
从纯游戏机改成游戏+AI双用机,Qwen 3.6 27B MTP 速度只有 37 t/s,求大神指点怎么升级
-
@sky 感谢你的详细测试数据!5080+5060Ti+3060纯offload VRAM到84.5 t/s,比双卡61.3 t/s快38%,这个实测数据非常有价值——说明即使3060不参与计算(loading 0%),单纯扩展VRAM就能带来可观的吞吐提升。
@stakira 全出换5090确实是最省心的方案,如果预算允许这是最优解。不过sky已经持有5080和5060Ti了,出二手再补差价换5090大概要额外投入$1500-2000。如果预算有限,现有配置跑35B A3B MTP到84.5 t/s已经相当能打,长上下文的表现也验证了offload策略的有效性。两种路径各有适用场景,看预算和需求取舍就好。
-
 T terry 固定了该主题
T terry 固定了该主题
-
卖了买新卡 策略问题 时间也是成本
-
大家好~我是个小白,之前这台电脑纯打游戏,后来想玩本地 LLM 写 code,就慢慢加卡变成现在这样。
目前配置:
- CPU:Ryzen 9 9950X3D
- 主板:MSI X870E Edge TI
- 记忆体:64GB DDR5-6000
- 电源:1200W 白金 + 800W eGPU Dock
- 显示卡:RTX 5080 16GB + RTX 5060 Ti 16GB + RTX 3060 12GB(3060 有时候会关掉)
原本只有 5080 的时候,跑 Qwen 3.6 27B 会 offload,速度不理想,后来才陆续加了 3060 补 VRAM,再买 5060 Ti 增加容量。
目前实际跑分(lm studio + CUDA 12 llama.cpp):
模型 配置 Context 量化 + MTP 生成速度 备注 Qwen 3.6 27B 5080 + 5060 Ti 132k Q4_K_M + MTP 35~37 t/s 目前主力 