
論 迷你電腦 配合 RTX Pro 4500 的簡單測試, 以及Blackwell架構下的一些嘗試 (僅限Dense模型)
-
@566656661 可以許願 https://microsoft.github.io/TRELLIS.2/ 測試嗎?
剛剛跑 ROCm版堪用,但踩雷不少,等下也丟上來
https://lcz.me/post/5275 -
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
以下是研究途中的碎碎唸, 不感興趣的可以不看
碎碎唸1
看了蠻多文件跟大神文章, 有幾個值得留意的地方
Blackwell架構分成了Consumer Blackwell (sm 12x) 跟 Data Center Blackwell (sm 10x) 所有Geforce, RTX Pro, DGX Spark, RTX Spark都歸屬在Consumer Blackwell 其中最大的分別就是在於sm 12x缺少了tcgen05, 這也是Flash Attention 4裏面的核心技術 底層MMA邏輯裏用的還是SM8X, 也就是目前的Flash Attention 2 好家夥, 老黃這算不算是在欺詐啊...https://docs.vllm.ai/en/stable/configuration/env_vars/ v0.22 cu129可以在--linear-backend (前身VLLM_NVFP4_GEMM_BACKEND)使用flashinfer-b12x而不是flashinfer-cutlass MoE模型 (Qwen 3.6 35BA3B 跟 Gemma 4 26BA4B) 可以通過在--moe-backend 設置flashinfer_b12x 這個是特意為sm 12x架構優化的GEMM内核 約有30%throughput增長, https://github.com/vllm-project/vllm/pull/39634 這個我有點興趣先再試試看
碎碎唸2 (
吐槽)在一邊看vLLM文件一邊跑去問了Gemini, 講明了是Blackwell架構,居然還給了個
VLLM_MXFP4_BACKEND=marlin, 先不説直接無視掉NVFP4, marlin是給沒有FP4硬件加速的啊... (NVFP4或者MXFP4都可用)VLLM_FLASHINFER_MOE_BACKEND還給了throughput這個預設參數, 也沒改成--moe-backend flashinfer_cutlass(雖然這個在27b 模型沒用到)錯誤示範, 不要學
docker run -d \ --name vllm-Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP \ (中間省略) -e SERVED_MODEL_NAME="Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP" \ -e VLLM_ATTENTION_BACKEND="FLASHINFER" \ -e VLLM_MXFP4_BACKEND="marlin" \ -e VLLM_FLASHINFER_MOE_BACKEND="throughput" \ -e VLLM_USE_FLASHINFER_SAMPLER="1" \ -e VLLM_EXTRA_ARGS= (以下省略) -
我的是5090D版 (住香港), 而且香港現在5090D貴到快要到2萬中, 非D都起碼要3萬頭港幣了
差異的話我是沒特別留意, 畢竟5090D太多時候都是試驗品 + 日常使用
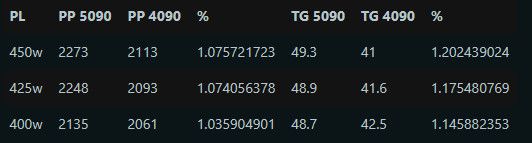
4500的fp16 tflops卡在5070ti 跟 5080中間, Prefill的話你可以用5070ti作爲基準加個5%左右吧.
