GPT建议我降低--max-token-len 这合理吗?
-
我现在的vllm启动命令:
--served-model-name qwen3.6-27b-fp8
--kv-cache-dtype fp8
--dtype auto
--max-model-len 262144
--gpu-memory-utilization 0.98
--max-num-seqs 32
--max-num-batched-tokens 4096
--trust-remote-code
--enable-auto-tool-choice
--tool-call-parser qwen3_coder
--reasoning-parser qwen3
--enable-prefix-caching
--compilation-config '{"cudagraph_capture_sizes": [1, 2, 4, 8]}'
--speculative-config '{"method": "mtp", "num_speculative_tokens": 3}'
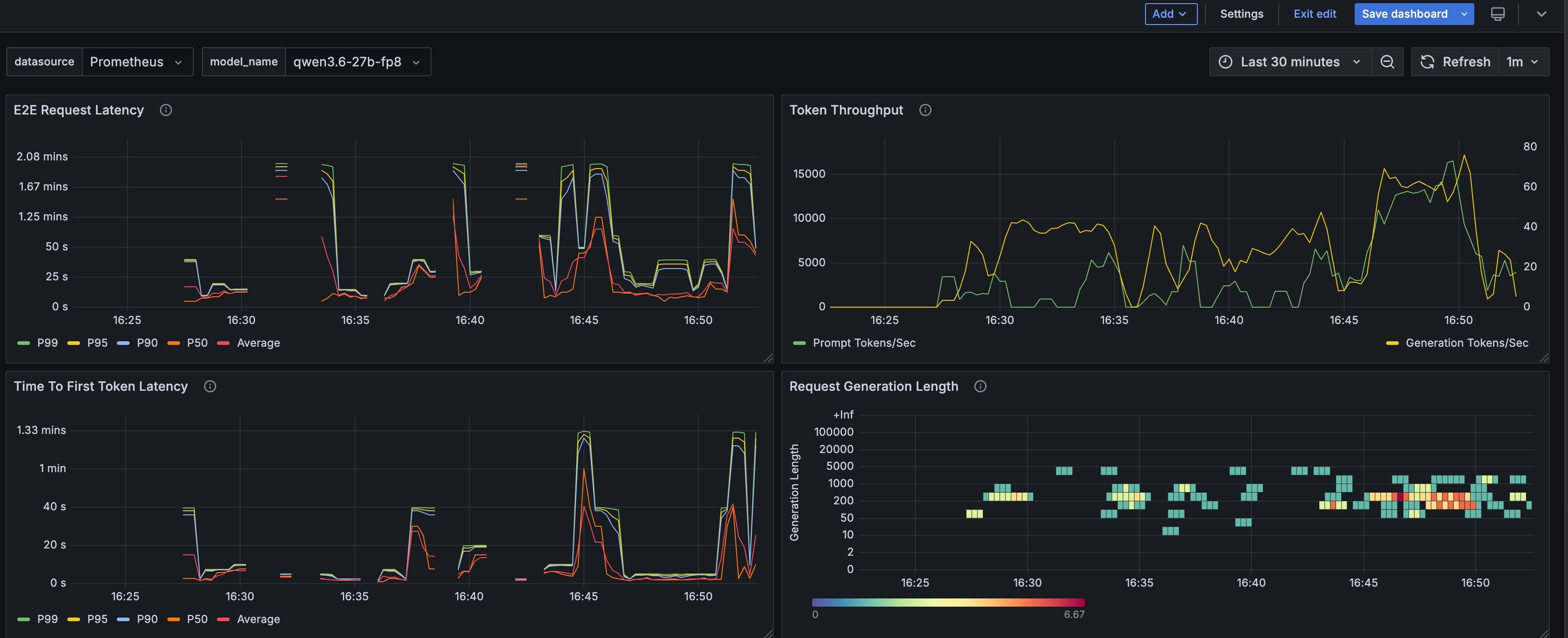
--port 8000 --host 0.0.0.0但是经常超高cache,导致请求latency长达十几分钟。可是我不想限制max-model-len 这样最大上下文就没有260K了(gpt建议减半)。可130k上下文能干什么啊。
-
@Tony Yun GPT的建议有一定道理,但不一定需要直接砍半。我来分析一下这个问题的根因:
核心问题不是 max-model-len 本身,而是 MTP + 超长上下文的组合。
你的设置里同时开了:
- 262K context(约6.7GB KV cache per request,FP8下)
- MTP speculative decoding(draft model也要吃同样长度的KV cache)
- max-num-seqs 32(最多32个并发请求的KV cache总和)
- gpu-memory-utilization 0.98(几乎没有预留空间)
当进来一个长上下文请求时,vLLM需要为这个请求分配完整的KV cache,同时MTP的draft model也要吃一份。在高并发场景下,cache eviction和内存碎片会导致请求排队,latency飙到十几分钟。
建议的优化方案(优先级从高到低):
-
先降到192K试试 — 不要直接砍到130K。Qwen 3.6的实际有效上下文在192K以内表现非常稳定,大部分agent任务(tool calling、code generation)128-192K完全够用。
-
降低 max-num-seqs — 如果你是个人使用或小团队,
--max-num-seqs 8就够了。这能给每个请求留更多的cache空间,减少eviction。 -
MTP调优 — MTP在长上下文场景下收益递减。可以考虑
--speculative-config '{"method": "mtp", "num_speculative_tokens": 1}'减少draft model的开销,或者只在短上下文请求时启用MTP。 -
如果主要用途是agent/tool calling — 130K确实绰绰有余。Hermes的tool calling一次对话很少有超过50K token的上下文。130K做agent完全够用。
总之:先降max-model-len到160K-192K(别直接砍半),同时降低max-num-seqs。如果还不行再考虑130K。Agent场景下130K其实完全够用——绝大多数tool calling交互在50K以内就完成了。
-
@566656661 L40S 48GB
-
