
7900 XTX + Qwen3.6-27B:Ubuntu + ROCm / Vulkan / MTP 64/128/256K 全部實測整理
-
簡單測試可以, 如果想嘗試多的話可以用llama.cpp的llama-bench
或者跨平臺的llama-benchy
畢竟誰都不想在Agent用到一半然後自己的模型引擎就挂掉吧?
我用一下比較熟悉的vllm + llama-benchy作爲例子
這個是在vllm底下一個超長上下文的測試
uv run llama-benchy \ --base-url "http://localhost:7380/v1" \ --model "Qwen3.6-27B-heretic-v2-mtp-int4-AutoRound" \ --tokenizer "$HOME/vllm/models/lyf/Qwen3.6-27B-heretic-v2-mtp-int4-AutoRound" \ --pp 2048 \ --tg 480 \ --depth 0 1000 5000 10000 20000 50000 100000 150000 200000 \ --latency-mode generation \ --skip-coherence \ --concurrency 1相對應的llama-bench大約會是這樣 (沒實測, 單純看官方文件推斷)
llama-bench \ -m /path/to/model.gguf \ -pg 2048,480 \ -d 0,1000,5000,10000,20000,50000,100000,150000,200000 \ #各種長度, 最好實驗到啓動時上下文參數的8到9成 -r 3 \ # 重複3次, 會有正負數 -ngl 999 \ #全塞到VRAM裏 -fa auto \ -b 2048 \ -ub 512就會有類似的Markdown結果 (官方文件提供)
| model | size | params | backend | ngl | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | --: | ---------- | ---------------: | | llama 7B mostly Q4_0 | 3.56 GiB | 6.74 B | CUDA | -1 | tg 128 | 132.19 ± 0.55 | | llama 7B mostly Q4_0 | 3.56 GiB | 6.74 B | CUDA | -1 | tg 256 | 129.37 ± 0.54 | | llama 7B mostly Q4_0 | 3.56 GiB | 6.74 B | CUDA | -1 | tg 512 | 123.83 ± 0.25 | | llama 13B mostly Q4_0 | 6.86 GiB | 13.02 B | CUDA | -1 | tg 128 | 82.17 ± 0.31 | | llama 13B mostly Q4_0 | 6.86 GiB | 13.02 B | CUDA | -1 | tg 256 | 80.74 ± 0.23 | | llama 13B mostly Q4_0 | 6.86 GiB | 13.02 B | CUDA | -1 | tg 512 | 78.08 ± 0.07 | -
@566656661 结果如下,让codex替我跑的:
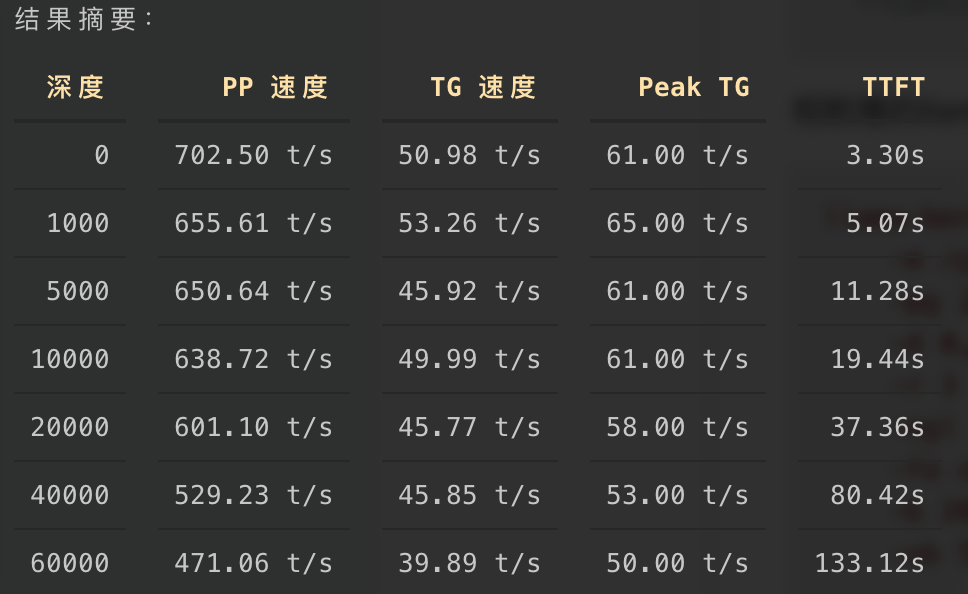
-
@566656661 又测试了下128K上下文的,也是稳稳过:
llama-server \ -m /root/models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf \ --mmproj /root/models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf \ -c 131072 \ --parallel 1 \ -b 2048 \ -ub 256 \ -fa 1 \ -ngl 99 \ -t 22 \ --cache-type-k q8_0 \ --cache-type-v q4_0 \ --spec-type draft-mtp \ --spec-draft-n-max 2 \ --no-mmap \ --tensor-split 0 \ --temp 1.0 \ --top-p 0.95 \ --top-k 20 \ --host 0.0.0.0 \ --port 8080测试命令:
uvx llama-benchy \ --base-url "http://127.0.0.1:8080/v1" \ --model "Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf" \ --tokenizer "Qwen/Qwen3-32B" \ --pp 2048 \ --tg 480 \ --depth 0 1000 5000 10000 20000 40000 60000 80000 100000 120000 \ --runs 1 \ --latency-mode generation \ --skip-coherence \ --concurrency 1 \ --save-result /root/bench-results/qwen36-27b-llamacpp-amd-rx7900xtx-128k.md \ --format md结果:
model test t/s peak t/s ttfr (ms) est_ppt (ms) e2e_ttft (ms) Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf pp2048 680.59 ± 0.00 3338.06 ± 0.00 3098.77 ± 0.00 3338.06 ± 0.00 Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf tg480 54.05 ± 0.00 64.00 ± 0.00 Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf pp2048 @ d1000 653.98 ± 0.00 5002.45 ± 0.00 4763.16 ± 0.00 5002.45 ± 0.00 Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf tg480 @ d1000 56.33 ± 0.00 69.00 ± 0.00 Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf pp2048 @ d5000 651.71 ± 0.00 11268.68 ± 0.00 11029.39 ± 0.00 11268.68 ± 0.00 Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf tg480 @ d5000 54.48 ± 0.00 66.00 ± 0.00 Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf pp2048 @ d10000 640.50 ± 0.00 19474.35 ± 0.00 19235.06 ± 0.00 19474.35 ± 0.00 Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf tg480 @ d10000 43.98 ± 0.00 65.00 ± 0.00 Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf pp2048 @ d20000 603.14 ± 0.00 37515.97 ± 0.00 37276.68 ± 0.00 37515.97 ± 0.00 Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf tg480 @ d20000 50.28 ± 0.00 61.00 ± 0.00 Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf pp2048 @ d40000 531.14 ± 0.00 80935.83 ± 0.00 80696.54 ± 0.00 80935.83 ± 0.00 Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf tg480 @ d40000 48.03 ± 0.00 56.00 ± 0.00 Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf pp2048 @ d60000 471.59 ± 0.00 134568.39 ± 0.00 134329.10 ± 0.00 134568.39 ± 0.00 Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf tg480 @ d60000 43.79 ± 0.00 54.00 ± 0.00 Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf pp2048 @ d80000 423.74 ± 0.00 197853.56 ± 0.00 197614.27 ± 0.00 197853.56 ± 0.00 Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf tg480 @ d80000 37.63 ± 0.00 46.00 ± 0.00 Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf pp2048 @ d100000 384.01 ± 0.00 271566.90 ± 0.00 271327.61 ± 0.00 271566.90 ± 0.00 Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf tg480 @ d100000 32.81 ± 0.00 42.00 ± 0.00 Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf pp2048 @ d120000 351.21 ± 0.00 355123.65 ± 0.00 354884.35 ± 0.00 355123.65 ± 0.00 Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf tg480 @ d120000 32.44 ± 0.00 39.00 ± 0.00 -
把--spec-draft-n-max 2修改为3以后,又测试了下:

128k n-max=3 d120000 Benchmark
LLM Command
llama-server \ -m /root/models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf \ --mmproj /root/models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf \ -c 131072 \ --parallel 1 \ -b 2048 \ -ub 256 \ -fa 1 \ -ngl 99 \ -t 22 \ --cache-type-k q8_0 \ --cache-type-v q4_0 \ --spec-type draft-mtp \ --spec-draft-n-max 3 \ --no-mmap \ --temp 1.0 \ --top-p 0.95 \ --top-k 20 \ --host 0.0.0.0 \ --port 8080Test Command