至於CP嘛, 混合日常使用跟LLM肯定是5090更好, 怕功耗600w可以用afterburner降到最低400w左右, 引用一下這個Reddit Post, 性能損失如下:
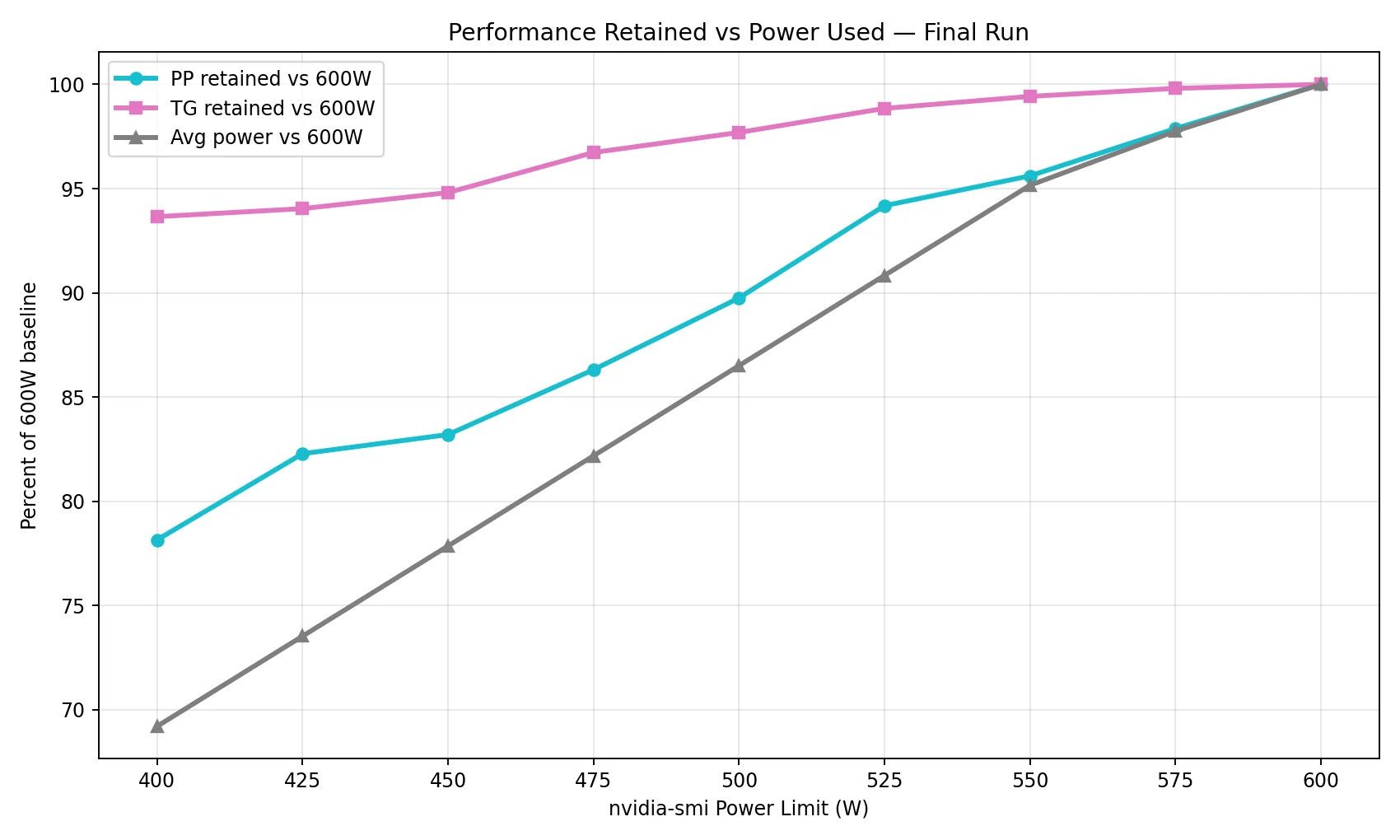
-
基於這個文章我也特意跑去試試INT4, 只能說老黃沒有把最後的良心都扔掉, 如果NVFP4比INT4沒有更多優勢的話, 真的要駡街了
vLLM cu130 nightly (0.20)
啓動跟測試參數跟1樓一樣, 單純換了個模型
| model | test | t/s | peak t/s | ttfr (ms) | est_ppt (ms) | e2e_ttft (ms) | | :---------------------------------------- | ---------------: | ---------------: | -----------: | -----------------: | -----------------: | -----------------: | | Qwen3.6-27B-heretic-v2-mtp-int4-AutoRound | pp2048 | 1982.15 ± 894.28 | | 1551.80 ± 975.03 | 1473.35 ± 975.03 | 1551.80 ± 975.03 | | Qwen3.6-27B-heretic-v2-mtp-int4-AutoRound | tg480 | 70.03 ± 2.28 | 87.67 ± 1.25 | | | | | Qwen3.6-27B-heretic-v2-mtp-int4-AutoRound | pp2048 @ d1000 | 2639.16 ± 40.73 | | 1233.51 ± 17.91 | 1155.06 ± 17.91 | 1233.51 ± 17.91 | | Qwen3.6-27B-heretic-v2-mtp-int4-AutoRound | tg480 @ d1000 | 71.09 ± 5.72 | 91.00 ± 5.89 | | | | | Qwen3.6-27B-heretic-v2-mtp-int4-AutoRound | pp2048 @ d5000 | 2529.19 ± 13.93 | | 2865.45 ± 15.52 | 2787.01 ± 15.52 | 2865.45 ± 15.52 | | Qwen3.6-27B-heretic-v2-mtp-int4-AutoRound | tg480 @ d5000 | 71.72 ± 1.86 | 91.33 ± 7.85 | | | | | Qwen3.6-27B-heretic-v2-mtp-int4-AutoRound | pp2048 @ d10000 | 2433.99 ± 3.22 | | 5028.07 ± 6.36 | 4949.63 ± 6.36 | 5028.07 ± 6.36 | | Qwen3.6-27B-heretic-v2-mtp-int4-AutoRound | tg480 @ d10000 | 71.66 ± 3.22 | 90.67 ± 1.70 | | | | | Qwen3.6-27B-heretic-v2-mtp-int4-AutoRound | pp2048 @ d20000 | 2293.80 ± 0.84 | | 9690.43 ± 3.52 | 9611.99 ± 3.52 | 9691.58 ± 3.56 | | Qwen3.6-27B-heretic-v2-mtp-int4-AutoRound | tg480 @ d20000 | 72.64 ± 2.80 | 88.67 ± 8.22 | | | | | Qwen3.6-27B-heretic-v2-mtp-int4-AutoRound | pp2048 @ d50000 | 1948.24 ± 1.20 | | 26793.70 ± 16.21 | 26715.25 ± 16.21 | 26796.17 ± 16.70 | | Qwen3.6-27B-heretic-v2-mtp-int4-AutoRound | tg480 @ d50000 | 70.21 ± 5.02 | 85.67 ± 6.80 | | | | | Qwen3.6-27B-heretic-v2-mtp-int4-AutoRound | pp2048 @ d100000 | 1567.89 ± 0.72 | | 65164.49 ± 30.24 | 65086.05 ± 30.24 | 65168.84 ± 29.64 | | Qwen3.6-27B-heretic-v2-mtp-int4-AutoRound | tg480 @ d100000 | 62.20 ± 1.73 | 84.67 ± 2.62 | | | | | Qwen3.6-27B-heretic-v2-mtp-int4-AutoRound | pp2048 @ d150000 | 1313.09 ± 0.56 | | 115872.26 ± 49.39 | 115793.81 ± 49.39 | 115879.31 ± 48.59 | | Qwen3.6-27B-heretic-v2-mtp-int4-AutoRound | tg480 @ d150000 | 59.53 ± 3.51 | 80.33 ± 2.05 | | | | | Qwen3.6-27B-heretic-v2-mtp-int4-AutoRound | pp2048 @ d200000 | 1128.87 ± 0.81 | | 179060.75 ± 127.67 | 178982.30 ± 127.67 | 179069.38 ± 127.94 | | Qwen3.6-27B-heretic-v2-mtp-int4-AutoRound | tg480 @ d200000 | 54.24 ± 1.72 | 74.33 ± 2.62 | | | |GPT分析
指標 結論 測試組合 cu130-0.20-int-4-autoround-mtp對比cu130-0.20-nvfp4-mtppp2048/ prefill t/sNVFP4 明顯較快;INT4 AutoRound 平均 prefill 約慢 51.5%短 context INT4 AutoRound 在純 pp2048約慢74.4%,d1000約慢67.6%中等 context d5000至d20000,INT4 AutoRound prefill 約慢55% - 62%長 context d50000以上 INT4 AutoRound 仍較慢,但差距縮小到約27% - 47%ttfr/e2e_ttftNVFP4 明顯較低;INT4 AutoRound 平均 TTFT 約高 124%tg480generation t/sINT4 AutoRound 平均約快 1.2%,但不是全面勝出peak generation t/s INT4 AutoRound 平均約快 4.9%,多數 context 的 peak 較高長 context generation 在 d150000和d200000,INT4 AutoRound 的平均 generation t/s 反而低於 NVFP4結論
在
cu130-0.20nightly 下,NVFP4 MTP 的主要優勢非常清楚:prefill throughput 和 TTFT 明顯好過 INT4 AutoRound MTP,尤其短到中等 context 差距很大。INT4 AutoRound MTP 的優勢主要在 decode / generation,平均
