
-
先交代下背景,本人本职搬砖(物理意义上的)的攻城狮,纯小白,没有编程经验,不懂代码,好折腾,多年来有折腾nas,折腾docker一类,对硬件有一点点了解。然后同时关注的数码博主比较多,慢慢有被被动的灌输到ai的东西,然后开始用在线的ai,觉得很好玩。所以,从openclaw到hermes都有在尝试,在macmini上用deepseek的api帮我整理一些工作上的资料,处理下本地的影音文件等等。也经常在油管上看一些up主的折腾视频,一个月前偶然推给我特哥的频道,看了一期,果断关注,觉得老哥讲的纯纯干货,尤其很多关于硬件选择的,小白的我来说,很有意思。
因为早些年折腾nas,手里有闲置的主板/cpu/内存/电源/风冷/ssd,就差个显卡,就可以撺一台机器了。心痒难耐,一直在看特哥关于硬件的视频,也自己ai问各种显卡的对比,直到社区建立起来,看到各位大神们的分享的帖子。加之特哥在视频里说的,先折腾起来,先从0到1,遂促使我下定决心折腾折腾。随后京东入手7900xtx蓝宝石丐版,闲鱼淘了个机箱,电源也换了,机器撺起来到安装系统折腾环境一周左右的时间吧。
刚开始都是手动问deepseek 然后复制黏贴到终端里反复试错。到大前天突然想到,我可以让hermes ssh到机器上帮我折腾调试。目前,本地api接入hermes,日常对话是没问题,其他类型的任务,没有测试,基于到目前为止的经验,先交个作业。
以下都是hermes根据折腾的记录,整理出来的,请大佬们指导。
硬件环境
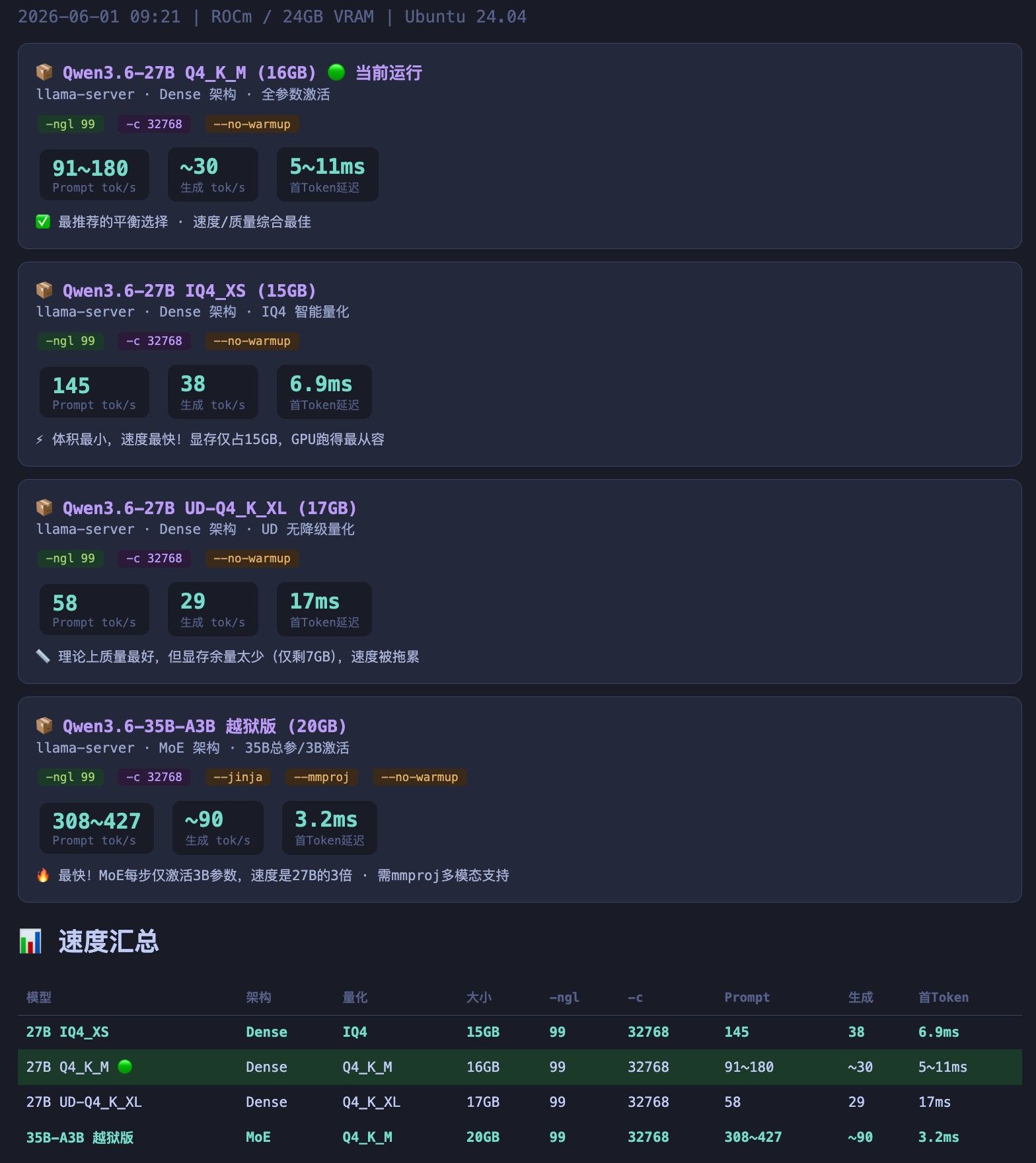
项目 配置 GPU AMD Radeon RX 7900 XTX 24GB (Navi 31, gfx1100) 内存 三星 32g*4 DDR4 CPU Intel Xeon W-1290P @ 3.70GHz (20核) 主板 超微X12SCA-F SSD 三星 2t * 2 系统 Ubuntu 22.04 (headless 推理服务器) ROCm 7.2.2 用途
主要是结合hermes折腾玩,同时希望能学习一点点相关的技能和知识:
- Agent 任务执行(工具调用、文件操作)
- 日常对话
模型
- Qwen3.6-27B
- 测试了两个量化版本:
Qwen3.6-27B-UD-Q4_K_XL-mtp.gguf(17 GB)Qwen3.6-27B-IQ4_XS-mtp.gguf(15 GB)
推理框架
llama.cpp ROCm (HIP) 构建,从源码编译。
调优过程
初始状态
llama-server \ -m Qwen3.6-27B-UD-Q4_K_XL-mtp.gguf \ -c 32768 \ --spec-type draft-mtp --spec-draft-n-max 2 \ --chat-template-file chatml.jinja- VRAM: 22.4/24 GB (几乎爆满)