uvx llama-benchy \ --base-url "http://127.0.0.1:8080/v1" \ --model "Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf" \ --tokenizer "Qwen/Qwen3-32B" \ --pp 2048 \ --tg 480 \ --depth 120000 \ --runs 1 \ --latency-mode generation \ --skip-coherence \ --concurrency 1 \ --save-result /root/bench-results/qwen36-27b-llamacpp-amd-rx7900xtx-128k-nmax3-d120000.md \ --format mdBenchmark Result
test t/s peak t/s ttfr est_ppt e2e_ttft pp2048 @ d120000 353.80 352493.90 ms 352253.89 ms 352493.90 ms tg480 @ d120000 35.26 48.00 Server Timing
prompt eval time = 351710.86 ms / 124629 tokens prompt speed = 354.35 tokens/s eval time = 13601.37 ms / 480 tokens generation speed = 35.29 tokens/s total time = 365312.23 ms / 125109 tokens draft acceptance = 0.70961 accepted/generated = 325 / 458 truncated = 0写代码开始速度能上70+,稳定在50+,很满足了
-
后天才能到货。。。。让你搞的我热血沸腾了。我将在 ubuntu 上跑。版本还是24.太新的版本都不适合我。前期测试 有可能上个桌面版 方便 给你们做报告。或者直接在 Mac上 调用。新卡到了我 Windows 跑下体质。
-
我补充的方案:对。7900XTX 只暴露算力模式接口,Hermes 负责调度。
7900XTX 算力节点准备
两个 systemd 服务单元(互斥,同一端口):
/etc/systemd/system/[email protected]:[Unit] Description=LLaMA Server %i mode After=network.target [Service] Type=simple ExecStartPre=/bin/sleep 2 ExecStart=/usr/local/bin/llama-server \ -m /root/models/Qwen3.6-27B-IQ4_XS.gguf \ -ngl 99 --no-warmup --host 0.0.0.0 --port 8080 \ %i Restart=on-failure [Install] WantedBy=multi-user.target启动参数文件:
/etc/systemd/system/[email protected]/override.conf:[Service] ExecStart= ExecStart=/usr/local/bin/llama-server \ -m /root/models/Qwen3.6-27B-IQ4_XS.gguf \ -c 8192 --cache-type-k q8_0 --cache-type-v q8_0 \ -ngl 99 --no-warmup --host 0.0.0.0 --port 8080/etc/systemd/system/[email protected]/override.conf:[Service] ExecStart= ExecStart=/usr/local/bin/llama-server \ -m /root/models/Qwen3.6-27B-IQ4_XS.gguf \ -c 131072 --cache-type-k q4_0 --cache-type-v q8_0 \ -ngl 99 --no-warmup --host 0.0.0.0 --port 8080
Hermes 可调用的切换命令
# 切 8K 交互模式 systemctl stop llama-dev@128k; systemctl start llama-dev@8k # 切 128K 批处理模式 systemctl stop llama-dev@8k; systemctl start llama-dev@128kHermes 切完后等 5 秒,curl http://7900xtx-ip:8080/health 确认恢复即可下发任务。
7900XTX 只暴露 8K/128K 两个 systemd 服务单元,Hermes 根据任务类型 systemctl 切换,等端口恢复后调 API。算力节点无状态,切换逻辑全在 Hermes 侧。
这样基本就可以跑了。具体效果我会出一版帖子。
这个方案 可以实现 工作机 Mac mini Hermes 工作的需要。 -
我补充的方案:对。7900XTX 只暴露算力模式接口,Hermes 负责调度。
7900XTX 算力节点准备
两个 systemd 服务单元(互斥,同一端口):
