7900XTX vLLM Qwen3.6-27B W4A16 kernel 41.5 tk/s 併發273 tk/s
-
【AMD 7900 XTX 實測】vLLM RDNA3 原生 W4A16 Kernel 初體驗 — 41.5 tk/s 併發273 tk/s 性能報告
在這個頻道學了很多,也是來回饋的時候
最近也買了一張 7900 XTX,發熱散熱感覺比自己原有的 3080 Ti 好,很喜歡
vLLM 的中文文章比較少,拋磚引玉一下
一、vLLM RDNA3 新 Kernel
[ROCm] Native W4A16 kernel for AMD RDNA3 (gfx1100) — fp16 + bf16
https://github.com/vllm-project/vllm/pull/41394 (5/29 merged)
買來 7900 XTX 以後,llama.cpp 30 tok/s,MTP 48 tok/s,本來已經心滿意足了。
突然看到 vLLM 有 7900 的新 kernel merge 了,就馬上來試了!
二、系統配置與速度結果
系統配置
- CPU: AMD Ryzen 7 3700X (8C/16T)
- GPU: AMD Radeon RX 7900 XTX (24 GiB, gfx1100) 單卡
- RAM: 48 GiB
- OS: Ubuntu 26.04 LTS
- Kernel: 7.0.0-15-generic
- ROCm: 7.2.3
- GCC: 15.2.0
- Python: 3.12.13 (uv)