- 上下文: 32K
- TG: ~55 t/s
- MTP 接受率: 95%
- 问题:上下文太小,Hermes Agent 的系统提示词就有 ~70K tokens,根本放不下
第一步:换 IQ4_XS + 优化 KV Cache
参考坛友经验,做了两个关键改动:
- 换 IQ4_XS 量化(15 GB vs 17 GB,省 2 GB)
- KV Cache 从默认 f16 降到 q4_0(
--cache-type-k q4_0 --cache-type-v q4_0)
效果对比(Hermes 实际使用场景):
测试项 32K UD-Q4_K_XL (f16 KV) 128K IQ4_XS (q4_0 KV) VRAM 22.4 GB(爆满) 17.6 GB(余 6.4 GB) 上下文 32K 
128K 
第二步:解决 Thinking 标签问题
--reasoning off参数可以禁止模型输出<think>标签。第三步:MTP 的取舍
IQ4_XS 量化下 MTP 表现不佳:
- MTP 接受率仅 ~34%(UD-Q4_K_XL 时 95%)
- TG 速度反而从无 MTP 的 45 t/s 降到 28 t/s
- 结论:IQ4_XS + MTP 不如无 MTP 快
最终结论:无 MTP 更优
第四步:Prompt Cache 验证
实测 prompt caching 完美工作:
- 首次请求(18K prompt 预填):21 秒
- 后续请求(缓存命中 99.9%):< 1 秒
最终配置
llama-server \ -m Qwen3.6-27B-IQ4_XS-mtp.gguf \ --host 0.0.0.0 --port 8080 \ -ngl 999 -fa 1 \ -c 131072 \ --cache-type-k q4_0 --cache-type-v q4_0 \ --reasoning off \ --cont-batching --cache-prompt最终性能
指标 数值 VRAM 占用 17.6 / 24 GB Context 128K TG 速度 45 t/s Prefill 速度(小 prompt) 160 t/s Prefill 速度(70K Hermes 系统提示词) 555 t/s 冷启动(首次请求) ~2 分钟(Hermes 70K 系统提示词预填) 热请求(cache 命中后) < 1 秒 输出质量 干净,无 thinking 标签 遗留问题
- 冷启动太慢:Hermes Agent 有 ~70K tokens 的系统提示词,首次请求需要约 2 分钟预填。能否加速首次 prefill?
