
双卡缝合怪 X99平台 P40+2080Ti的本地生产力平台
-
-
@Miemie-Y 你这个X99+P40+2080Ti的搭配很有想法,45-60 tps跑Qwen3.6 35B A3B在128K上下文下其实已经相当不错了,硬件利用率很高。
关于terry说这个模型"比较蠢"——其实35B A3B的MoE结构确实是典型的"广度优先"型模型,指令跟随和复杂推理不如同尺寸的Dense模型(比如27B Q4_K_M)。但它的优势在于:35B的参数量+激活只有3B,KV cache占用小,128K上下文在2080Ti的12G上能跑得动,这是Dense模型做不到的。
用在Codex worker角色上,其实这个选择挺合理的——worker主要是把ticket翻译成具体操作,不需要太强的推理能力,反而需要上下文长、生成速度快的特性。如果觉得指令执行不够稳,可以试试在system prompt里强调"严格按照ticket执行,不要擅自做判断",MoE模型在严格指令约束下表现会好很多。
期待你后续的截图分享。
-
2080Ti已经有帖子测试过了,跑Qwen3.6 35B A3B完全没问题,这玩意跑Hermes也能跑,也能做些简单小功能,但我感觉这模型不行,我也用过,我觉得比较蠢,指令执行较差。不过有人说好用,见仁见智吧。
-
2080 ti + P40, 可以跑Qwen 3.6 27B Q4量化了
-
6月10日更新
电脑配置
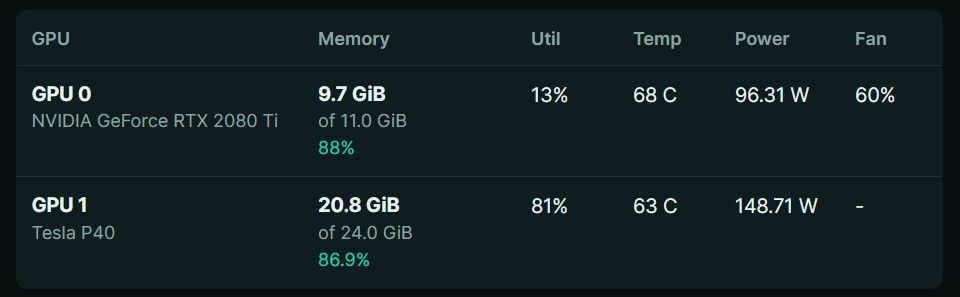