/etc/systemd/system/[email protected]:[Unit] Description=LLaMA Server %i mode After=network.target [Service] Type=simple ExecStartPre=/bin/sleep 2 ExecStart=/usr/local/bin/llama-server \ -m /root/models/Qwen3.6-27B-IQ4_XS.gguf \ -ngl 99 --no-warmup --host 0.0.0.0 --port 8080 \ %i Restart=on-failure [Install] WantedBy=multi-user.target启动参数文件:
/etc/systemd/system/[email protected]/override.conf:[Service] ExecStart= ExecStart=/usr/local/bin/llama-server \ -m /root/models/Qwen3.6-27B-IQ4_XS.gguf \ -c 8192 --cache-type-k q8_0 --cache-type-v q8_0 \ -ngl 99 --no-warmup --host 0.0.0.0 --port 8080/etc/systemd/system/[email protected]/override.conf:[Service] ExecStart= ExecStart=/usr/local/bin/llama-server \ -m /root/models/Qwen3.6-27B-IQ4_XS.gguf \ -c 131072 --cache-type-k q4_0 --cache-type-v q8_0 \ -ngl 99 --no-warmup --host 0.0.0.0 --port 8080
Hermes 可调用的切换命令
# 切 8K 交互模式 systemctl stop llama-dev@128k; systemctl start llama-dev@8k # 切 128K 批处理模式 systemctl stop llama-dev@8k; systemctl start llama-dev@128kHermes 切完后等 5 秒,curl http://7900xtx-ip:8080/health 确认恢复即可下发任务。
7900XTX 只暴露 8K/128K 两个 systemd 服务单元,Hermes 根据任务类型 systemctl 切换,等端口恢复后调 API。算力节点无状态,切换逻辑全在 Hermes 侧。
这样基本就可以跑了。具体效果我会出一版帖子。
这个方案 可以实现 工作机 Mac mini Hermes 工作的需要。 -
8K/128K
8K是对话常态化
128K 作为长任务分析。比如多文件的处理。 是这么用的。 -
今天试了下vulkan,qwen27b q4,显卡7900xtx,64k上下文,跑hermes agent,prefill 吊打rocm环境。都是从0开始加载50k和60k的提示词,完全不像ai和社区说的vulkan的首字慢。
vulkan的:prompt processing, n_tokens = 62284, progress = 1.00, t = 108.65 s / 573.23 tokens per second
rocm的:prompt processing, n_tokens = 52604, progress = 1.00, t = 314.20 s / 167.42 tokens per second
参数: -mg 0
--temp 0.3
--ctx-size 65536
-b 2048
-ub 2048
--top-p 0.8
--min-p 0.05
--repeat-penalty 1.1
--cache-type-k q8_0
--cache-type-v q8_0
--flash-attn on
--cache-ram -1 --ctx-checkpoints 32 --cache-idle-slots
--parallel 1
--cont-batching
--timeout 600 -
今天试了下vulkan,qwen27b q4,显卡7900xtx,64k上下文,跑hermes agent,prefill 吊打rocm环境。都是从0开始加载50k和60k的提示词,完全不像ai和社区说的vulkan的首字慢。
vulkan的:prompt processing, n_tokens = 62284, progress = 1.00, t = 108.65 s / 573.23 tokens per second
rocm的:prompt processing, n_tokens = 52604, progress = 1.00, t = 314.20 s / 167.42 tokens per second
参数: -mg 0
--temp 0.3
--ctx-size 65536
-b 2048
-ub 2048
--top-p 0.8
--min-p 0.05
--repeat-penalty 1.1
--cache-type-k q8_0
--cache-type-v q8_0
--flash-attn on
--cache-ram -1 --ctx-checkpoints 32 --cache-idle-slots
--parallel 1
--cont-batching
--timeout 600 -
@agi 新手请教,Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf我在huggingface找了一圈也没有找到,你在哪里下载? 在HauhauCS的主页下看到Qwen3.6-27B-Uncensored-HauhauCS-Balanced-Q4_K_P.gguf 没有MTP版本
-
-
我也测试了。这套方案是可行的。

