(双卡指南) 最丐 Qwen3.6-27b - 3000 元双 RTX 3060 - 50t/s
-
注,作者提醒,SPLIT_MODE_TENSOR不能开启kv量化,以下内容仅作参考
不错的尝试,可以尝试把kv量化调整到q8,这样24GB显存放下128K的上下文应该不是问题。
--cache-type-k q8_0
--cache-type-v q8_0q8量化的kv,困惑度上升的不是很多,远低于你从q4_k_m到q4_k_s上升的困惑度。
所以可以试试q4km+kv8比特量化的组合
-
@stakira 研究了下,有人就这个问题提交了pr,目前看还没有被处理
https://github.com/ggerganov/llama.cpp/pull/23225
应该对于多卡用户是个好消息
-
@tommam 理论上 Gen4 x4 就相当于 Gen3 x8 了,很多新一点的主板是有的。比如 1 x PCIe 4.0 x16 + 1 x PCIe 3.0 x16,或者 1 x PCIe 5.0 x16 + 1 x PCIe 4.0 x4。不是非得 x8+x8。
随便挑一个 华硕TUF GAMING B760M-PLUS D4重炮手,就是 Gen5 x16 + Gen4 x4。

这种配置近期似乎比较流行。但 Gen4 x4 那一路走的是芯片组不是 CPU,可能会有一点影响。
主板支持 PCIe 通道拆分的话可以买线拆分成 Gen5 x8+x8。
-
@stakira 研究了下,有人就这个问题提交了pr,目前看还没有被处理
https://github.com/ggerganov/llama.cpp/pull/23225
应该对于多卡用户是个好消息
-
注意:以下方法,双 N 卡的,最弱超过 3060 12GB 的,统统都可以尝试。
虽然入手了 7900 xtx,但实测下来感觉算力发挥很不稳定。开 MTP 后 decode 确实可以达到 40-60 t/s,但 prefill 怎么也快不起来。无论 rocm 还是 vulkan,prefill 速度相当不稳定,哪怕是长段 prompt 最多也就 500+ t/s,常常只能跑到 300+ t/s。
一直手痒想试试极限丐版 24GB 双 3060,正好这几天以合理的价格淘到了第二张。话不多说,拆掉 7900 xtx,上机实测。
测试配置
- 测试平台:i7 4770k + 技嘉 GA-Z87MX-D3H
- 相当古董的平台了,用了十多年。值得注意的是它支持 SLI,两条主 PCIE 插槽同时使用时等效于两条 PCIE 3.0 x8 插槽。较新的主板似乎很少有这种分配,但不少会有一条满速 PCIE 5.0 x16 加一条 PCIE 4.0 x4。总所周知 PCIE 4.0 x4 等效于 PCIE 3.0 x8。所以这个平台跑双卡的 PCIE 条件和较新的主板其实是相同的。
- 显示器插主板用集显
- 系统:Kubuntu 24.04
- CUDA: 13.2
- 模型:
- unsloth/Qwen3.6-27B-MTP-GGUF
- unsloth/Qwen3.6-27B-GGUF
- 量化:Qwen3.6-27B-Q4_K_S.gguf
- 软件:llama.cpp 5/25/2026 master 自行编译 CUDA 版本,官方没有预编译Linux CUDA版本下载
- 前置安装
sudo apt install nvidia-cuda-toolkit
- 前置安装
- 配置(详细配置见帖子最后):
- tensor parallel
-sm tensor -ts 1,1 -sm tensor和-ctk-ctv没法同时开,也就是无法量化 kv cache,只能开到 64k 上下文。我一般需要开 160k 上下文,这就有点难受了(更新:打上补丁可以开到 128k 上下文)--spec-type draft-mtp --spec-draft-n-max 1这个配置比较稳定,--spec-draft-n-max 2很容易跑一段时间后因为瞬时显存消耗过大 OOM。
