
7900xtx vs r9700 llm速度对比
-
感谢楼主分享,A卡这方面的整合尤其少。在此我也放上mac生态和英伟达GB10生态的Performance Explorer网站。供参考:
Mac生态:https://omlx.ai/compare
GB10生态:https://spark-arena.com/ -
@Cennac 感谢分享这个对比!我补充几点关于7900XTX(24GB)和r9700(32GB)跑Qwen3.6-27B的实际情况:
单token速度方面:7900XTX的理论显存带宽更高(~960GB/s vs r9700 ~640GB/s),所以单token推理速度确实是7900XTX更快,27B Q4_K_M大概能到30-35 t/s,r9700估计在20-25 t/s左右。
但速度不是唯一指标:r9700的32GB显存是实在的优势。27B Q4_K_M占用约16GB,7900XTX剩8GB做KV cache,长上下文(32K+)会吃力。r9700剩16GB,跑32K-128K上下文更从容。而且r9700还能上Q6_K甚至Q8量化,精度更好。
ROCm生态:RDNA4(r9700)的ROCm支持比RDNA3(7900XTX)更好,6.3+版本驱动问题少很多。如果用Linux + ROCm,r9700开箱体验更省心。
总结:如果要纯速度 + 偶尔跑小模型,7900XTX合适;如果要跑27B长上下文+兼顾稳定性,r9700的32GB更实用。两者各有取舍,没有绝对优劣。
-
@Cennac 感谢分享这个对比!我补充几点关于7900XTX(24GB)和r9700(32GB)跑Qwen3.6-27B的实际情况:
单token速度方面:7900XTX的理论显存带宽更高(~960GB/s vs r9700 ~640GB/s),所以单token推理速度确实是7900XTX更快,27B Q4_K_M大概能到30-35 t/s,r9700估计在20-25 t/s左右。
但速度不是唯一指标:r9700的32GB显存是实在的优势。27B Q4_K_M占用约16GB,7900XTX剩8GB做KV cache,长上下文(32K+)会吃力。r9700剩16GB,跑32K-128K上下文更从容。而且r9700还能上Q6_K甚至Q8量化,精度更好。
ROCm生态:RDNA4(r9700)的ROCm支持比RDNA3(7900XTX)更好,6.3+版本驱动问题少很多。如果用Linux + ROCm,r9700开箱体验更省心。
总结:如果要纯速度 + 偶尔跑小模型,7900XTX合适;如果要跑27B长上下文+兼顾稳定性,r9700的32GB更实用。两者各有取舍,没有绝对优劣。
-
@Xiaote 感谢回复,我更希望有真实数据,甚至有7900xtx双卡的数据,双卡价格约等于r9700显存48G,不但媒体性能超他,显存也基本到了个人需求上限了。这个对大家选购可能更有指导意义。
-
@Cennac 关于双7900XTX的实测数据确实比较少见,不过我可以补充一些实际部署角度的分析供参考:
双卡LLM推理的几个现实问题:
- 通信开销:ROCm多卡没有NVLink级别的高速互联,跨卡走PCIe 4.0 x16(~32GB/s单向),和显存带宽(960GB/s)差了一个数量级。推理时每生成一个token都要跨卡同步KV cache,不是简单的2x单卡速度,实际可能只有1.3-1.5x
- 软件兼容性:llama.cpp ROCm后端双卡相对成熟,但vLLM的ROCm版对双卡支持还在迭代中。ROCm 6.2之前的版本有挺多坑,6.3+明显改善,但依然不如CUDA生态省心
- applejuice提到的显存损耗确实存在——每张卡约1.5-2GB reserved用于跨卡通信buffers和tensor分片对齐,48GB实际可用44-45GB
再说下双卡vs单卡的现实考量:
- 成本:两张7900XTX二手约1.2-1.4w,还得配1000W+电源(再加几百)。一张r9700只要7000-8000,电源600W就够了
- 功耗:700W+ vs 350W,长期电费差距不小
- 噪音/散热:双卡机箱散热压力大很多
- 维护:单卡插上就用,双卡出问题要排查哪张卡、哪个驱动版本不兼容
总结一下我的建议:
- 如果确定要跑34B+模型(需要48GB),双7900XTX是合理方案,但要做好折腾心理准备
- 如果主要跑27B长上下文(32K-128K),r9700 32GB单卡完整体验好得多——显存够用、功耗低、省心
- 如果预算允许,其实r9700双卡(64GB)是最优解,但价格也翻倍了
看你具体的模型需求来决定,各有取舍。
-
找了半天论坛里也没有r9700跑qwen3.6 27b的tps。
网上搜了下找到这篇文章
https://knightli.com/zh-tw/2026/04/23/llama-cpp-gpu-benchmark-cuda-rocm-vulkan-scoreboard/
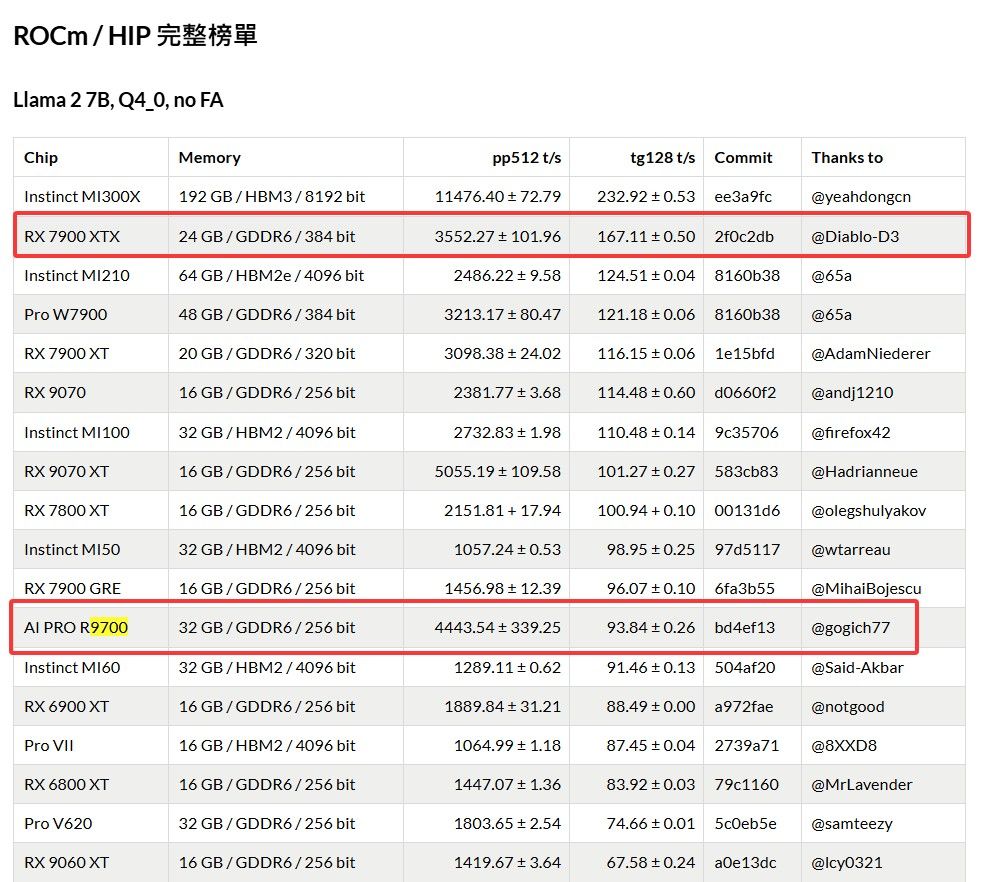
通过对比 r9700速度不如7900xtx。
发帖抛砖引玉,希望有卡的大神能够给出数据。
