 通过 Ollama 部署过 Qwen3.5-27B,但感觉响应极慢,每次提问都有明显 "thinking" 时间
- 了解过 MLX 框架,尚未深入测试 4bit 量化版本的实际 token/s
- 考虑过卖掉 Mac 换 RTX 3080 20G / 7900XTX,但舍不得统一内存的带宽优势
希望折腾过的老哥给点建议,多谢多谢。
@Phuong-Ngo comfy 生个图还行,生视频慢到怀疑人生
-
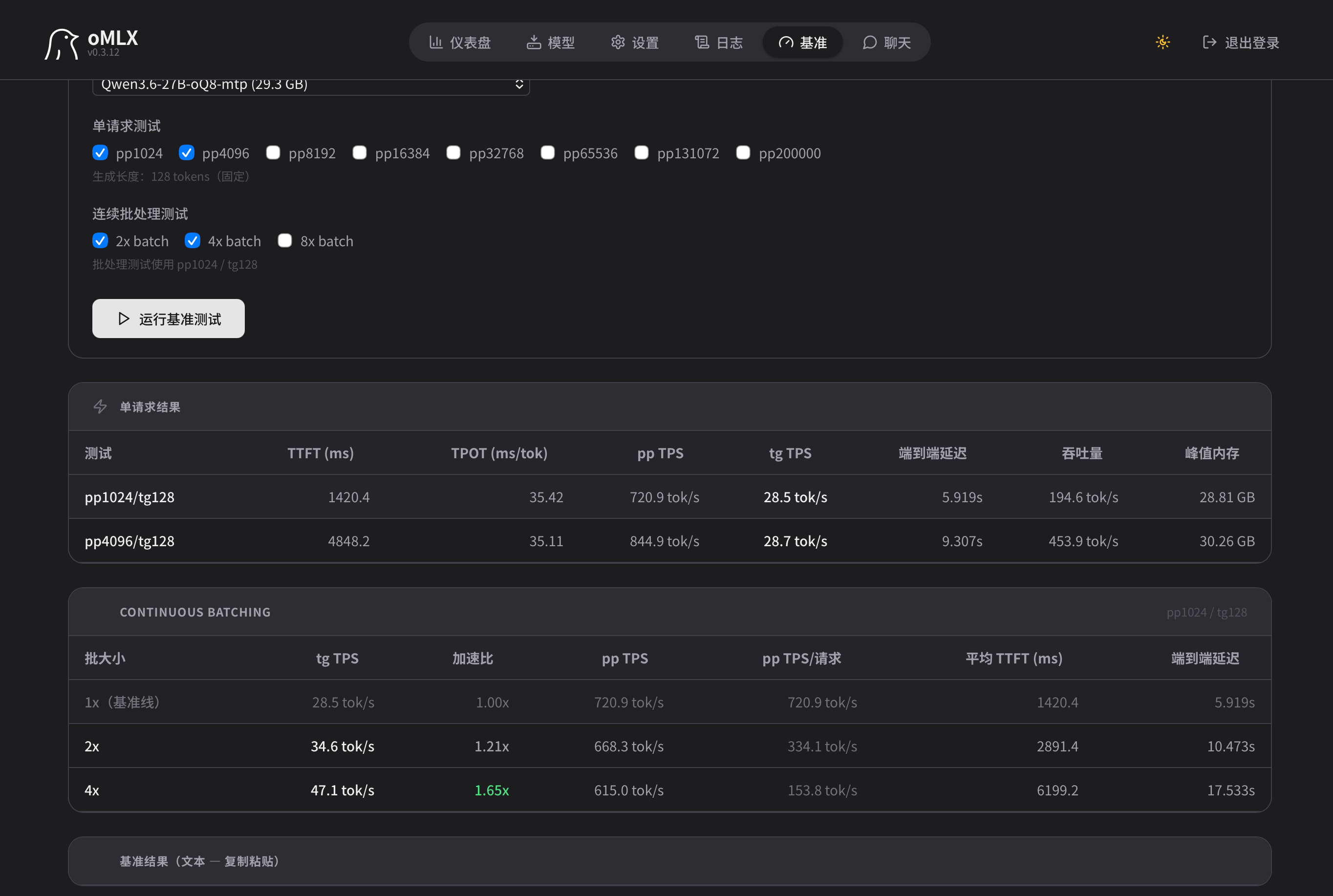
最新进展
7900XTX和ubuntu的环境已经搭起来了,老特说的没错,128KQ8确实能跑起来,最后给到了160KQ8,显存占用91%
,用hermes agent实测28token/s,本地养hermes确实够用了。hermes折腾过了,返回来在折腾comfyUI生图生视频。折腾这些的初衷不为别的,就是让自己找点事干,买了macbookpro之后本地模型跑起来速度确实慢,有点受不了了,刚好碰到老特了,燃起希望了,目前看来6000的XTX真是太夯了。先在论坛抄各位大佬的作业先玩起来。 -
最新进展
7900XTX和ubuntu的环境已经搭起来了,老特说的没错,128KQ8确实能跑起来,最后给到了160KQ8,显存占用91%
,用hermes agent实测28token/s,本地养hermes确实够用了。hermes折腾过了,返回来在折腾comfyUI生图生视频。折腾这些的初衷不为别的,就是让自己找点事干,买了macbookpro之后本地模型跑起来速度确实慢,有点受不了了,刚好碰到老特了,燃起希望了,目前看来6000的XTX真是太夯了。先在论坛抄各位大佬的作业先玩起来。