- tensor parallel
实测记录
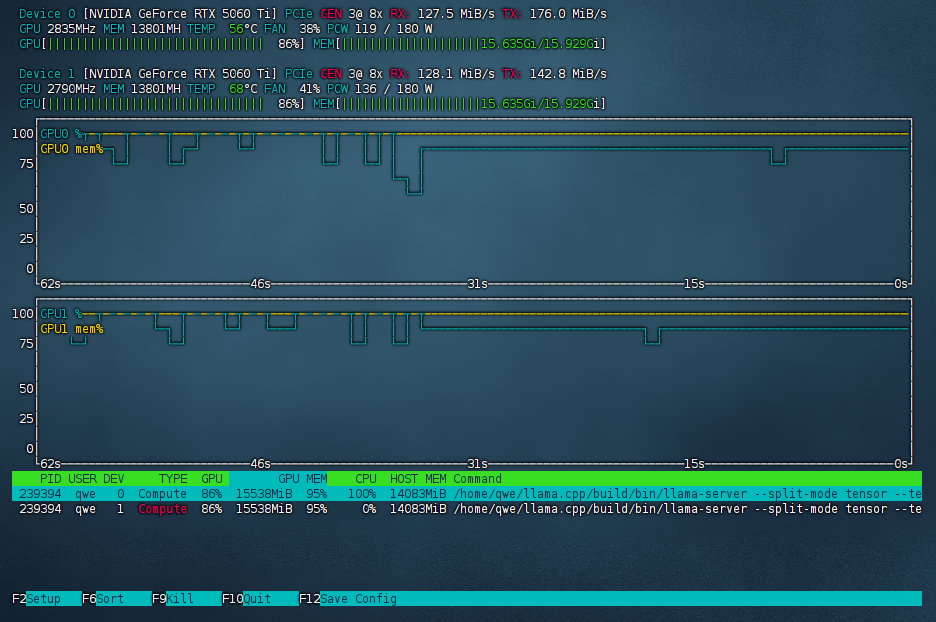
2.16.262.271 I slot print_timing: id 0 | task 701 | prompt eval time = 3056.70 ms / 1394 tokens ( 2.19 ms per token, 456.05 tokens per second) 2.16.262.276 I slot print_timing: id 0 | task 701 | eval time = 22538.95 ms / 975 tokens ( 23.12 ms per token, 43.26 tokens per second) 2.16.262.277 I slot print_timing: id 0 | task 701 | total time = 25595.65 ms / 2369 tokens 2.16.262.291 I slot print_timing: id 0 | task 701 | graphs reused = 1016 2.16.262.292 I slot print_timing: id 0 | task 701 | draft acceptance = 0.77618 ( 593 accepted / 764 generated) 2.16.262.310 I statistics draft-mtp: #calls(b,g,a) = 10 1038 1038, #gen drafts = 1038, #acc drafts = 959, #gen tokens = 2076, #acc tokens = 1792, dur(b,g,a) = 0.018, 8380.839, 3.772 ms 2.16.263.267 I slot release: id 0 | task 701 | stop processing: n_tokens = 12343, truncated = 0可以看到,在 12k 的实际上下文长度下,pp 456.05 t/s,tg 43.26 t/s。初始速度甚至高达 pp 600+ t/s,tg 50 t/s。这个速度大大超出了我的预料。虽然没有 7900 xtx 的最大速度快,但速度极其稳定,GPU 占用率长时间稳定 100%,不得不说还是 CUDA 成熟。
另外,关闭 MTP 后 context 可以开到 96k,pp 速度更快,tg 速度下降到 31 t/s,也相当不错了。
Context Window Prefill (pp) Generation (tg) MTP 初始峰值 64k 620 t/s 50 t/s MTP 32k 64k 482 t/s 36.36 t/s 关闭 MTP 初始峰值 96k 620 t/s 31 t/s 关闭 MTP 20k 96k 605 t/s 29.10 t/s 关闭 MTP 50k 96k 438 t/s 26.59 t/s 总结
优点
- 性价比极高,目测闲鱼 3000 以内能够搞定。
- CUDA 生态完善,GPU 占用率长时间稳定 100%,编译完成后不用折腾,省心。
- 3060 身材苗条,有单、双风扇短版,大部分 ATX 和 mATX 主板、机箱都无压力。
缺点
- SPLIT_MODE_TENSOR 暂时无法使用 kv cache 量化,导致 24GB 仍稍显不足。但这肯定不是小众需求,简单 q8 也能翻倍到 128k / 192k,未来可期。一旦 kv 量化解决,我就可以把 7900 xtx 淘汰了。
推论