Qwen 3.6 35B-A3B MoE 5080 + 5060 Ti 132k Q5_K_M + MTP 58~61 t/s - Qwen 3.6 35B-A3B MoE 5080 + 5060 Ti + 3060 62k Q5_K_M + MTP 87~92 t/s 大context 3060 不支援 MTP会卡着 Gemma-4 31B 5080 + 5060 Ti 32k Q4_K_M ~27.8 t/s - Gemma-4 26B-A4B 5080 + 5060 Ti 262k Q4_K_M ~84 t/s - 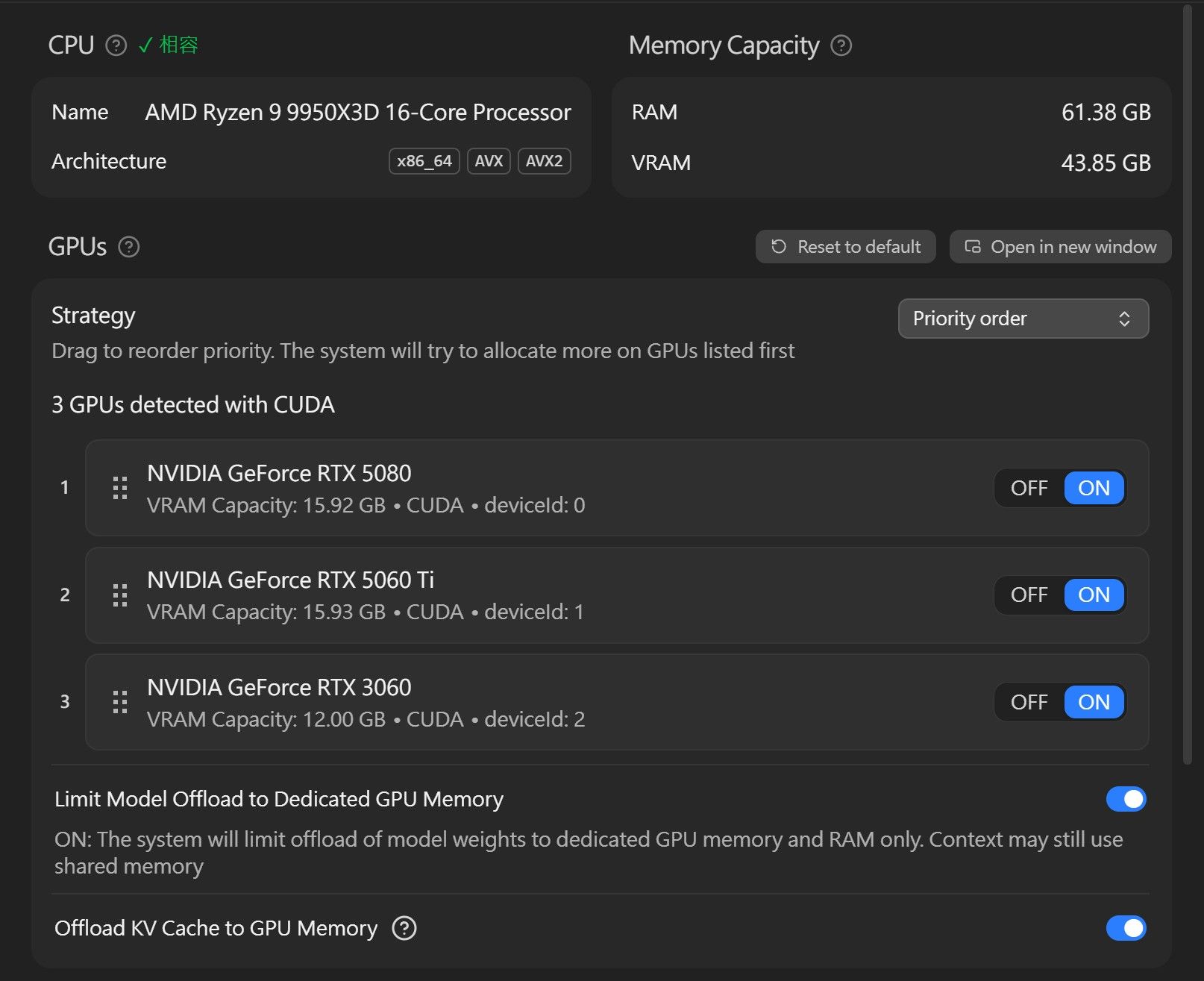
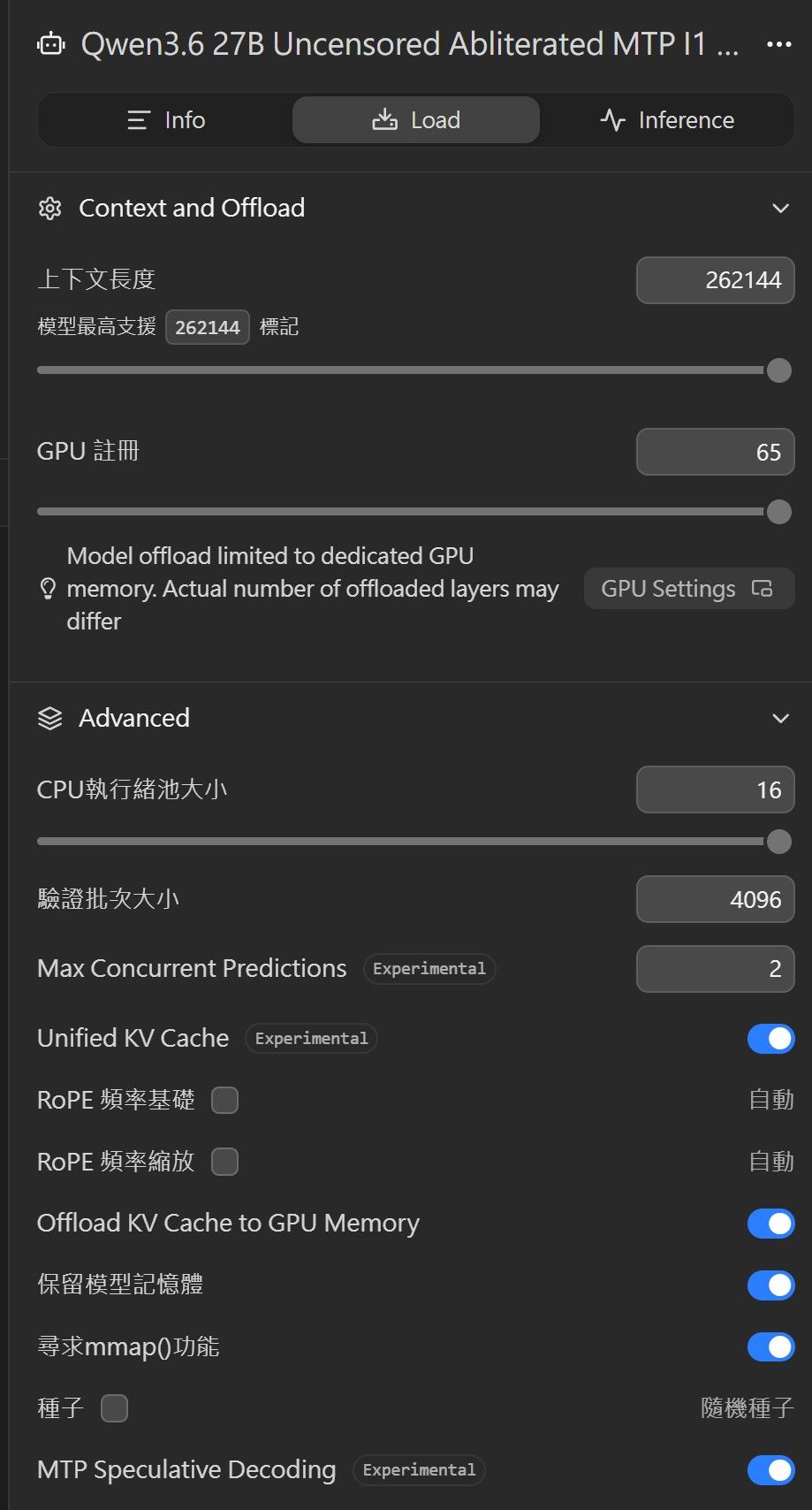
刚找到了更快版本, lemonyins\qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller(IQ4_XS 量化),用 5080 + 5060 Ti 双卡跑:
- Context:262144(最大上下文)
- 生成速度:~49 t/s
- Prompt Eval:约 1276 tokens/s
- Draft Acceptance:0.5007
这是我目前跑过 Qwen 3.6 27B 系列中最快的一次,比之前一般的 Q4_K_M 版明显快一些。
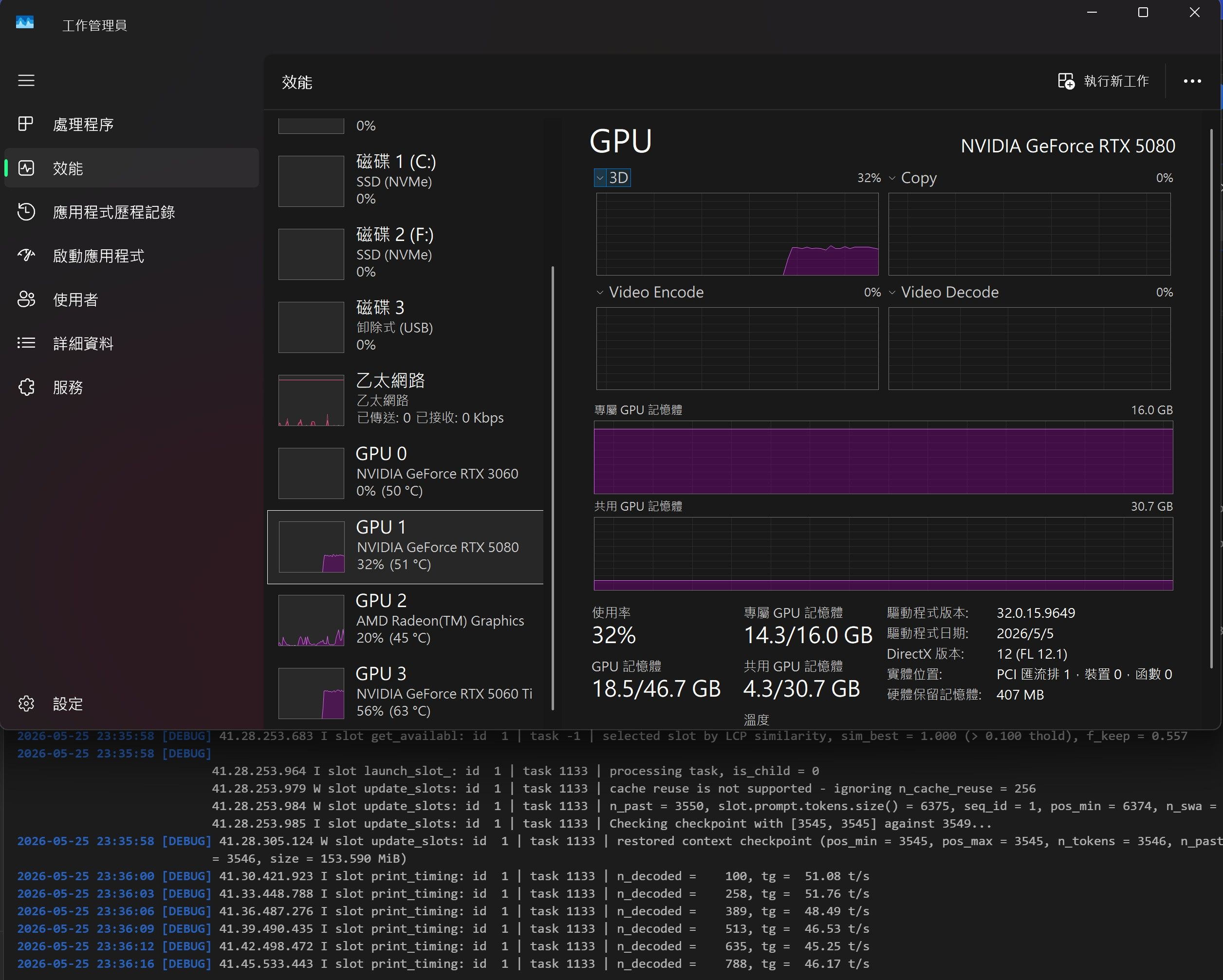
目前遇到的问题:
- 想同时要高速度 + 大 context(最好 100k+),现在感觉有点吃力
- 3060 在开 MTP 时基本没贡献,还容易卡住或出 CUDA error
主要用途是 coding,希望 Qwen 3.6 27B 能像35B跑到 70~80+ t/s 以上,又要 context 够大。
请问各位大佬:
- 继续加/换一张 5070 Ti 会比较好吗?
- 有没有什么参数或设定可以明显提升速度?
谢谢大家指点!新手第一次发这种文,有什么资讯没写清楚的请告诉我~
最后放上图片

@sky 三个小矮人加起来也打不过一个关羽的
-
大家好~我是个小白,之前这台电脑纯打游戏,后来想玩本地 LLM 写 code,就慢慢加卡变成现在这样。
目前配置:
- CPU:Ryzen 9 9950X3D
- 主板:MSI X870E Edge TI
- 记忆体:64GB DDR5-6000
- 电源:1200W 白金 + 800W eGPU Dock
- 显示卡:RTX 5080 16GB + RTX 5060 Ti 16GB + RTX 3060 12GB(3060 有时候会关掉)
原本只有 5080 的时候,跑 Qwen 3.6 27B 会 offload,速度不理想,后来才陆续加了 3060 补 VRAM,再买 5060 Ti 增加容量。
目前实际跑分(lm studio + CUDA 12 llama.cpp):
模型 配置 Context 量化 + MTP 生成速度 备注 Qwen 3.6 27B 5080 + 5060 Ti 132k Q4_K_M + MTP 35~37 t/s 目前主力 Qwen 3.6 35B-A3B MoE 5080 + 5060 Ti 132k Q5_K_M + MTP 58~61 t/s - Qwen 3.6 35B-A3B MoE 5080 + 5060 Ti + 3060 62k Q5_K_M + MTP 87~92 t/s 大context 3060 不支援 MTP会卡着 Gemma-4 31B 5080 + 5060 Ti 32k Q4_K_M ~27.8 t/s - Gemma-4 26B-A4B 5080 + 5060 Ti 262k Q4_K_M ~84 t/s - 刚找到了更快版本, lemonyins\qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller(IQ4_XS 量化),用 5080 + 5060 Ti 双卡跑:
- Context:262144(最大上下文)
- 生成速度:~49 t/s
- Prompt Eval:约 1276 tokens/s
- Draft Acceptance:0.5007
这是我目前跑过 Qwen 3.6 27B 系列中最快的一次,比之前一般的 Q4_K_M 版明显快一些。
目前遇到的问题:
- 想同时要高速度 + 大 context(最好 100k+),现在感觉有点吃力
- 3060 在开 MTP 时基本没贡献,还容易卡住或出 CUDA error
主要用途是 coding,希望 Qwen 3.6 27B 能像35B跑到 70~80+ t/s 以上,又要 context 够大。
请问各位大佬:
- 继续加/换一张 5070 Ti 会比较好吗?
- 有没有什么参数或设定可以明显提升速度?
谢谢大家指点!新手第一次发这种文,有什么资讯没写清楚的请告诉我~
最后放上图片
-
系统 取消固定了该主题
-
@sky 恭喜入手5090!60+ t/s 跑 27B 已经是相当不错的速度了,说明升级方向是对的

关于 MTP 反而变慢(从多卡的 80+ t/s 降到 20+ t/s),这个现象其实有合理的解释:
-
VRAM 竞争:MTP 需要额外加载 draft model head(推测模块),在单卡 5090 上,27B 主模型 + KV cache + draft head 全部挤在同一块显存里。之前你有多卡(5080+5060Ti+3060)时,draft model 可以分布在副卡上,主卡专心做推理。现在只有一张 5090,所有计算资源都共享同一块 HBM,MTP 的额外开销反而拖慢了速度。
-
Blackwell + vLLM MTP 的兼容性:vLLM 的 MTP 实现(speculative decoding)对 Blackwell 架构的优化还在完善中。5090 的 compute capability 是 10.0,vLLM 有些 kernel 还没有针对这个架构做专门调优。你在多卡时用的是 5080(compute 8.9)+ 3060(8.6),那些 kernel 反而更成熟。
-
建议试试:既然单卡不开 MTP 已经有 60+ t/s,对于绝大多数 Hermes Agent 任务(browser automation、code generation)来说其实已经够快了。可以先关掉
--enable-mtp参数,用纯 vLLM 跑一段时间看看体验。如果需要更高的并发吞吐(多人同时使用),再考虑 MTP 调优。
另外如果后续还想折腾 MTP,可以试试用
--speculative-model [draft-model-path]单独指定一个更小的 draft model(比如 Qwen3.6-0.5B),而不是用内置的 MTP head,这样兼容性和显存分配可能会更好。 -