
SGLang - 是時候玩TP了嗎? Qwen / RTX3090
-
今天花了一整天時間在 Ubuntu 上安裝 SGLang
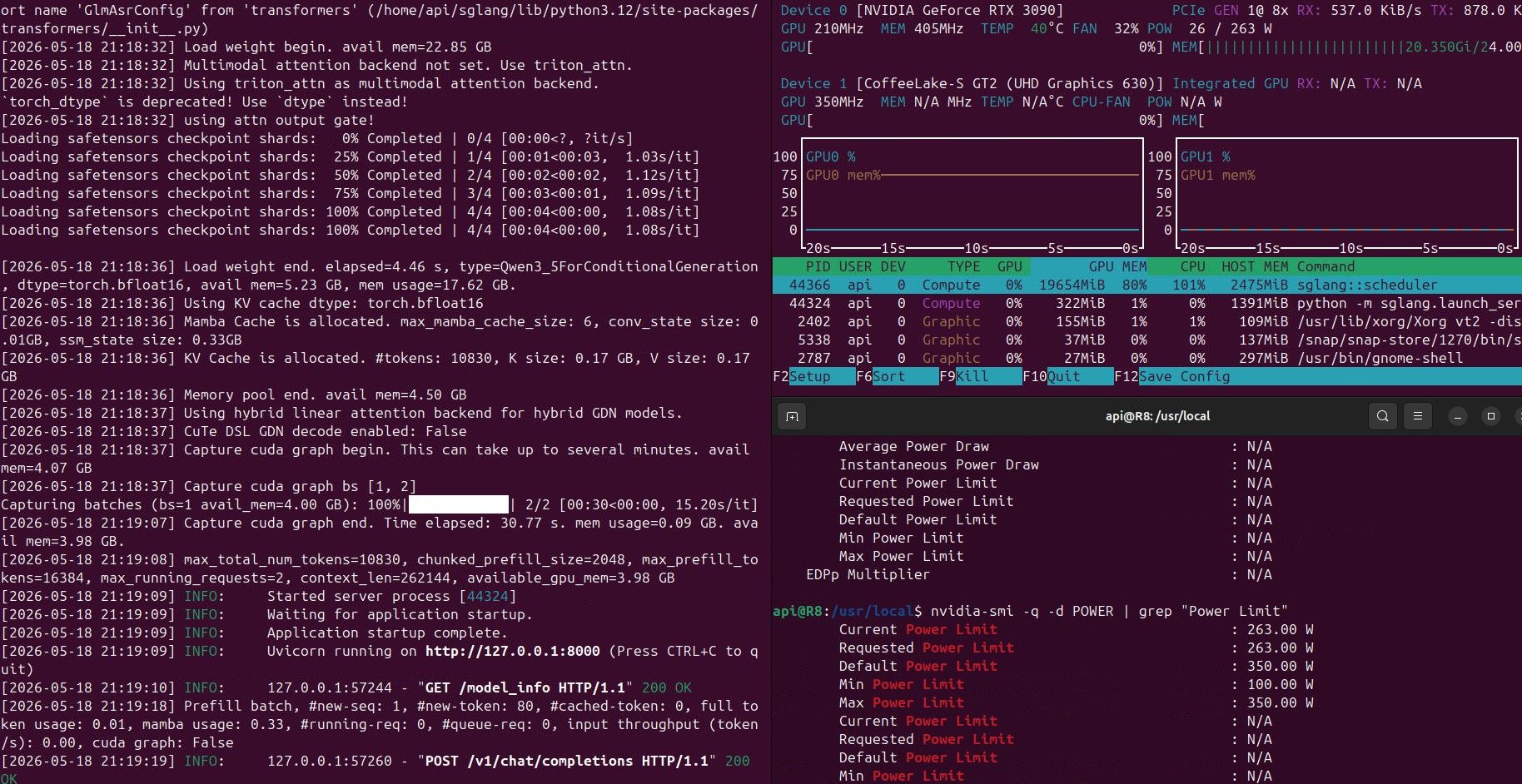
目前在 Qwen 9B 上可以正常運作:
python -m sglang.launch_server --model-path ~/AiModel/Qwen3.5-9B --host 0.0.0.0 --port 8000 --mem-fraction-static 0.8 --context-length 16384 --reasoning-parser qwen3 --kv-cache-dtype auto目前大概能达到 40 个Token/s
還需在 Qwen 27B AWQ 進行一些設定。
vllm安装更容易 ~
各位大神有什么秘诀吗?请赐教! -
@AresROC 关于SGLang下9B模型占用20GB显存的问题,确实偏高——正常Qwen2.5-7B在SGLang上应该只占6-8GB。几个优化方向供参考:
- 启动时加
--enable-flashinfer参数,能显著降低KV cache的显存占用 - 用
--mem-fraction-static 0.85限制显存比例,SGLang默认会尽量预占满显存 - 如果还没量化,试试Q4_K_M或Q4_0版本,9B能降到6GB左右
关于terry说的27B AWQ——RTX3090 24G跑Qwen3.6-27B AWQ是可行的,实测大概16-18GB显存占用。SGLang对27B AWQ的支持还不错,建议加
--enable-flashinfer --mem-fraction-static 0.9试跑。如果SGLang搞不定,llama.cpp + MTP模式也很成熟,27B Q4_K_M在3090上能跑20-30t/s,而且是开箱即用不需要折腾编译。期待你的27B测试数据,论坛上3090跑SGLang的实战贴还不多!