- 双 16GB、速度稍快的卡,比如 4060Ti、5060Ti,虽然性价比会下降,但效果只会更好。还是那句话,CUDA 发挥稳定,省心。同样是 32GB,比跛脚 AI PRO R9700 肯定快得多,价格还稍低。
- 更新:外网有人根据本帖配置用双 5060Ti 跑出 pp 700 t/s, tg 65 t/s。
其它
- vllm 也有简单尝试,但 vllm 可能是对 VRAM 紧张的场景优化不佳,怎么跑都 OOM。且 vllm 启动太慢了,调试麻烦,不折腾了。
附录
详细配置
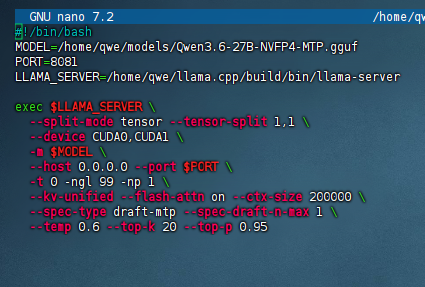
--no-mmproj-offload \ -dev CUDA0,CUDA1 -sm tensor -ts 1,1 \ --fit off \ --host 0.0.0.0 --port "$PORT" \ -t 0 -ngl 99 -np 1 \ --kv-unified --flash-attn on --ctx-size 64000 \ # 或 96000 --spec-type draft-mtp --spec-draft-n-max 1 \ # 或去掉 -rea on \ --temp 0.6 --top-k 20 --top-p 0.95 --min-p 0.0 --repeat-penalty 1.0 --presence-penalty 0.0
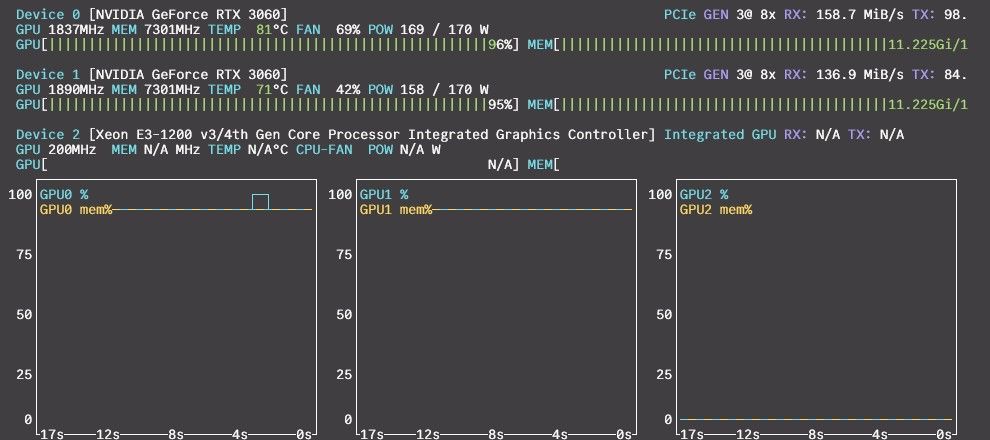
虽然入手了 7900 xtx,但实测下来感觉算力发挥很不稳定。开 MTP 后 decode 确实可以达到 40-60 t/s,但 prefill 怎么也快不起来。无论 rocm 还是 vulkan,prefill 速度相当不稳定,哪怕是长段 prompt 最多也就 500+ t/s,常常只能跑到 300+ t/s。
一直手痒想试试极限丐版 24GB 双 3060,正好这几天以合理的价格淘到了第二张。话不多说,拆掉 7900 xtx,上机实测。
测试配置
- 测试平台:i7 4770k + 技嘉 GA-Z87MX-D3H
- 相当古董的平台了,用了十多年。值得注意的是它支持 SLI,两条主 PCIE 插槽同时使用时等效于两条 PCIE 3.0 x8 插槽。较新的主板似乎很少有这种分配,但不少会有一条满速 PCIE 5.0 x16 加一条 PCIE 4.0 x4。总所周知 PCIE 4.0 x4 等效于 PCIE 3.0 x8。所以这个平台跑双卡的 PCIE 条件和较新的主板其实是相同的。
- 显示器插主板用集显
- 系统:Kubuntu 24.04
- CUDA: 13.2
- 模型:
- unsloth/Qwen3.6-27B-MTP-GGUF
- unsloth/Qwen3.6-27B-GGUF
- 量化:Qwen3.6-27B-Q4_K_S.gguf
- 软件:llama.cpp 5/25/2026 master 自行编译 CUDA 版本,官方没有预编译Linux CUDA版本下载
- 前置安装
sudo apt install nvidia-cuda-toolkit
- 前置安装
- 配置(详细配置见帖子最后):
- tensor parallel
-sm tensor -ts 1,1 -sm tensor和-ctk-ctv没法同时开,也就是无法量化 kv cache,只能开到 64k 上下文。我一般需要开 160k 上下文,这就有点难受了--spec-type draft-mtp --spec-draft-n-max 1这个配置比较稳定,--spec-draft-n-max 2很容易跑一段时间后因为瞬时显存消耗过大 OOM。
- tensor parallel
实测记录