tg480稍快約1.2%,peak generation 約快4.9%,但長 context 下這個優勢不穩定,d150000和d200000反而較慢。整體而言,如果 workload 是 prompt-heavy、RAG、長 prompt prefill 或重視首 token 延遲,NVFP4 MTP 明顯較合適。若 workload 幾乎完全是 decode-heavy,而且可以接受較慢 TTFT,INT4 AutoRound MTP 才有比較價值。
理論上KV Cache可以透過使用
eugr/spark-vllm-docker的docker image用tq-t4nc來進一步降低 (FP8的一半), 引用vLLm自己的文章Pareto frontier for Qwen3-30B-A3B-Instruct-2507 on 2xH100. FP8 matches BF16 throughput at 2x capacity. TurboQuant variants extend capacity to 2.3-3.7x but at 40-52% throughput reduction.
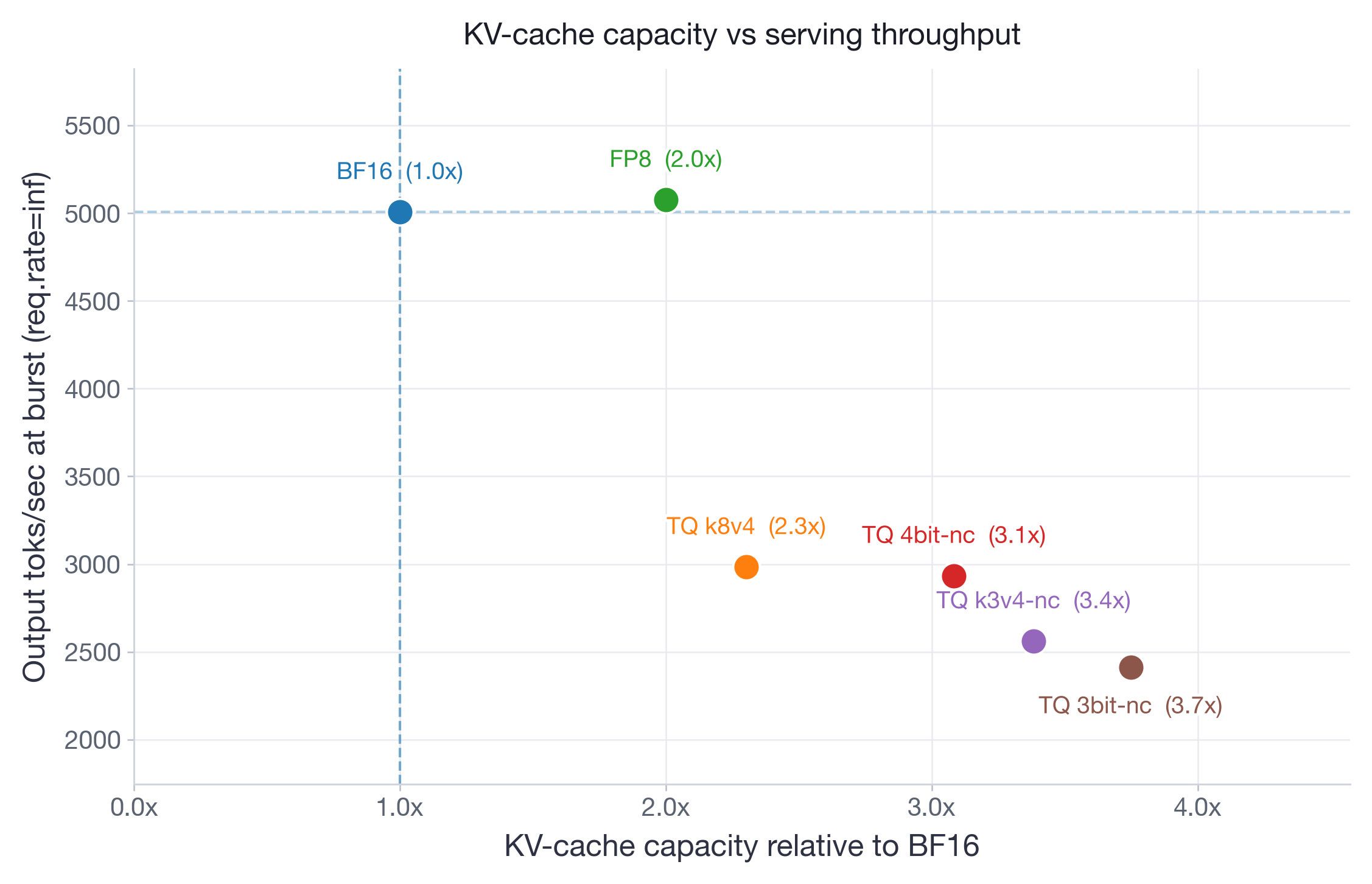
精度上也算可以接受吧
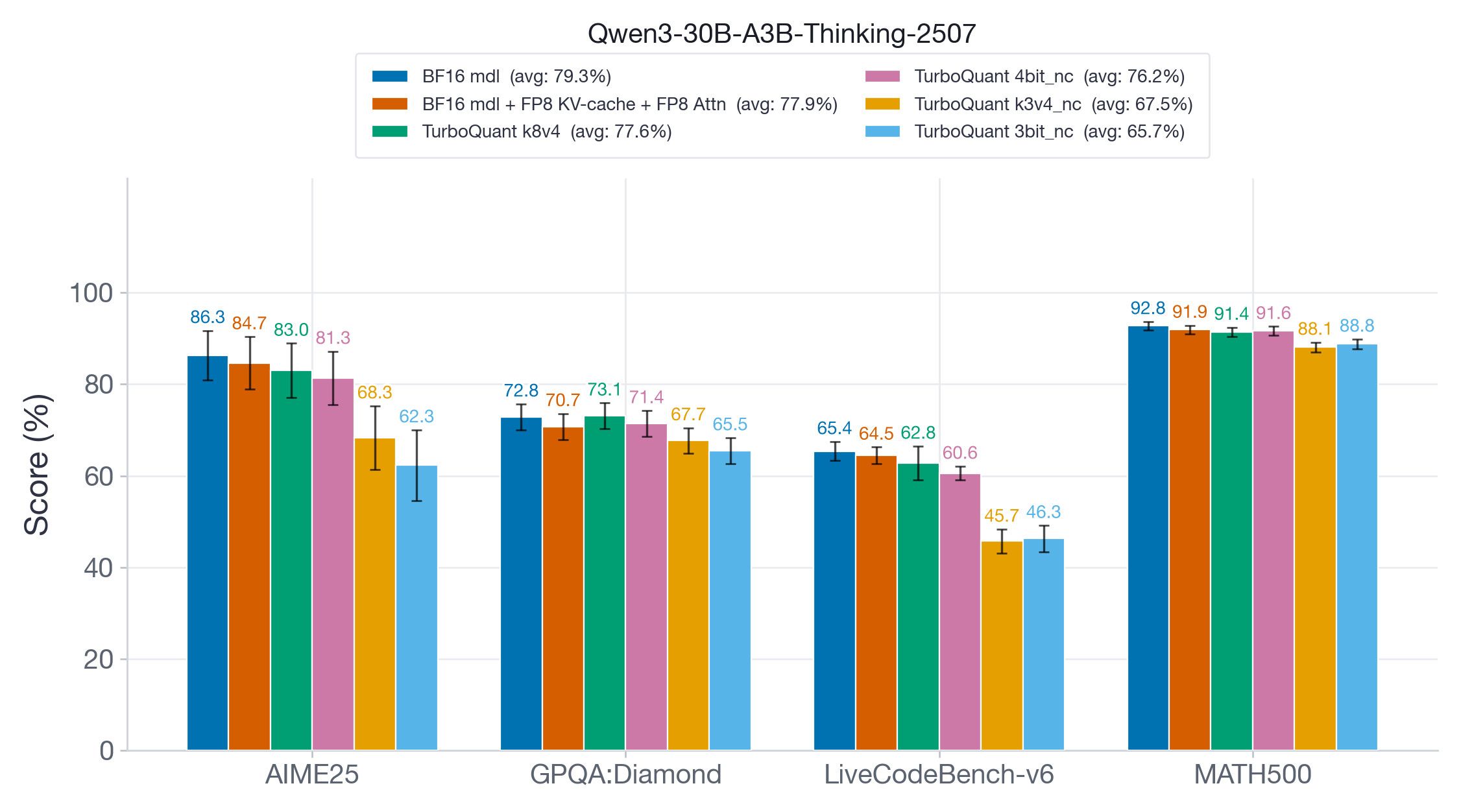
-
@566656661 香港便宜这么多啊,能不能带过来,还是要补税?这特么暴利啊
-
以下是研究途中的碎碎唸, 不感興趣的可以不看
碎碎唸1
看了蠻多文件跟大神文章, 有幾個值得留意的地方
Blackwell架構分成了Consumer Blackwell (sm 12x) 跟 Data Center Blackwell (sm 10x) 所有Geforce, RTX Pro, DGX Spark, RTX Spark都歸屬在Consumer Blackwell 其中最大的分別就是在於sm 12x缺少了tcgen05, 這也是Flash Attention 4裏面的核心技術 底層MMA邏輯裏用的還是SM8X, 也就是目前的Flash Attention 2 好家夥, 老黃這算不算是在欺詐啊...https://docs.vllm.ai/en/stable/configuration/env_vars/ v0.22 cu129可以在--linear-backend (前身VLLM_NVFP4_GEMM_BACKEND)使用flashinfer-b12x而不是flashinfer-cutlass MoE模型 (Qwen 3.6 35BA3B 跟 Gemma 4 26BA4B) 可以通過在--moe-backend 設置flashinfer_b12x 這個是特意為sm 12x架構優化的GEMM内核 約有30%throughput增長, https://github.com/vllm-project/vllm/pull/39634 這個我有點興趣先再試試看
碎碎唸2 (
吐槽)在一邊看vLLM文件一邊跑去問了Gemini, 講明了是Blackwell架構,居然還給了個
VLLM_MXFP4_BACKEND=marlin, 先不説直接無視掉NVFP4, marlin是給沒有FP4硬件加速的啊... (NVFP4或者MXFP4都可用)VLLM_FLASHINFER_MOE_BACKEND還給了throughput這個預設參數, 也沒改成--moe-backend flashinfer_cutlass(雖然這個在27b 模型沒用到)錯誤示範, 不要學
docker run -d \ --name vllm-Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP \ (中間省略) -e SERVED_MODEL_NAME="Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP" \ -e VLLM_ATTENTION_BACKEND="FLASHINFER" \ -e VLLM_MXFP4_BACKEND="marlin" \ -e VLLM_FLASHINFER_MOE_BACKEND="throughput" \ -e VLLM_USE_FLASHINFER_SAMPLER="1" \ -e VLLM_EXTRA_ARGS= (以下省略) -
@566656661 噪音怎么样?外置的是不是更明显?能用llama.cpp 测试一下吗?4500 比 9700 贵 1.2万,当时也看了很久,超预算了,一咬牙——没买。

-
@566656661 噪音怎么样?外置的是不是更明显?能用llama.cpp 测试一下吗?4500 比 9700 贵 1.2万,当时也看了很久,超预算了,一咬牙——没买。
-
小疑問 , 買RTX Pro 4500 為何不買 5090 ?
@fanwen1974 性價比問題。兩張卡價錢完全不同。
本身起始點是R9700, 小弟比較清窮,沒法子拿出個3,5,7萬出來爽爽
有能力的5090只是甜點,更應買更多VRAM
就小弟能力所限只可以買4500
功率低,比R9700好
最重要價錢相宜,能負擔(剛剛再問代理又漲價3000)
沒有最好,只有合適 -
小疑問 , 買RTX Pro 4500 為何不買 5090 ?
以混合用途LLM + 遊戲的話當然是5090 / 5090D比較好
但是整組組合一來只會作為伺服器使用, 不負責拿來玩ComfyUI, 核心再多性能也沒用, 最主要的瓶頸位在VRAM上面
二來5090燒接頭的問題讓我不太放心在沒人看著的時候用, 5090最低也有400w, 這張卡只有200w
三來香港的5090D跟5090其實比RTX Pro 4500還要更貴, 5090D現在已經沒有全新只有二手了, 最便宜2萬3, 正常2萬5以上, 還只剩最多2年的保養, 因大多數5090D卡都2025年年頭買, 保養到28年年頭, 正常5090已經是2萬8到3萬2了, 然後我這張卡2萬2, 全新3年保修
-
以混合用途LLM + 遊戲的話當然是5090 / 5090D比較好
但是整組組合一來只會作為伺服器使用, 不負責拿來玩ComfyUI, 核心再多性能也沒用, 最主要的瓶頸位在VRAM上面
二來5090燒接頭的問題讓我不太放心在沒人看著的時候用, 5090最低也有400w, 這張卡只有200w
三來香港的5090D跟5090其實比RTX Pro 4500還要更貴, 5090D現在已經沒有全新只有二手了, 最便宜2萬3, 正常2萬5以上, 還只剩最多2年的保養, 因大多數5090D卡都2025年年頭買, 保養到28年年頭, 正常5090已經是2萬8到3萬2了, 然後我這張卡2萬2, 全新3年保修
-
以混合用途LLM + 遊戲的話當然是5090 / 5090D比較好
但是整組組合一來只會作為伺服器使用, 不負責拿來玩ComfyUI, 核心再多性能也沒用, 最主要的瓶頸位在VRAM上面
二來5090燒接頭的問題讓我不太放心在沒人看著的時候用, 5090最低也有400w, 這張卡只有200w
三來香港的5090D跟5090其實比RTX Pro 4500還要更貴, 5090D現在已經沒有全新只有二手了, 最便宜2萬3, 正常2萬5以上, 還只剩最多2年的保養, 因大多數5090D卡都2025年年頭買, 保養到28年年頭, 正常5090已經是2萬8到3萬2了, 然後我這張卡2萬2, 全新3年保修
@566656661 了解,可能我在臺灣,5900 跟 RTX 4500 差不多價錢,才有這個疑問。臺灣的 RTX Pro 都太貴。開個COMPUTEX , RTX Pro 6000 本來 38 萬 變 48 萬,神經病~
-
@566656661 現在還買得到這個價位的嗎?
有的話我可以飛一趟香港。 -
@566656661 了解,可能我在臺灣,5900 跟 RTX 4500 差不多價錢,才有這個疑問。臺灣的 RTX Pro 都太貴。開個COMPUTEX , RTX Pro 6000 本來 38 萬 變 48 萬,神經病~
-
2萬5
還是比13萬台幣便宜很多....蠻心動的,缺點應該是保固要送回香港

 ️
️

 )
)