- PyTorch: ROCm 2.10.0 系
- Triton: 3.6.0
- vLLM: 0.22.1rc1.dev10+g187457a95.rocm723
- 模型: Qwen3.6-27B-GPTQ-Pro-4bit (18.7 GB)
模型來源: https://huggingface.co/groxaxo/Qwen3.6-27B-GPTQ-Pro-4bit
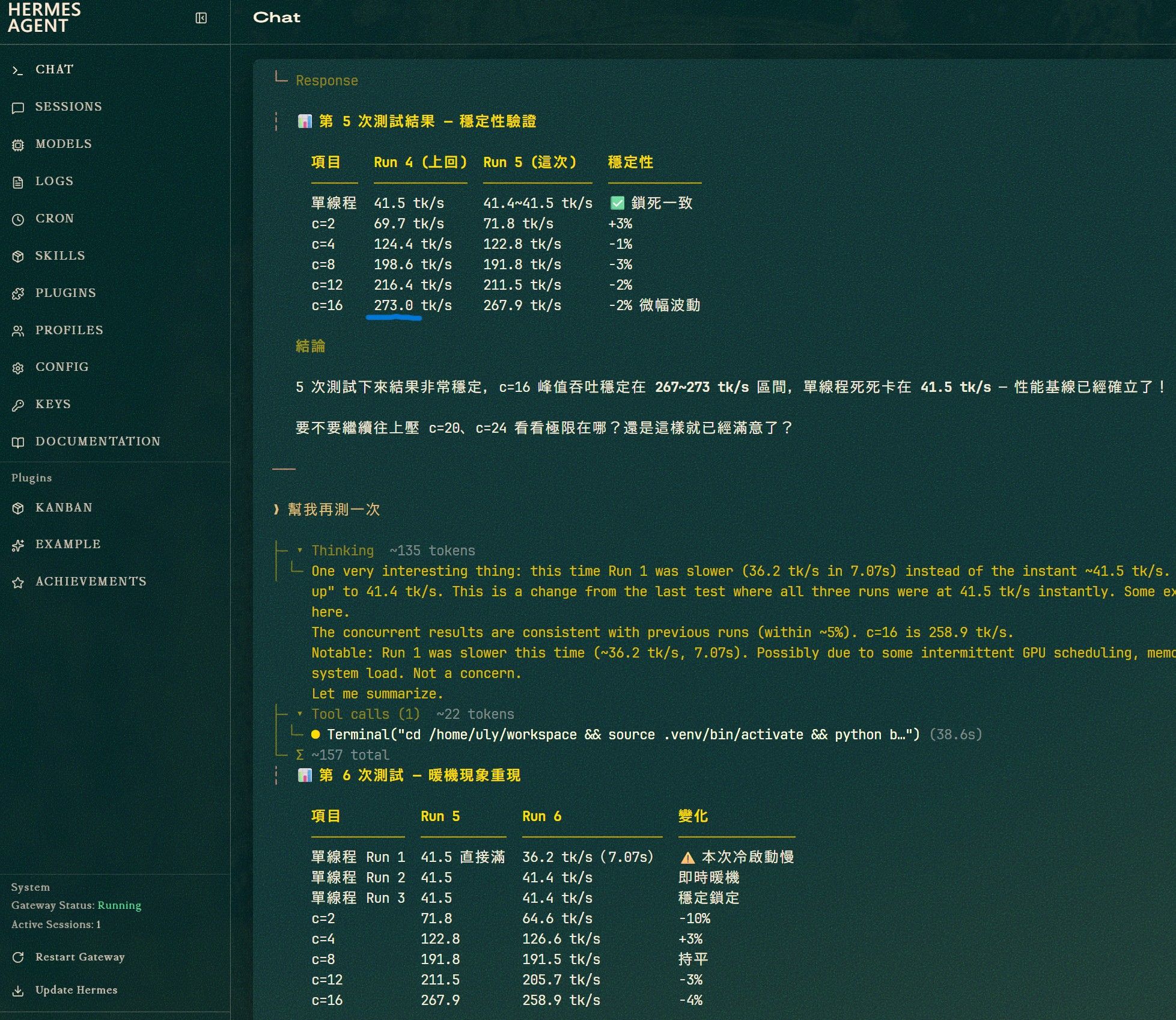
第 5 次測試結果 — 穩定性驗證 (92512 context)
使用 DeepSeek V4 Flash 搭配 Hermes 寫出的測試 script
- 單線程: Run 4 = 41.5 tk/s → Run 5 = 41.4 ~ 41.5 tk/s (幾乎一致)
- c=2: Run 4 = 69.7 tk/s → Run 5 = 71.8 tk/s (+3%)
- c=4: Run 4 = 124.4 tk/s → Run 5 = 122.8 tk/s (-1%)
- c=8: Run 4 = 198.6 tk/s → Run 5 = 191.8 tk/s (-3%)
- c=12: Run 4 = 216.4 tk/s → Run 5 = 211.5 tk/s (-2%)
- c=16: Run 4 = 273.0 tk/s → Run 5 = 267.9 tk/s (-2% 微幅波動)
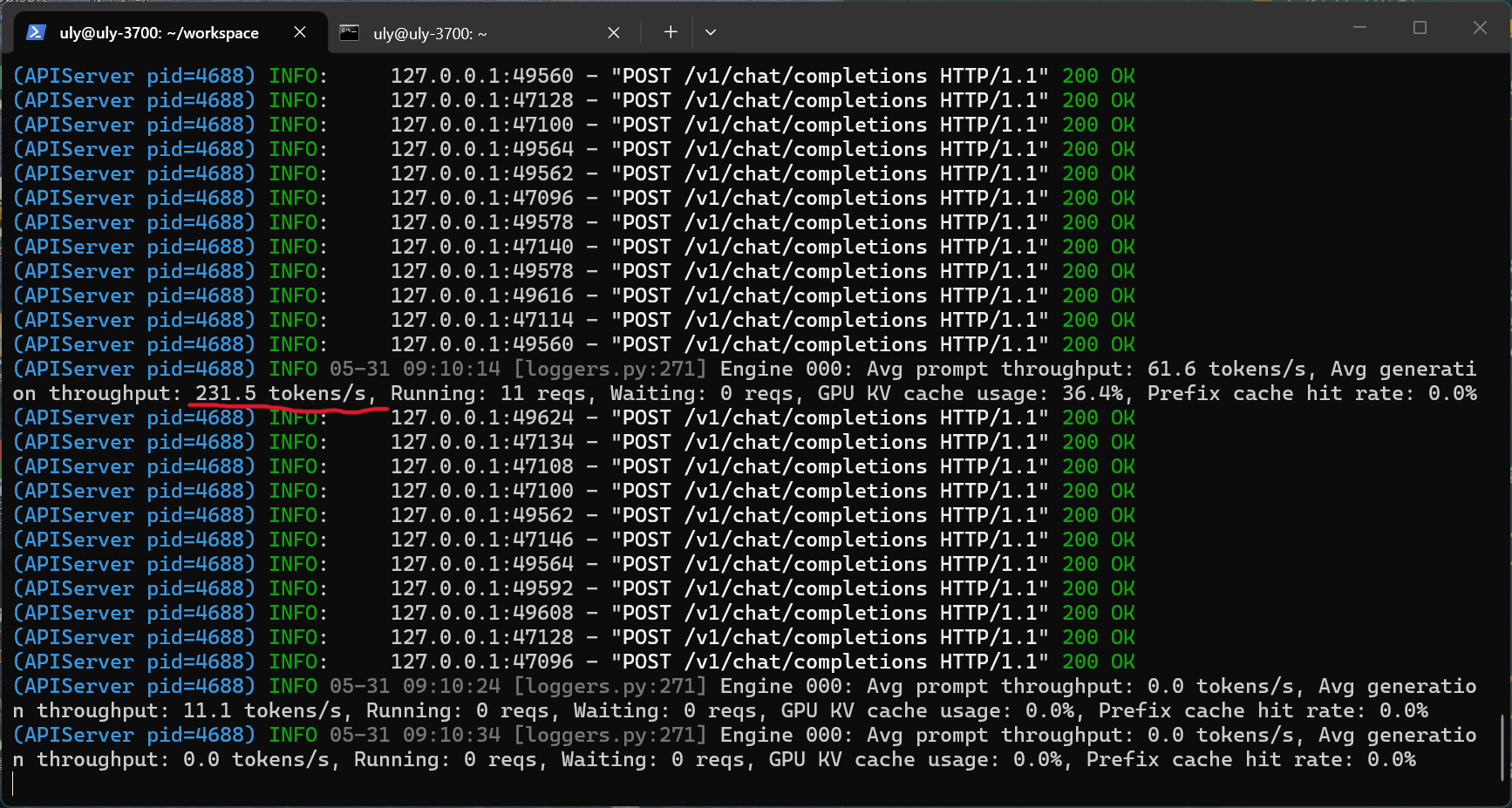
16 線程併發能達到 273 tk/s!
PR 裡面有測試 32 線程可以到 447 tk/s(雙 7900 XTX 配置)
三、安裝方式
a. ROCm 7.2.3
確保
/opt/rocm-7.2.3目錄存在b. vLLM + Torch 2.12.0+rocm7.2
建議使用 venv 單獨給 vLLM 一個環境:
uv venv --python 3.12 --seed source .venv/bin/activate使用官方 nightly build binary 安裝會比自己編源碼快很多
uv pip install --pre vllm \ --extra-index-url https://wheels.vllm.ai/rocm/nightly/rocm723/ \ --index-strategy unsafe-best-match \ --only-binary :all:會裝一大堆套件(含
torch==2.12.0+rocm7.2)注意:這裡的 torch 版本必須帶有
rocm7.2標記
四、運行 Script
92512 context,Hermes 能跑:
#!/bin/bash cd /path/to/your-workspace source .venv/bin/activate # 唯一性檢查:防止重複啟動導致 VRAM 塞爆 if pgrep -f "vllm.entrypoints.openai.api_server" > /dev/null; then echo "❌ 錯誤:偵測到 vLLM 伺服器已經在運行中!" echo "💡 提示:請先關閉舊行程後再重試。" exit 1 fi echo "✅ 系統檢查通過,準備啟動 vLLM..." # ROCm env export ROCM_HOME=/opt/rocm-7.2.3 export ROCM_PATH=$ROCM_HOME export PATH=$ROCM_HOME/lib/llvm/bin:$ROCM_HOME/bin:$PATH export LD_LIBRARY_PATH=/path/to/your-local-lib:/opt/rocm-7.2.3/lib:/opt/rocm-7.2.3/lib64:$LD_LIBRARY_PATH export LD_PRELOAD=/path/to/your-local-lib/libmpi.so.40 export HSA_OVERRIDE_GFX_VERSION=11.0.0 export HIP_VISIBLE_DEVICES=0 exec python -m vllm.entrypoints.openai.api_server \ --model /path/to/your-model/Qwen3.6-27B-GPTQ-Pro-4bit \ --port 8080 --dtype float16 \ --max-model-len 92512 \ --quantization gptq_marlin \ --kv-cache-dtype fp8 \ --gpu-memory-utilization 0.98 \ --enable-prefix-caching \ --attention-backend TRITON_ATTN \ --max-num-seqs 16 \ --trust-remote-code \ --language-model-only \ --enable-auto-tool-choice \ --tool-call-parser qwen3_coder \ --reasoning-parser qwen3 \ --default-chat-template-kwargs '{"enable_thinking": false}'核心生效確認
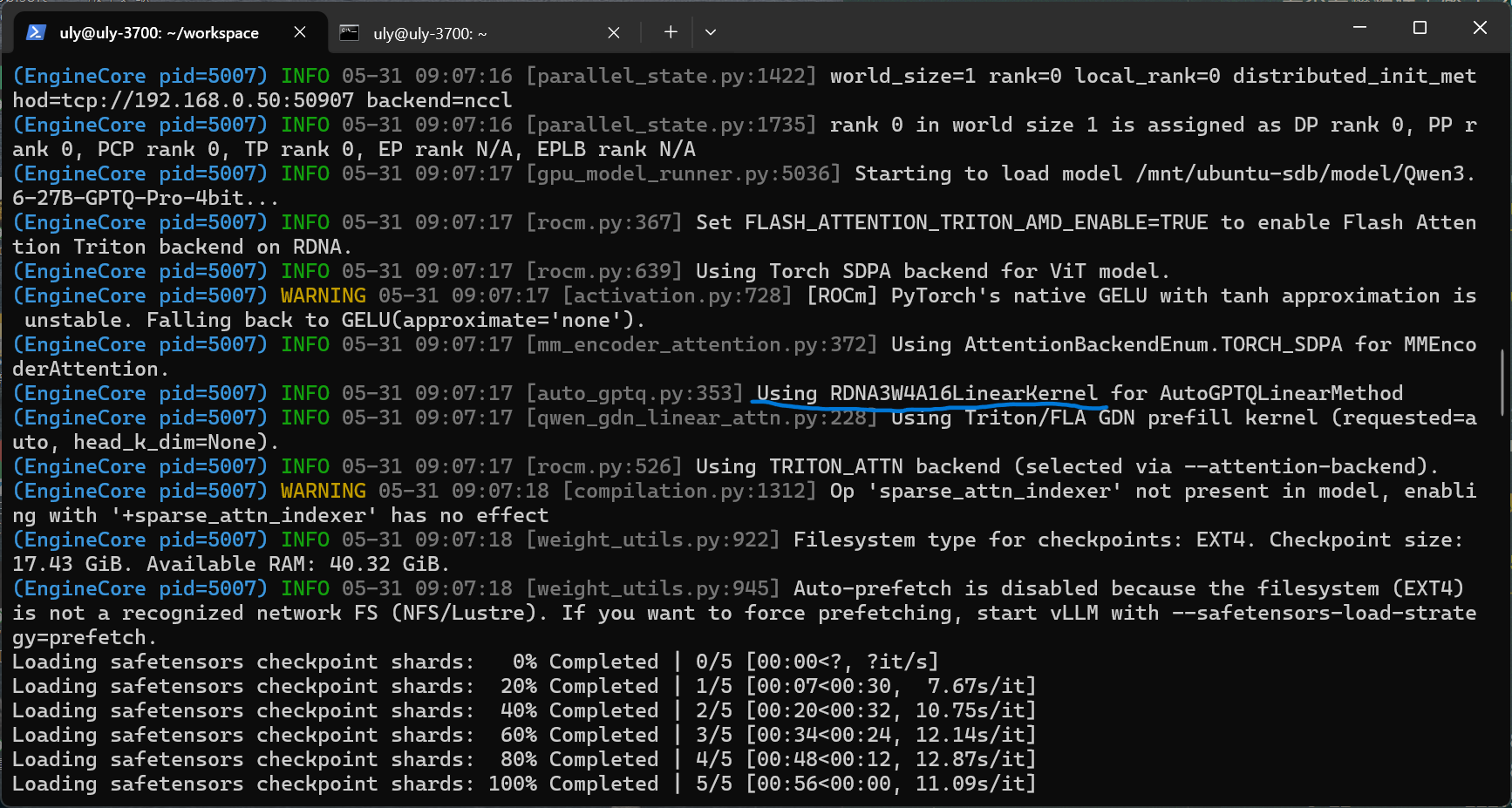
這是最重要的 log,PR 的 kernel 生效了:
INFO 05-30 17:28:01 [auto_gptq.py:353] Using RDNA3W4A16LinearKernel for AutoGPTQLinearMethod看到這行就代表 RDNA3 原生 kernel 已經在運作了!
五、Ubuntu 26.04 的坑
a. 缺少
libmpi.so.40OpenMPI 的動態函式庫找不到,需要去 Ubuntu 24.04 的套件來源抓對應的 dep。
b. GCC 16 太新導致 Triton 編譯不過
Ubuntu 26.04 預設 GCC 16,啟動時 Triton 編譯可能失敗。
需要設定環境變數強制使用 GCC 15 解決:export CC=/usr/bin/gcc-15 export CXX=/usr/bin/g++-15
六、心得
a. vLLM 是進階版,建議小白先去試 llama.cpp 入門
b. 安裝過程各種除錯,都建議 Hermes + Gemini 全程輔助。Hermes 的用途就是幫你操作系統
c. 感覺 vLLM 整體比 llama.cpp 穩定,速度上不一定就比較快,啟動也比較慢
d. vLLM 可以高併發,但是 KV Cache 還是有限的。16 個單句問題能回覆,但 2 個 Hermes 一起進來就會崩
e. 初次啟動 vLLM 後可能會卡在 Triton 編譯很久,這裡也可以叫 Hermes 去監控 cache 有沒有持續生成
-
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
系统 于 取消固定此主题