2.16.262.271 I slot print_timing: id 0 | task 701 | prompt eval time = 3056.70 ms / 1394 tokens ( 2.19 ms per token, 456.05 tokens per second) 2.16.262.276 I slot print_timing: id 0 | task 701 | eval time = 22538.95 ms / 975 tokens ( 23.12 ms per token, 43.26 tokens per second) 2.16.262.277 I slot print_timing: id 0 | task 701 | total time = 25595.65 ms / 2369 tokens 2.16.262.291 I slot print_timing: id 0 | task 701 | graphs reused = 1016 2.16.262.292 I slot print_timing: id 0 | task 701 | draft acceptance = 0.77618 ( 593 accepted / 764 generated) 2.16.262.310 I statistics draft-mtp: #calls(b,g,a) = 10 1038 1038, #gen drafts = 1038, #acc drafts = 959, #gen tokens = 2076, #acc tokens = 1792, dur(b,g,a) = 0.018, 8380.839, 3.772 ms 2.16.263.267 I slot release: id 0 | task 701 | stop processing: n_tokens = 12343, truncated = 0可以看到,在 12k 的实际上下文长度下,pp 456.05 t/s,tg 43.26 t/s。初始速度甚至高达 pp 600+ t/s,tg 50 t/s。这个速度大大超出了我的预料。虽然没有 7900 xtx 的最大速度快,但速度极其稳定,GPU 占用率长时间稳定 100%,不得不说还是 CUDA 成熟。
另外,关闭 MTP 后 context 可以开到 96k,pp 速度更快,tg 速度下降到 31 t/s,也相当不错了。
Context Window Prefill (pp) Generation (tg) MTP 初始峰值 64k 620 t/s 50 t/s MTP 32k 64k 482 t/s 36.36 t/s 关闭 MTP 初始峰值 96k 620 t/s 31 t/s 关闭 MTP 20k 96k 605 t/s 29.10 t/s 关闭 MTP 50k 96k 438 t/s 26.59 t/s 总结
优点
- 性价比极高,目测闲鱼 3000 以内能够搞定。
- CUDA 生态完善,GPU 占用率长时间稳定 100%,编译完成后不用折腾,省心。
- 3060 身材苗条,有单、双风扇短版,大部分 ATX 和 mATX 主板、机箱都无压力。
缺点
- SPLIT_MODE_TENSOR 暂时无法使用 kv cache 量化,导致 24GB 仍稍显不足。但这肯定不是小众需求,简单 q8 也能翻倍到 128k / 192k,未来可期。一旦 kv 量化解决,我就可以把 7900 xtx 淘汰了。更新:经 @kop-wang 提醒,回退到 PR#22616 之前,打上 PR#23225 补丁,开 MTP 可以开到 128k 上下文。
推论
- 双 16GB、速度稍快的卡,比如 4060Ti、5060Ti,虽然性价比会下降,但效果只会更好。还是那句话,CUDA 发挥稳定,省心。同样是 32GB,比跛脚 AI PRO R9700 肯定快得多,价格还稍低。
- 更新:外网有人根据本帖配置用双 5060Ti 跑出 pp 700 t/s, tg 65 t/s。
- 主要是 SPLIT_MODE_TENSOR 立功了。但凡双 N 卡的,最小超过 12 GB 的,统统都可以尝试。
其它
- vllm 也有简单尝试,但 vllm 可能是对 VRAM 紧张的场景优化不佳,怎么跑都 OOM。且 vllm 启动太慢了,调试麻烦,不折腾了。
附录
详细配置
--no-mmproj-offload \ -dev CUDA0,CUDA1 -sm tensor -ts 1,1 \ --fit off \ --host 0.0.0.0 --port "$PORT" \ -t 0 -ngl 99 -np 1 \ --kv-unified --flash-attn on --ctx-size 64000 \ # 或 96000 --spec-type draft-mtp --spec-draft-n-max 1 \ # 或去掉 -rea on \ --temp 0.6 --top-k 20 --top-p 0.95 --min-p 0.0 --repeat-penalty 1.0 --presence-penalty 0.0但 prefill 怎么也快不起来。无论 rocm 还是 vulkan,prefill 速度相当不稳定,哪怕是长段 prompt 最多也就 500+ t/s,常常只能跑到 300+ t/s。
这个信息很关键啊,ai了一下:
作为一张拥有 960 GB/s 显存带宽、24GB VRAM 的旗舰级显卡,7900 XTX 跑出 300~500 t/s 的 Prefill(首字延迟/提示词处理)速度绝对是不正常的。正常情况下,在全显存(无内存交叉)时,7900 XTX 处理长文本的 Prefill 应该能飙到 1500~2000+ t/s。相比之下,3060 哪怕带宽只有 360 GB/s,但在 CUDA 生态下其算力核心利用率非常稳定。7900 XTX Prefill 速度慢且极度不稳定的根源,不在于硬件本身,而在于 AMD 软件栈在特定推理框架下的 Kernel(算力核心)调度、内存分配以及算子缺失。
致命伤:FlashAttention 算子没有真正跑起来Prefill 阶段是算力受限(Compute-bound)的,需要极其密集的矩阵乘法。
Nvidia 显卡默认使用极致优化的 FlashAttention(甚至 FlashAttention-3)。
痛点:在 ROCm 或 Vulkan 下,如果框架没有正确调用专门针对 RDNA3(GFX1100)优化的 FlashAttention 算子,系统会自动降级去跑极慢的传统 SDPA(PyTorch 默认注意力)或者非对齐算子。这会导致显卡空有几百 W 功耗,算力利用率却极低。解决办法(vLLM):在启动 vLLM 时,检查日志中关于 Attention Backend 的输出。确保其使用的是针对 AMD 优化的后端。可以通过环境变量强制指定:bashexport VLLM_ATTENTION_BACKEND=TRITON_ATTN
或者在最新版本的 vLLM 尝试
export VLLM_USE_FLASH_ATTN=1
请谨慎使用此类代码。
(注:如果使用 Llama.cpp,请确保编译时开启了 GGML_HIPBLAS=ON 或者是最新的开源统一注意力 AITER)。 - 测试平台:i7 4770k + 技嘉 GA-Z87MX-D3H
-
@tommam 理论上 Gen4 x4 就相当于 Gen3 x8 了,很多新一点的主板是有的。比如 1 x PCIe 4.0 x16 + 1 x PCIe 3.0 x16,或者 1 x PCIe 5.0 x16 + 1 x PCIe 4.0 x4。不是非得 x8+x8。
随便挑一个 华硕TUF GAMING B760M-PLUS D4重炮手,就是 Gen5 x16 + Gen4 x4。
这种配置近期似乎比较流行。但 Gen4 x4 那一路走的是芯片组不是 CPU,可能会有一点影响。
主板支持 PCIe 通道拆分的话可以买线拆分成 Gen5 x8+x8。
 。
。