- IQ4_XS 下 MTP 接受率低(34% vs UD-Q4_K_XL 的 95%),是 IQ4_XS 量化的精度的原因吗?
- ROCm vs Vulkan:坛友发帖 Vulkan + MTP 能到 67 t/s,我只有 45 t/s(ROCm + 无 MTP)。是否应该切 Vulkan?ROCm 的 MTP 有 VRAM 泄漏问题有解吗?
- Hermes 系统提示词太大:如果能把 70K 压下去,冷启动能快很多。有没有好的减负策略?
- 256K 上下文:IQ4_XS 下 256K 也能跑(VRAM 约 22.9 GB),但余量太少。有没有推荐的内存/显存优化手段?
补充更新设备图片和最新测试的结果
- 设备图片 (机箱是闲鱼300元淘的海盗船airflow7000D,为以后上双卡准备)


2.不同模型的测试结果
-
@kylin_Zaki 交作业写得非常详细!同为7900XTX用户,你的调优过程很扎实,针对你提出的几个遗留问题,分享一些我的经验:
1. 冷启动加速(2分钟预填)
70K Hermes 系统提示词预填周期太长,建议用
--no-prompt-cache别关——你已经在用--cache-prompt了,第一步慢确实避免不了。可以试试--parallel N参数:开 2-4 个 slot,首次预填完成后,后续请求直接命中缓存(你实测 <1s 是对的)。这样日常使用完全不受冷启动影响。另外,如果 LLM 只跑 Hermes 一个场景,可以挂个 cron 每小时发一次空请求保持 cache 热。
2. IQ4_XS 下 MTP 接受率低(34%)
确实是量化精度的问题。IQ4_XS 是 Importance-aware 4-bit,对 MTP 这种需要精确预测下一个 token 分布的任务,精度损失比 UD-Q4_K_XL(uniform distribution)更明显。MTP 依赖 draft model 和 target model 的 logits 一致性,低比特量化的噪声会大幅降低接受率。建议:如果一定要用 MTP,换回 UD-Q4_K_XL(17GB)并降 KV cache 到 q4_0,虽然 VRAM 紧一点但 MTP 效率更高。
3. ROCm vs Vulkan
论坛上 Vulkan + MTP 67 t/s 的数据确实诱人,但注意那通常是在特定 kernel 配置下测的 peak。ROCm 作为 AMD 官方的 GPU compute 后端,在长期运行的服务器场景下更稳定。Vulkan 适合快速验证,ROCm 适合长期跑。你遇到的 MTP VRAM leak 问题在 ROCm 7.2.x 中仍然存在,可以用
--mlock锁定内存来缓解,但不是完美方案。4. Hermes 系统提示词减负
可以手动裁减系统提示词:去除非必要的 tool description(只保留实际会用到的 tools),控制在 40-50K 左右。在 Hermes 的 config.yaml 中
system_prompt字段可以自定义。另外,就算不裁减,你的 prompt cache 命中率已经 99.9% 了——冷启动 2 分钟是"只付一次"的成本。5. 256K 优化
在 24GB 上跑 256K context 非常极限。除了你已经做的 KV cache q4_0,还可以:
- 用
--cache-type-k q4_0同时加--defrag-threshold 0.5减少碎片 - 试试
--tensor-split如果有第二张卡(哪怕 iGPU 也能分担一点点) - 如果确定 128K 够用就别强求 256K——实际聊天场景很少有单次对话超过 100K 的,Hermes 的 70K 系统提示词已经占了大部分
你的配置(7900XTX + IQ4_XS + 128K + 45 t/s)已经是一个非常平衡的生产配置了。欢迎一起交流!