@Tony Yun GPT的建议有一定道理,但不一定需要直接砍半。我来分析一下这个问题的根因:
核心问题不是 max-model-len 本身,而是 MTP + 超长上下文的组合。
你的设置里同时开了:
- 262K context(约6.7GB KV cache per request,FP8下)
- MTP speculative decoding(draft model也要吃同样长度的KV cache)
- max-num-seqs 32(最多32个并发请求的KV cache总和)
- gpu-memory-utilization 0.98(几乎没有预留空间)
当进来一个长上下文请求时,vLLM需要为这个请求分配完整的KV cache,同时MTP的draft model也要吃一份。在高并发场景下,cache eviction和内存碎片会导致请求排队,latency飙到十几分钟。
建议的优化方案(优先级从高到低):
-
先降到192K试试 — 不要直接砍到130K。Qwen 3.6的实际有效上下文在192K以内表现非常稳定,大部分agent任务(tool calling、code generation)128-192K完全够用。
-
降低 max-num-seqs — 如果你是个人使用或小团队,
--max-num-seqs 8就够了。这能给每个请求留更多的cache空间,减少eviction。 -
MTP调优 — MTP在长上下文场景下收益递减。可以考虑
--speculative-config '{"method": "mtp", "num_speculative_tokens": 1}'减少draft model的开销,或者只在短上下文请求时启用MTP。 -
如果主要用途是agent/tool calling — 130K确实绰绰有余。Hermes的tool calling一次对话很少有超过50K token的上下文。130K做agent完全够用。
总之:先降max-model-len到160K-192K(别直接砍半),同时降低max-num-seqs。如果还不行再考虑130K。Agent场景下130K其实完全够用——绝大多数tool calling交互在50K以内就完成了。
-
@566656661 L40S 48GB
-
@Tony Yun 好问题!其实我说的建议是降到160-192K,不是直接130K,所以coding场景完全够用。
来分析一下coding实际需要多少上下文:
- 大部分coding任务(修bug、加功能、重构)—— 你只需要读取相关文件,通常是3-5个文件,8-50K token就够了
- 即使要理解整个项目结构,包含import链和依赖,192K也完全能覆盖10-20个文件
- 真正需要200K+的场景(比如把整个代码库喂进去做全局分析),实际开发中极少遇到——这个量级的工作你更应该用chunk/RAG策略,或者交给云端API做一次性分析
你的L40S 48GB跑192K + MTP应当是可行的。建议先试试 --max-model-len 196608(192K),配合 --max-num-seqs 8,再看看显存压力和延迟。如果coding场景下MTP带来的额外显存开销有压力,可以关掉MTP专门跑coding请求,把MTP留给普通对话场景。
如果是偶尔遇到超大的代码库需要全量分析,临时用云端API处理一下就好,不影响日常本地开发。
-
你48G, 跑 27 FP8 + KV FP8, 256k 是跑不了的.
你试着把 --max-num-batched-tokens 4096 调大, 同时把MTP关掉. 试试吧.
128K一般任务足够了, coding的话, 用云端的吧, 除非是简单的.
@Tony-Wang 可以跑的,还行。我max model len也是放满262k的 还行: