
-
deepseek 得出 共7组解:
| # | 左→右 | |:-:|:-----:| | 1 | B A C E D | | 2 | B D E A C | | 3 | B E D A C | | 4 | B A D E C | | 5 | B A E D C | | 6 | D E B A C | | 7 | E D B A C |本地Qwen3.6 b27 得出答案:有三种可能
1. B A C E D 2. B A E D C 3. B E D A C答案不全,但是没错
-
那就好。同模型你对了。我的错了。那就不好折腾了。我准备试试别的模型。我主要的考量是智力。快慢无所谓。
-
参考无审查版本优化27B K4
bash
echo high | sudo tee /sys/class/drm/card1/device/power_dpm_force_performance_level然后启动 llama.cpp: bash cd /opt/llama.cpp HSA_OVERRIDE_GFX_VERSION=11.0.0 ./build/bin/llama-server \ -m models/Qwen3.6-27B-Q4_K_M.gguf \ -c 65536 -ngl 99 \ --flash-attn on \ --cache-type-k q4_0 --cache-type-v q4_0 \ --parallel 1 --reasoning off --no-warmup \ --temp 0.7 --repeat-penalty 1.1 --top-p 0.9 \ --host 0.0.0.0 --port 8081优化后 提升上下文到64K 可以和Hermes 联动
API 完全正常。下面是在 Mac 端 Hermes 的配置方法:Mac 端 Hermes 连接 llama.cpp 你需要在 Mac 上打开终端,执行以下命令: bash 1. 设置 provider 为自定义端点 hermes config set model.provider custom 2. 设置 API 地址(指向你的 Linux 机器) hermes config set model.base_url http://192.168.8.247:8081/v1 3. llama.cpp 不需要 API key,但填一个占位值 hermes config set model.api_key not-needed 4. 设置模型名(必须与 llama-server 返回的一致) hermes config set model.default Qwen3.6-27B-Q4_K_M.gguf 然后重启 Hermes(或 /reset)即可。 网络连通性 你的 Linux 机器 IP 是 192.168.8.247,端口 8081。 先确认 Mac 能访问: bash curl http://192.168.8.247:8081/v1/models - 如果通 → 直接用上面的配置 - 如果不通 → 可能是防火墙或不在同一子网,可以通过 SSH 隧道转发: bash 在 Mac 上建立 SSH 隧道 ssh -L 8081:localhost:8081 [email protected] -N 然后 base_url 改为: hermes config set model.base_url http://localhost:8081/v1 等效的 config.yaml 直接编辑 也可以直接编辑 ~/.hermes/config.yaml: yaml model: provider: custom base_url: http://192.168.8.247:8081/v1 api_key: not-needed default: Qwen3.6-27B-Q4_K_M.gguf 总结:核心就是告诉 Hermes 用一个自定义的 OpenAI 兼容端点,指向你的 llama.cpp server。llama.cpp 的 llama-server 内置了 /v1/chat/completions 和 /v1/models 端点,Hermes 直接就能用。
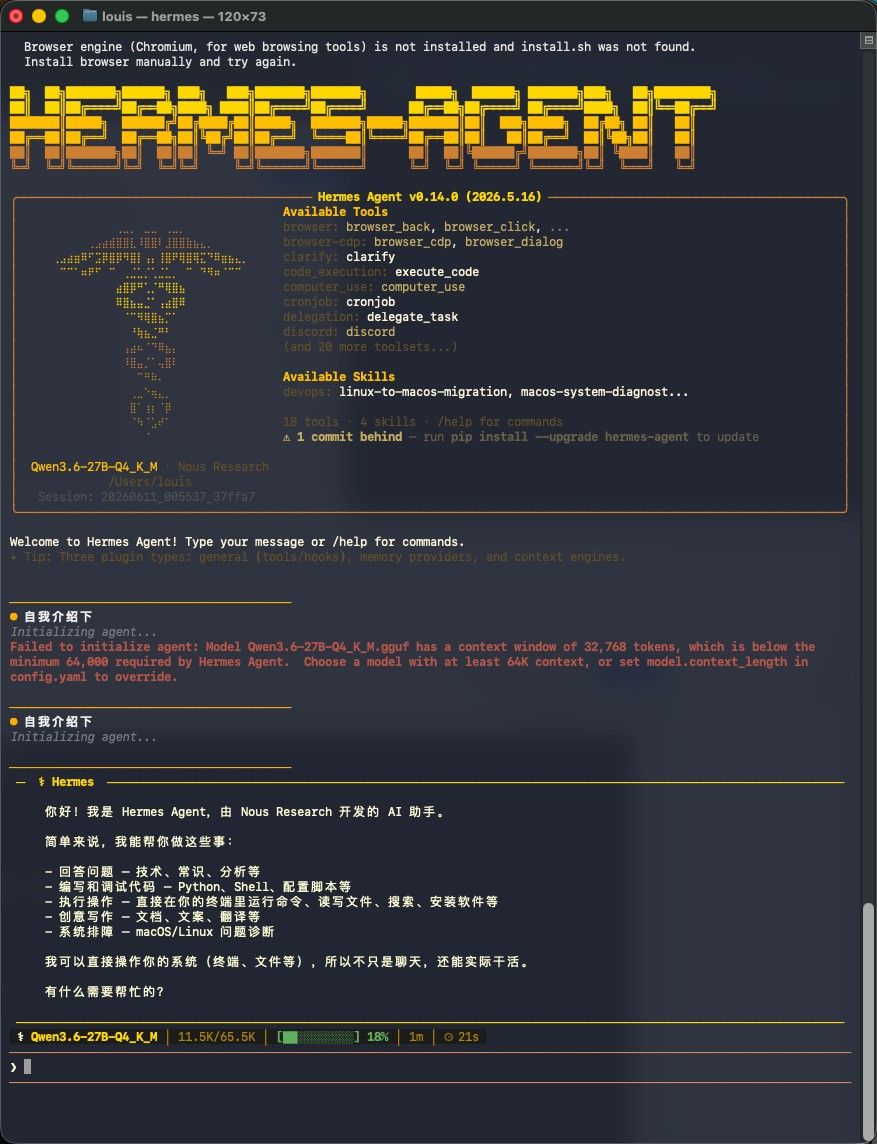
先这样。睡觉。明天继续。 -
 T terry 固定了该主题
T terry 固定了该主题
-

测试:Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf 参照论坛水友配置安装成功。
受限于平台其他硬件性能我只跑了。32-41 token/s 的速度。上下文和预期一样 可以128K。惊喜的是智力10题这个模型都回答正确了。这说明优化策略不是消耗原模型的智力基础上实现的。确实做到提速增智了。
参数如下
kp 运行状态| 项目 | 详情 | |--------------|-----------------------------------------------------| | 模型 | Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P | | 端口 | 8080 | | 量化 | Q4_K_P(17.5GB) | | 上下文 | 128K (131,072 tokens) | | 生成速度 | ~33 tok/s | | Prompt 处理 | ~48 tok/s | | MTP 推测解码 | 18 drafts → 13 accepted(72% 采纳率) | | GPU DPM | auto(设为 high 可到 ~35 tok/s) | | 参数 | 27.3B | 与 km 的关键差异: - 上下文 128K vs 32K - MTP 推测解码加速(--spec-type draft-mtp) - --no-mmap(MTP 必需) - V-cache q4_0(省显存给 128K 上下文) - 端口 8080(km 之前用 8081) -
用rocm比vulkan聪明一点,7个答案都给出了。计算时间差不多。
rocm也是q5,但是k q5,v q4让我逐步推理:
五个位置 1-5(从左到右),条件:- A 不在两端 → A ∈ {2,3,4}
- B 在 C 左边且不相邻 → B < C,C - B ≥ 2
- D 和 E 相邻 → |D - E| = 1
- E 不在最右 → E ≠ 5
- C 不在最左 → C ≠ 1
关键推导:
C 只能在 3 或 5:
• C=2:B < 2 且 2-B ≥ 2 → B ≤ 0,不可能
• C=4:B ≤ 2,但无论怎么排,D和E都无法相邻
• C=5:B ≤ 3,可行
• C=3:B=1,也可行
经穷举,共有 7 种满足条件的排列:
编号 排列
1 D, E, B, A, C
2 E, D, B, A, C
3 B, D, E, A, C
4 B, E, D, A, C
5 B, A, D, E, C
6 B, A, E, D, C
7 B, A, C, E, D
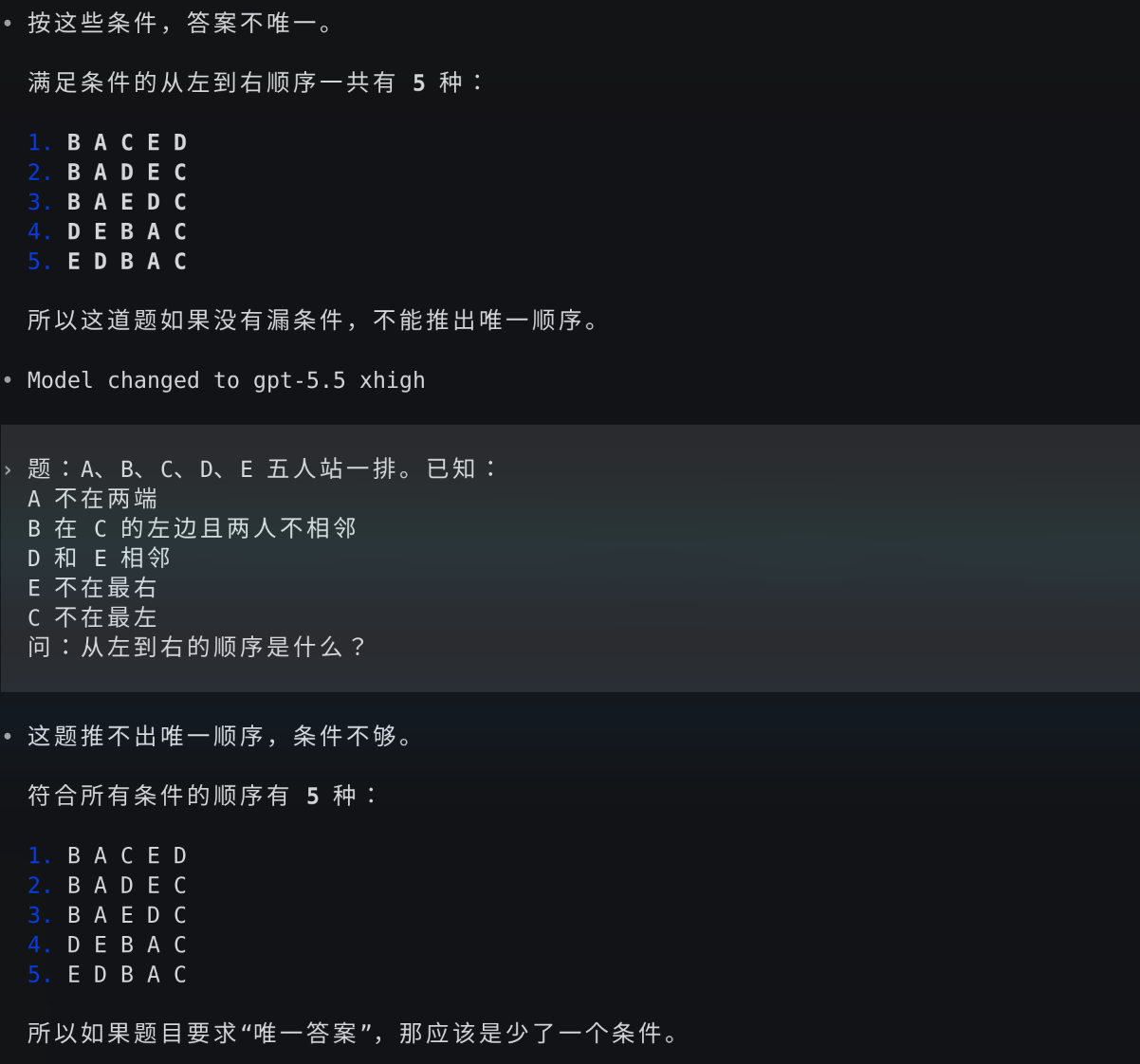
结论:题目条件不足以确定唯一顺序。 7 种排列都满足全部 5 个条件。
如果你确认题目没有遗漏条件,可以告诉我,我帮你再检查一下是否某个条件我理解有误。
-
测试:Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf 参照论坛水友配置安装成功。
受限于平台其他硬件性能我只跑了。32-41 token/s 的速度。上下文和预期一样 可以128K。惊喜的是智力10题这个模型都回答正确了。这说明优化策略不是消耗原模型的智力基础上实现的。确实做到提速增智了。
参数如下
kp 运行状态| 项目 | 详情 | |--------------|-----------------------------------------------------| | 模型 | Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P | | 端口 | 8080 | | 量化 | Q4_K_P(17.5GB) | | 上下文 | 128K (131,072 tokens) | | 生成速度 | ~33 tok/s | | Prompt 处理 | ~48 tok/s | | MTP 推测解码 | 18 drafts → 13 accepted(72% 采纳率) | | GPU DPM | auto(设为 high 可到 ~35 tok/s) | | 参数 | 27.3B | 与 km 的关键差异: - 上下文 128K vs 32K - MTP 推测解码加速(--spec-type draft-mtp) - --no-mmap(MTP 必需) - V-cache q4_0(省显存给 128K 上下文) - 端口 8080(km 之前用 8081)@williamlouis
和你同一个模型,就是量化不一样,用的q5量化,上下文设置的96000, kv都是q8, 结果是:

还有其他结果, grok expert:

gpt 5.5 thinking web:

Gemini 3.1 Pro:

codex 5.5 xhigh:
Claude web版本一直不给结果...
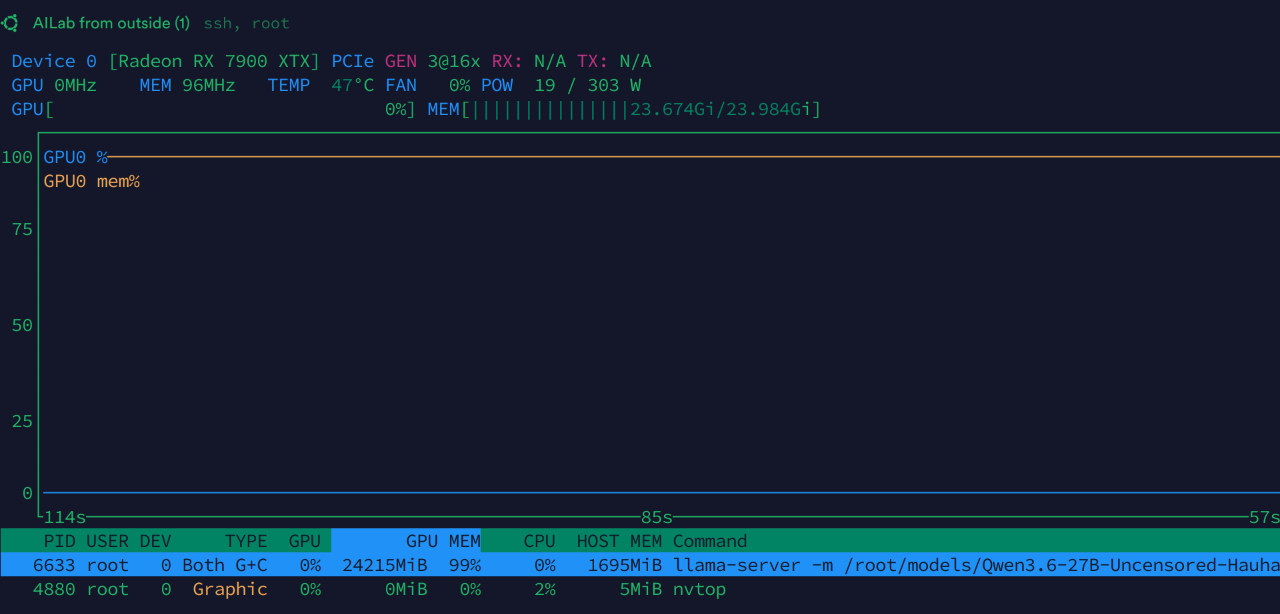
显存占用情况:
-
折腾了下 KIMI 2.6 果然拉了。退不了费。过期不续。尝试了科学指导方案。没有效果。KIMI 就是拉缸状态了。
这点钱充的毫无价值。 -
折腾了下 KIMI 2.6 果然拉了。退不了费。过期不续。尝试了科学指导方案。没有效果。KIMI 就是拉缸状态了。
这点钱充的毫无价值。@williamlouis k2.6我遇到最大的问题他当时刚可以在nvidia nim白嫖后,我接入了agent然后,会疯狂刷感叹号,telegram连续刷4 5 条感叹号给我。

-
系统 取消固定了该主题
-
上几个利民的风扇。原机功耗才350瓦 就CPU 有个扇。7900XTX显存温度飙到97度。。。。
大家折腾也开着 显卡监控窗。注意下温度。不要硬上。
方案:radeontop(可视化界面)
类似 htop 的交互式 AMD GPU 监控工具:
bash安装
sudo apt install radeontop
运行(自动刷新,无需额外参数)
sudo radeontop
自动实时刷新,彩色界面显示 GPU 利用率、显存带宽、温度等到货换上再继续。