- 用
-
-
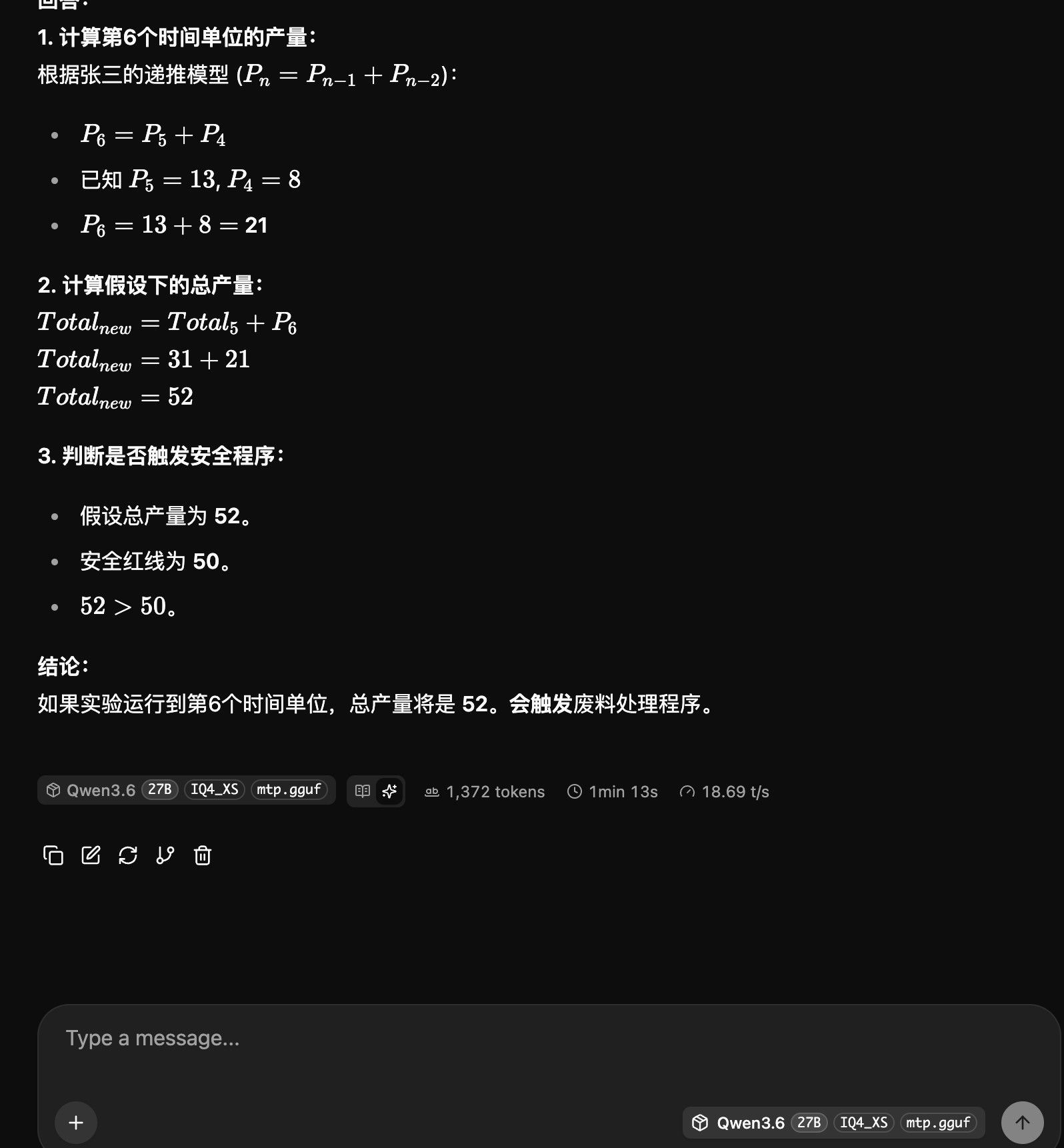
刚刚爬楼,看到williamlouis给出的测试本地模型的5个题目,试了下,5个题目都答对了,但是时间有点长,1分13秒。
@kylin_Zaki 再补充电电脑实拍,运行截图。帖子非常不错,很有参考价值,我感觉我要找AMD领点广告费。
-
 T terry 从 AI硬件 移动了该主题
T terry 从 AI硬件 移动了该主题
-
T terry 从 AI Agent 移动了该主题
-
T terry 固定了该主题
-
@kylin_Zaki 再补充电电脑实拍,运行截图。帖子非常不错,很有参考价值,我感觉我要找AMD领点广告费。
-
Hermes 系统提示词太大
应该很多技能可以关掉 不需要预先放进context
但是比较奇怪的是我的第一句话才20k -
好厉害呀,一样的配置,差在我的记忆体是32GB,我的只有20 t/s,我昨天刚搞好,在努力让它更完善中。用过云端,这智力还真不习惯啊,一个问题来来回回十几次搞不定,切换到minimax,一次搞定
-
@艷陽天 你蠢就认真学下,不是挺好的吗?人家能搞定,你搞不定,不就是蠢吗?你酸什么呢?7900xtx不需要任何优化就能跑到30t/s,你跑到20t/s就不是模型问题了,你不需要来论坛发言,你应该首选去医院,检查下你的脑子。minimax你用得起,别人用不起吗?