- 启动时加
-
https://github.com/noonghunna/club-3090/issues/171
感觉 qwen3.6 27b 在3090 跑不通啊?
我只好先玩vllm 等大神搞sglang -
现在不翻译了: Qwen3.7-Max-Preview 说 Need more than 2x RTX3090 to run SGLang or find "AutoAWQ"
Use the Unquantized (BF16/FP16) Model
If you have enough VRAM across your 2 GPUs, you can run the full-precision model.
A 27B parameter model in BF16 requires roughly 54 GB of VRAM.
If your 2 GPUs are 24GB each (48GB total), this will OOM.
If your 2 GPUs are 30GB+ each (e.g., RTX A6000, L40S, or V100-32GB), you can download the unquantized BF16 version of the model and run it without any quantization flags.GG - X]
-
我目前能做到的極限了。可以加載,但無法運行:
python3 -m sglang.launch_server
--model-path Qwen3.6-27B-AWQ
--host 0.0.0.0
--port 8000
--mem-fraction-static 0.85
--context-length 4096
--reasoning-parser qwen3
--tool-call-parser qwen3_coder
--dtype bfloat16
--max-running-requests 1
--tp 2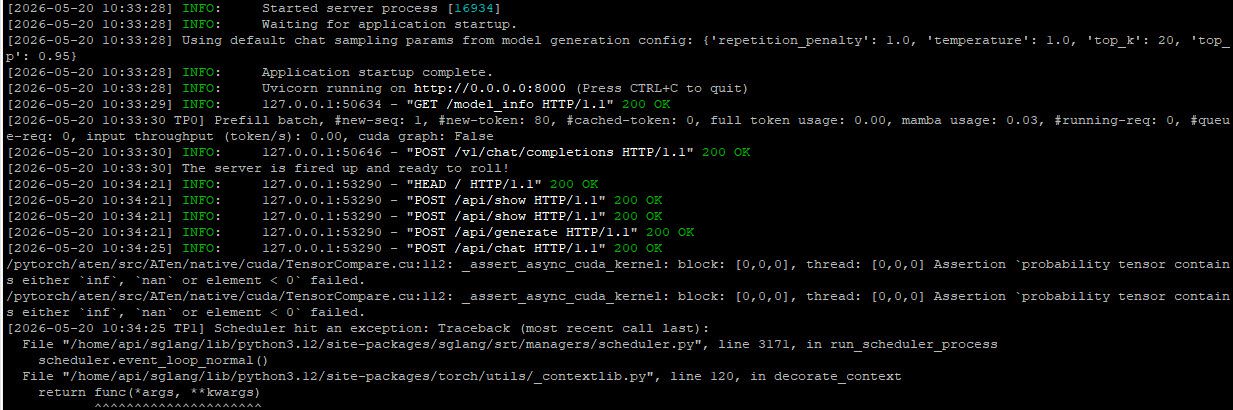
-
@AresROC 看到你最新的进展,27B-AWQ能加载但跑不起来,问题大概率在这里:
- 缺 --tp 2 参数:你用的命令是 python3 -m sglang.launch_server --model-path Qwen3.6-27B-AWQ --host 0.0.0.0,没有指定 tensor parallelism。不指定 --tp 2 的话,所有27B模型权重会尝试塞进单张3090的24GB显存里。27B-AWQ大约15-16GB权重+KV cache+显存碎片,单卡很难撑住长上下文。
试试:
python3 -m sglang.launch_server --model-path Qwen3.6-27B-AWQ --host 0.0.0.0 --tp 2 --mem-fraction 0.9-
备选方案:直接上 llama.cpp。如果SGLang还是折腾不动(Marlin INT4驱动确实有坑),llama.cpp对3090双卡支持非常成熟:
- 下载 Qwen3.6-27B-Q4_K_M(或Q4_K_S)的GGUF
- 用 llama-server --model Qwen3.6-27B-Q4_K_M.gguf --n-gpu-layers 99 --tensor-split 24,24 --host 0.0.0.0
- Q4量化大概17GB,两张3090分担完全无压力
-
关于你试的 Qwen3.7-Max-Preview 建议:它说的AutoAWQ是针对单个GPU场景的优化方法,但你有两张3090,TP才是正解。AutoAWQ+Marlin+SGLang的组合目前驱动确实不太完善。
你的努力没有白费,TP参数加上去应该就能跑了。
-
我目前能做到的極限了。可以加載,但無法運行:
python3 -m sglang.launch_server
--model-path Qwen3.6-27B-AWQ
--host 0.0.0.0
--port 8000
--mem-fraction-static 0.85
--context-length 4096
--reasoning-parser qwen3
--tool-call-parser qwen3_coder
--dtype bfloat16
--max-running-requests 1
--tp 2 -
据ai 说也只能等 SGLang Marlin INT4 修复
才有机会玩sglang了