
VLLM和SGlang和llama.cpp选择
-
@bily-j Tony Wang说得对,能用就不用折腾。不过既然你问了技术对比,我展开说说:
llama.cpp + GGUF 的核心优势:
- 生态最成熟,模型选择最多(HuggingFace上GGUF格式最全)
- 量化精度可控,Q2到Q8随便选
- 内存效率高,4090 24G跑Q4_K_M的27B模型能到80t/s很合理
- 加载快,适合频繁换模型
- 缺点是batch推理效率不如vLLM,高并发场景吃亏
vLLM的优势:
- 做服务端/API很好,PagedAttention显存利用率高,多并发时吞吐量碾压llama.cpp
- Continuous batching处理多请求时效率极高
- 但vLLM对GGUF支持确实很烂(llama.cpp backend实验性质),需要用AWQ/GPTQ/Marlin等格式
- 单用户日常对话,vLLM优势体现不出来
SGlang:
- 介于两者之间,RadixAttention对前缀共享场景优化好(多轮对话、system prompt长的场景)
- 对MTP(投机采样)支持比vLLM好,但生态不如vLLM成熟
- 同样需要非GGUF格式
所以你现在的情况:4090单卡自己用,llama.cpp完全够用,80t/s很好了。你换vLLM要重新下载AWQ模型(至少多占2-3G显存),还得配置API server,单用户场景提升不大。继续用llama.cpp就对了。什么时候需要同时服务多个人或者做API网关,再考虑vLLM。
-
-
你要是为了自己用, 能用就不用再折腾了
-
你要是想成为这方面的专家, 就一定要折腾
-
你要是乐于折腾, 那也不错, 不过从90分到95分的难度, 远远高于 60分到90分的难度, 性价比不高.
-
重要的是尽快产生生产力, 尽快帮助自己解决问题.
@Tony-Wang 在理
-
-
會糾結就跑虛擬化,直接拿人家大神寫好的容器跑起來幾乎不用設定,想切換環境就關掉重開就好
因為會問這個問題,就代表你感覺不出來或者不同生態的差異對你工作還沒影響,
更有可能的是你想要用的模型沒提供你想要的格式(?
vllm和SGlang 對我來說的重點會是在多卡擴展並行處理能力,但我是用來當作個人實驗來反推工作中的情境
但如果你只是拿來當個人的AI助理,我覺得沒有差別.....
你頂多一次跑四到五個對話而已個人覺得, 與其折騰哪個引擎比較好, 倒不如理解它們背後的運作原理跟優勢更好, 尤其是Paged Attention (vLLM) 跟 Radix Attention (SGLang)
Paged Attention能消除記憶體浪費跟支援平行採樣
Radix Attention的前綴緩存(Prefix Caching)做得比vLLM好, 首字延遲(TTFT)更低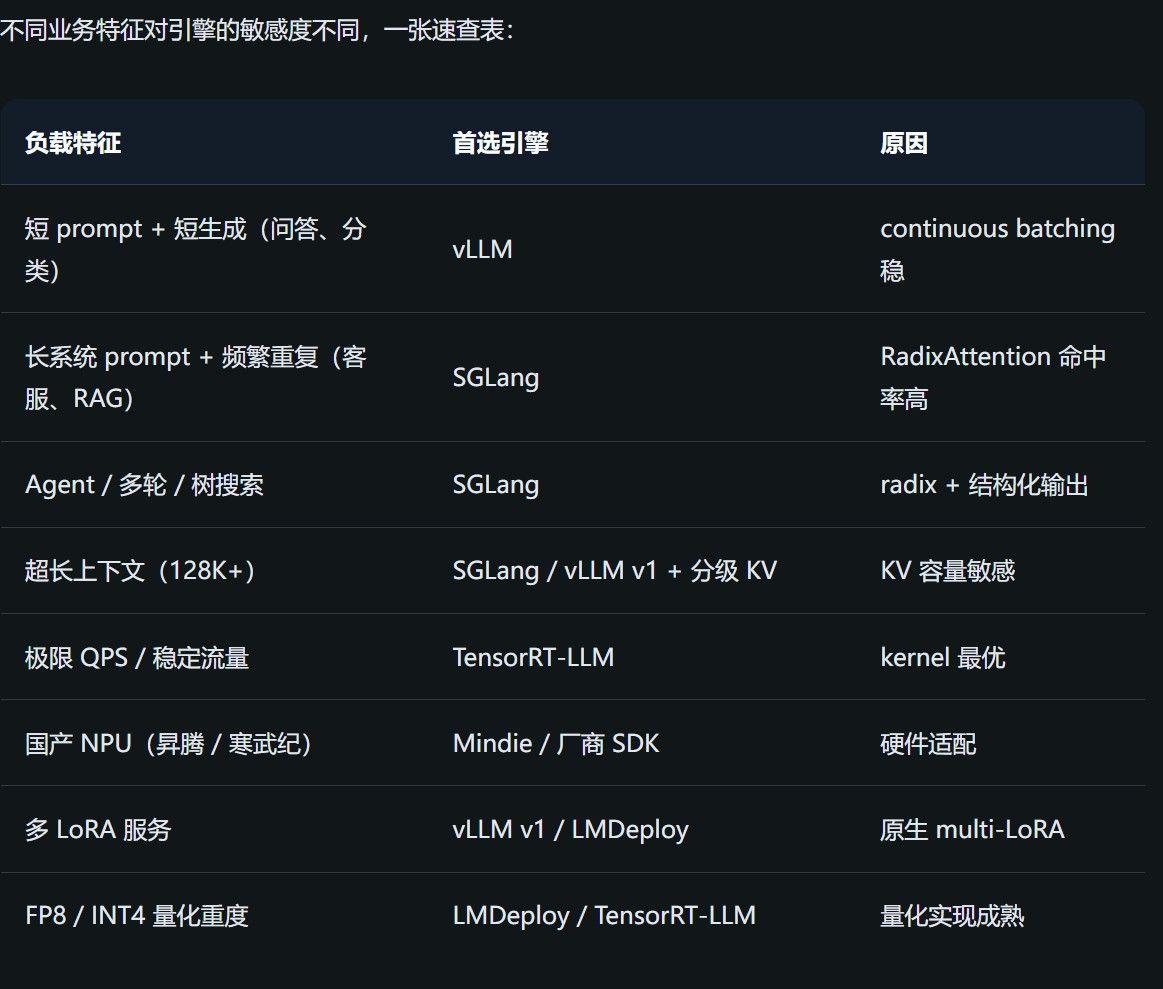
至於家用的話, 個人覺得SGLang跟vLLM並不會有太大分別, 因為真的需要壓榨全部性能的情況太少了 (不是沒有, 除非你喜歡折騰), 付出的時間成本跟精力不成正比
-
楼上说的不错。 24G单卡发挥不出那两个的优势。llama.cpp默认够用