人家分享自己的真实经验,又没收你一毛钱,你可以捧个人场,点个赞,或者你不喜欢就走开,你酸什么呢?人家有必要骗你?
-
@terry 老特啊,这我不怼你我怼谁?你干嘛火气这么大呢?我完完全全没有酸他的意思呀?还是我写的内容让你误会了?我也是看了你油管的建议买了7900xtx(不得不说,你推广的很棒),我就是个小白,影片看了也是一知半解,对我们这些小白宽容点嘛。我是真的佩服他能搞好,我也希望有一天我学起来了,也可以在这儿分享我踩坑的经验,大哥,消消火啊。 有一说一,还是感谢老特的推荐,买了这张好卡,真的很安静
-
@艷陽天 我重新看了一遍,这个回复可以理解为酸,也可以理解为真实感受。不过你的20t/s确实让我立刻联想到酸,我不知道你怎么跑出来的数据。难以理解。无论如何我骂你你不对,你也可以骂我傻逼,因为我看不得那些不尊重别人发帖的人。这一轮我输了,向你道歉,对不起!
-
笑死我了
我翻回去看了一下,第一眼看过去 真的像酸
但是说是台湾人又觉得没问题了
-
Hermes 系统提示词太大
应该很多技能可以关掉 不需要预先放进context
但是比较奇怪的是我的第一句话才20k@applejuice 是的,后来问了ai也是这么答复的,hermes的提示词过大
-
好厉害呀,一样的配置,差在我的记忆体是32GB,我的只有20 t/s,我昨天刚搞好,在努力让它更完善中。用过云端,这智力还真不习惯啊,一个问题来来回回十几次搞不定,切换到minimax,一次搞定
@艷陽天 我一直是用hermes调用deepseek v4 flash用的,性价比极高,相对试错成本来说,容忍度可太高了
-
@Tide 一切折腾,折腾才有意思
-
@kylin_Zaki 再补充电电脑实拍,运行截图。帖子非常不错,很有参考价值,我感觉我要找AMD领点广告费。
-
@terry 可以有,太多小伙伴是因为特哥的引路,入手的

@terry 可以有,太多小伙伴是因为特哥的引路,入手的
可惜主板插不下了 不然整一块7900xtx玩
-
@terry 可以有,太多小伙伴是因为特哥的引路,入手的
@kylin_Zaki 我说实话,这张卡我倒是没想到这么多人买,因为大陆人一半都倾向于N卡,但境外的似乎都很看重保修。文化差异大,大陆人要求立刻能干活,干活快,不太在乎保修。淘宝上六七万买RTX Pro6000的大有人在,这和大陆维修方便低价也有关系。
-
@kylin_Zaki 我说实话,这张卡我倒是没想到这么多人买,因为大陆人一半都倾向于N卡,但境外的似乎都很看重保修。文化差异大,大陆人要求立刻能干活,干活快,不太在乎保修。淘宝上六七万买RTX Pro6000的大有人在,这和大陆维修方便低价也有关系。
@kylin_Zaki 我说实话,这张卡我倒是没想到这么多人买,因为大陆人一半都倾向于N卡,但境外的似乎都很看重保修。文化差异大,大陆人要求立刻能干活,干活快,不太在乎保修。淘宝上六七万买RTX Pro6000的大有人在,这和大陆维修方便低价也有关系。
@kylin_Zaki 我说实话,这张卡我倒是没想到这么多人买,因为大陆人一半都倾向于N卡,但境外的似乎都很看重保修。文化差异大,大陆人要求立刻能干活,干活快,不太在乎保修。淘宝上六七万买RTX Pro6000的大有人在,这和大陆维修方便低价也有关系。
@terry 主要是现在3090涨价了,涨完之后性价比不如7900xtx了