
技术分享:双卡 RTX 5060Ti Blackwell 运行 vLLM 与 LM Studio 性能实测报告
-
来交作业了。分享一下在双卡 RTX 5060Ti Blackwell GPU 上使用 vLLM 和 LM Studio (LMS) 的实际使用体验与性能测试。
结论先行 (TL;DR)
LM Studio (Split 模式): 理论测试可达 46~50 token/s,实际使用(Real Use)中约为 26~36 t/s。vLLM TP (Tensor Parallel) 模式: 测试表现为 35~78 token/s,至于实际体验如何?我们在后文详细拆解。
测试硬件环境: 双显卡均运行在 Intel CPU 平台上,运行在 PCIe 3.0 x8 通道下。
vLLM 核心配置参数
当前运行 vLLM 服务的完整启动命令如下:
--model Qwen3.6-27B-Text-NVFP4-MTP
--gpu-memory-utilization 0.95
--max-model-len 64000
--enable-auto-tool-choice
--tool-call-parser qwen3_xml
--tensor-parallel-size 2
--language-model-only
--kv-cache-dtype fp8
--max-num-seqs 1
--max-num-batched-tokens 8192
--trust-remote-code
--enable-prefix-caching
--enable-chunked-prefill
--no-scheduler-reserve-full-isl
--speculative-config '{"method":"mtp","num_speculative_tokens":3}'体验总结
LM Studio: 部署极其简单,开箱即用,但整体速度较慢。vLLM: 性能强劲,但显存占用(Memory footprint)明显更高,且由于显存开销,可分配的上下文长度(Context)会有所受限。
基准测试数据 (Benchmark Results)测试命令: uvx llama-benchy --base-url http://localhost:8000/v1 --model Text-NVFP4-MTP
测试共独立运行 3 次,详细数据如下:model test t/s peak t/s ttfr (ms) est_ppt (ms) e2e_ttft (ms) /home/api/AiModel/Text-NVFP4-MTP pp2048 1729.27 ± 19.59 1186.49 ± 13.32 1185.04 ± 13.32 1186.49 ± 13.32 /home/api/AiModel/Text-NVFP4-MTP tg32 61.80 ± 7.58 63.80 ± 7.82 :--------------------------------- -------: -----------------: -------------: -----------------: -----------------: -----------------: /home/api/AiModel/Text-NVFP4-MTP pp2048 1415.00 ± 227.76 1488.69 ± 247.80 1487.23 ± 247.80 1488.69 ± 247.80 /home/api/AiModel/Text-NVFP4-MTP tg32 74.86 ± 4.30 77.29 ± 4.44 :--------------------------------- -------: ----------------: -------------: ----------------: ----------------: ----------------: /home/api/AiModel/Text-NVFP4-MTP pp2048 1735.72 ± 18.16 1182.07 ± 12.30 1180.62 ± 12.30 1182.07 ± 12.30 /home/api/AiModel/Text-NVFP4-MTP tg32 65.26 ± 5.31 67.37 ± 5.48 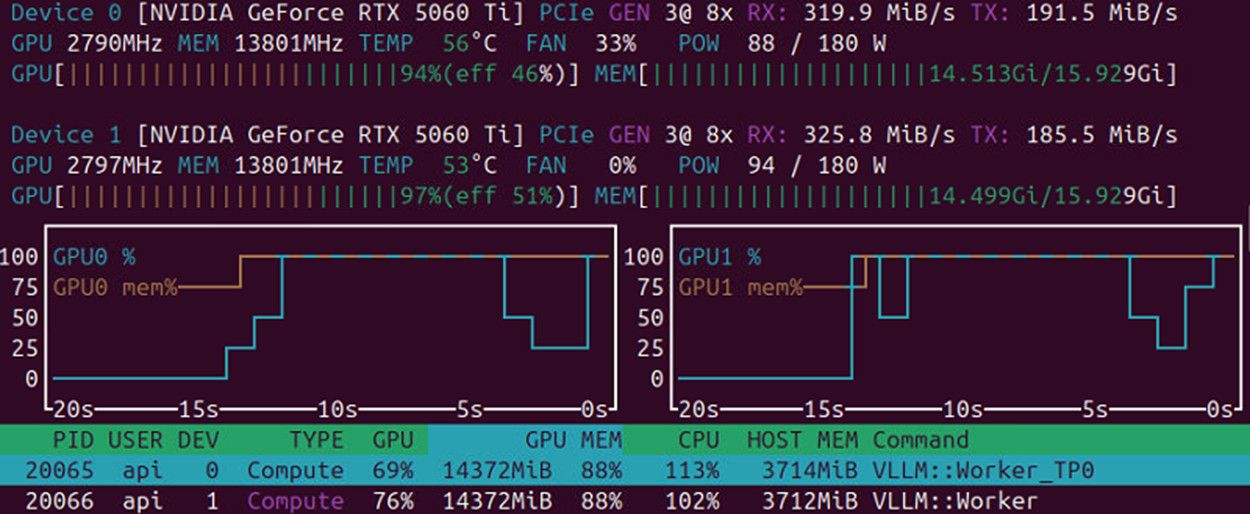