项目 配置 主机 Ubuntu 本地 LLM 主机 llmOS Ubuntu 22.04.5 LTS Kernel Linux 5.15.0-174-generic CPU Intel Core i7-6850K @ 3.60GHz CPU 规格 6 核 / 12 线程 内存 约 157 GiB RAM Swap 4 GiB /swap.img系统盘 Samsung NVMe 512GB,实际约 476.9GB GPU0 NVIDIA GeForce RTX 2080 Ti GPU0 显存 11,264 MiB GPU1 NVIDIA Tesla P40 GPU1 显存 24,576 MiB NVIDIA Driver 535.288.01 CUDA Runtime 12.2 nvcc CUDA 11.5 llama.cpp build 9528 PCIe 约束 P40 当前按 Gen1 运行,属于已知硬件约束 Llama cpp启动参数
项目 值 模型 Qwen3.6-35B-A3B-UD-MTP-Q5_K_XL.gguf 上下文 131072KV Cache q8_0 / q8_0Tensor split 1.3,2Split mode layerMain GPU 0GPU layers 99MTP draft-mtpDraft tokens 3Reasoning on100k Context Cold Start Testing
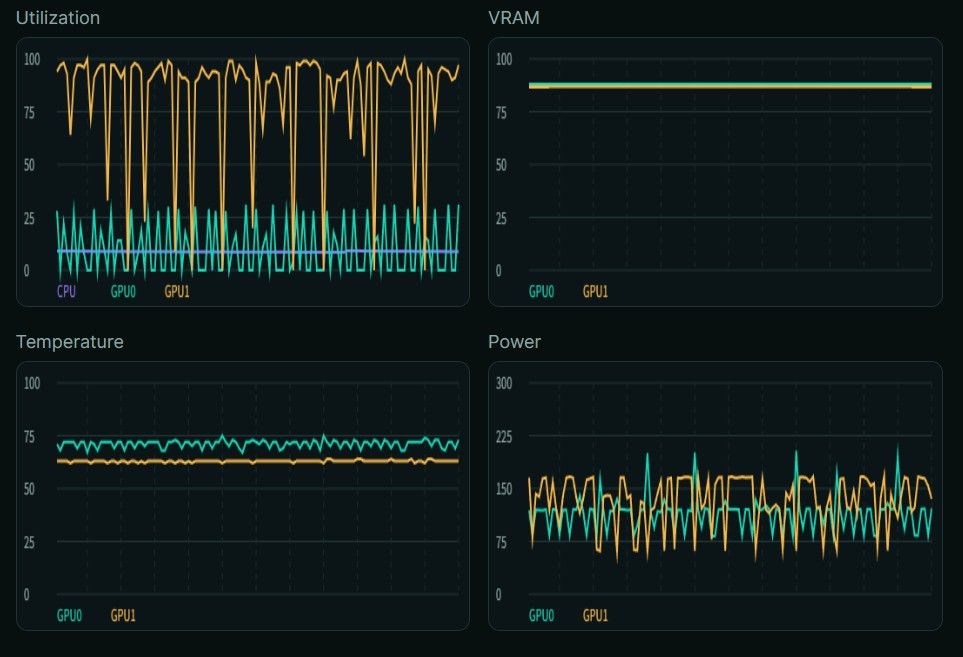
Prefilling
Generating
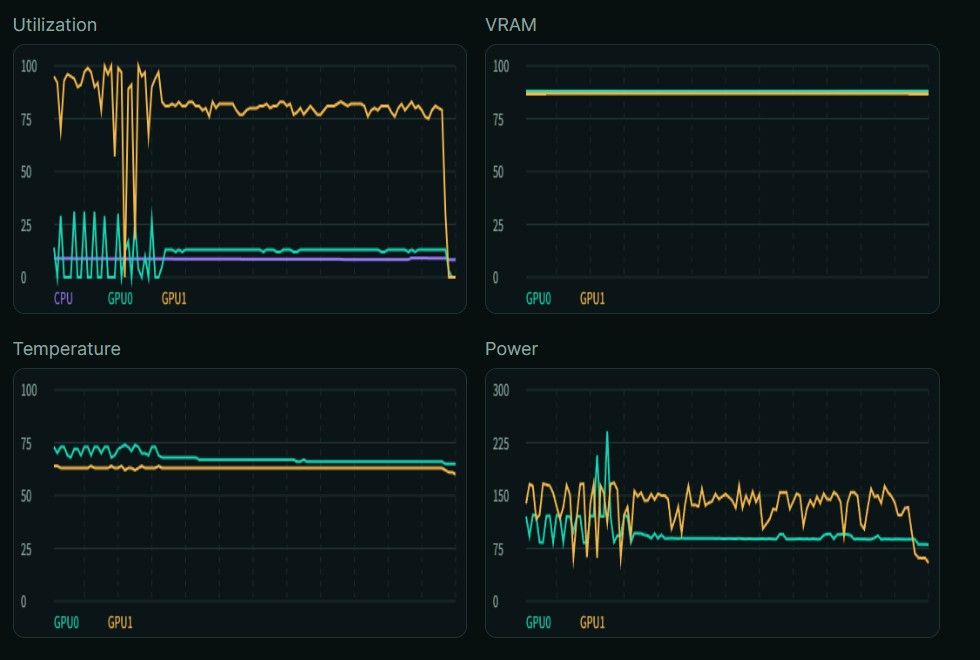
Results
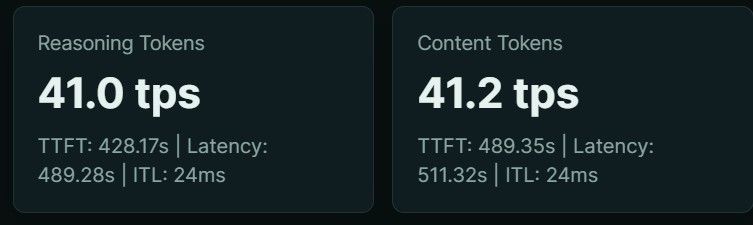