Agent 场景优化配置 (Hermes Agent Setup)
如果在 Agent 场景下运行,为了防止显存碎片化导致 OOM,建议加入环境变量:
export PYTORCH_CUDA_ALLOC_CONF="expandable_segments:True"Hermes Agent Setup: 同时对 vLLM 参数进行微调(主要调小了 max-num-batched-tokens 并在启动时控制利用率):
--model ~/AiModel/Text-NVFP4-MTP
--gpu-memory-utilization 0.90
--max-model-len 64000
--enable-auto-tool-choice
--tool-call-parser qwen3_xml
--tensor-parallel-size 2
--language-model-only
--kv-cache-dtype fp8
--max-num-seqs 1
--max-num-batched-tokens 2048
--trust-remote-code
--enable-prefix-caching
--enable-chunked-prefill
--no-scheduler-reserve-full-isl
--speculative-config '{"method":"mtp","num_speculative_tokens":3}'
性能归纳与关键解读 (Notes)
NVFP4 量化优势: Blackwell 架构原生支持的 NVFP4 量化非常优秀,在保持极高模型精度的同时,效果明显好于传统的 Q4_K_M 等量化方案。MTP (Multi-Token Prediction) 投机采样: 即便在没有 NVLink 的双卡环境下,MTP 也能带来很好的速度收益。虽然目前 Turboquant 还不支持它,但配合 vLLM 时,Prefill (pp) 阶段的速度已经足够快,不再是瓶颈。
上下文与吞吐量关联测试汇总
通过调整不同的最大上下文(Context),我们观察了 Prefill (pp2048) 和 Token Generation (tg32) 的吞吐量变化:Ctx (上下文) pp2048 (t/s) tg32 (t/s) Quant (量化) MTP KV Cache 32768 1819 35 NVFP4 NO (关闭) FP8 64000 1631 81 NVFP4 3 FP8 98304 1734 78 NVFP4 3 FP8 131072 1736 75 NVFP4 3 FP8 观察: 从表中第 1 行可以看出,当关闭 MTP 时,tg32 的生成速度直接从 81 t/s 跌至 35 t/s。这强力证明了即使在 PCIe 3.0 x8 的带宽限制下,开启 MTP 投机采样依然能让生成效率翻倍。
目前模型不支持 TurboQuant,或需配置 vLLM,不过 FP8 的速度看起来还行 -
性能对比补充:双卡 RTX 3090 Ampere 实测数据
为了更清晰地评估 Blackwell 架构的提升幅度,这里将 双卡 RTX 3090 Ampere 的测试数据一并交作业。测试基于相同的软件安装环境,但运行在适配 Ampere 架构的旧版 CUDA 版本上。核心对比数据看板
根据测试记录,双卡 RTX 3090 在不同配置(单卡、vLLM TP、LM Studio Split)下的表现如下:
关键技术解读与对比分析
- vLLM 架构下的极端释放
在 vLLM 开启 Tensor Parallel (TP) 模式并配合 AutoRound Int4 量化时,双卡 RTX 3090 跑出了 112 t/s 的 Token 生成速度(tg32)。
虽然 Ampere 架构不支持 Blackwell 的 NVFP4,但在成熟的 Int4 优化和 24GB x2 充足显存的加持下,纯粹的吞吐量表现依然非常激进。
此时 Prefill 速度(pp2048)为 1275 t/s,略低于 Blackwell 架构在相同或更长上下文下的表现(1600~1800 t/s)。
- LM Studio (GGUF) 表现与真实场景
在 LM Studio 环境下,使用单卡或 Split 模式运行 Qwen3.6-27B GGUF(结合 MTP 投机采样与 Flash Attention):
Q4_K_M 量化: tg32 测试速度保持在 63~70 t/s 之间,而在真实的生产力场景(如 Q1 预热、Q2 效率测试、Q3 故事生成)中,实际输出稳定在 34~47 t/s 之间。
Q6_K 量化: 在 98304 较长上下文时,真实场景(Real-world Use)输出依然能维持在 38~44 t/s。
- 带宽与架构的思考
两套系统都受限于 PCIe 3.0 x8 通道,这在多卡通信(TP 模式)时会成为明显的瓶颈。
RTX 3090 (Ampere): 凭借其 384-bit 的高原生显存带宽(Memory Bandwidth),在处理传统量化(如 GGUF、Int4)的纯推理计算时展现出了极强的韧性。
RTX 5060Ti (Blackwell): 虽然原生显存位宽较窄 (½ of RTX3090),但凭借 NVFP4 计算密度的优势以及新一代张量核心(Tensor Cores)的效率,在极大节省显存的前提下,依然跑出了极其紧凑且高效的能效比。
Example Config:
--model Qwen3.6-27B-int4-AutoRound
--gpu-memory-utilization 0.95
--max-model-len 131072
--enable-auto-tool-choice
--tool-call-parser qwen3_xml
--tensor-parallel-size 2
--language-model-only
--kv-cache-dtype fp8_e5m2
--max-num-seqs 1
--max-num-batched-tokens 4128
--trust-remote-code
--dtype bfloat16
--enable-prefix-caching
--enable-chunked-prefill
--no-scheduler-reserve-full-isl
--speculative-config '{"method":"mtp","num_speculative_tokens":3}' - vLLM 架构下的极端释放
-
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
"expandable_segments:True"
3090 club 反而不用这个 我刚刚也拿掉了
最近显卡一直假死 -
楼主这个效果非常不错。看来买新不买旧非常有道理的。
-
系统 于 取消固定此主题
-
@Gang-Cheng 这个问题我试着分析一下:
选双5060Ti 16G(32G总显存)的优势:
- NVFP4支持 — 5060Ti Blackwell架构原生支持FP4,跑Qwen3.6 27B NVFP4版只需要一半显存,速度还更快
- CUDA生态 — 所有框架(vLLM、llama.cpp、ComfyUI)都完美支持,不用折腾ROCm
- 总显存32G > 24G — 双卡可以跑更大的模型,比如70B Q4
- 价格 — 两张5060Ti ≈ 一张7900XTX
选7900XTX(24G单卡)的优势:
- 简单省心 — 单卡不用搞多卡配置,不用操心NVLink/p2p通信
- 单卡性能 — 7900XTX单卡算力比5060Ti强不少,同一模型跑得更快
- ROCm生态在快速进步 — llama.cpp、vLLM都支持ROCm了,日常推理没问题
我的建议:
- 如果你现在不急着用、愿意折腾多卡 + 想跑更大的模型 → 再收一张5060Ti组双卡
- 如果你想要省心、不想搞多卡调试、主要跑27B以下模型 → 换7900XTX
- 折中方案:先留着5060Ti用着,等5060Ti Super 20G版出来再升级,一步到位
关键还是看你主要跑什么模型。27B以下单卡就够了,想上70B就得双卡方案。
-
请问一下我现在有一张5060ti16g的显卡是再买一张好,还是卖了换7900xtx好~谢谢