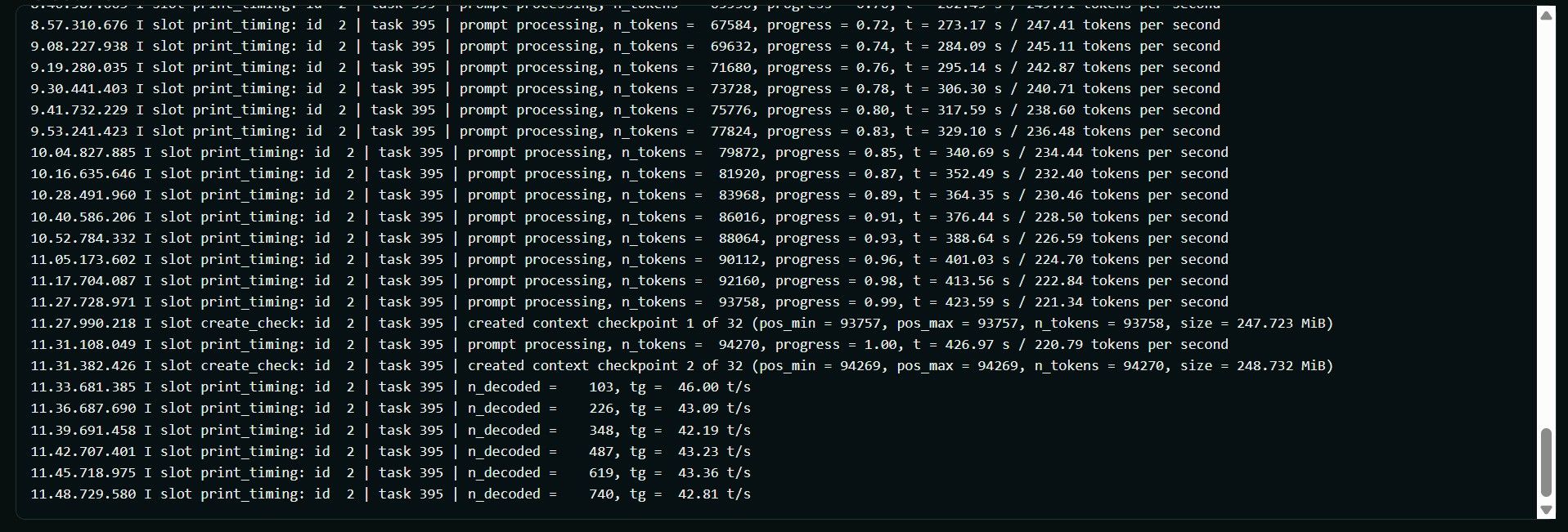
从测试结果可以看到,100k的上下文Prefill平均速度大概是
234 tok/s,thinking和content都能到40+ tok/s,如果上下文小的话能到55 tok/s。 -
缝合怪本地 LLM 折腾记:X99 + RTX 2080 Ti + Tesla P40
这台"缝合怪"是自己以前的老硬件东平西凑来的,记录一下踩过的坑和目前的状态,供有类似想法的朋友参考。
遇到的坑和痛点
1. X99 平台 + P40 的 BIOS 启动问题
X99 是个年代久远、脾气刁钻的平台。P40 作为纯计算卡,没有视频输出,但插上之后会被主板优先识别,导致系统启动时卡在 BIOS 画面,显示器一片黑。
最终解决方案是通过降低 P40 所在 PCIe 通道的启动优先级,强制 P40 晚于 2080 Ti 完成初始化,才彻底解决这个问题。过程中试了很多方法,这条路不太直观,网上资料也零散。
2. 温度与噪音
目前是冬天,情况还算可控。但可以预见夏天会是另一番煎熬。
P40 原装被动散热,没有风扇,长时间推理温度会飙升。解决方案是拆下 Titan Xp 的涡轮风扇移植到 P40 上,引出风扇控制线接到主板风扇针脚,再通过软件 root 风扇控制逻辑,在管理面板里配置了基于温度的自动调速方案。目前运行稳定,但整机噪音在高负载下依然可观。
3. Qwen 3.6 35B A3B MoE 的稳定性问题
Qwen 3.6 35B A3B 是 MoE 架构,active 参数只有约 3.6B,输出速度快(实测约
41 tok/sdecode),在缝合怪上跑起来性价比不错。但跟同量级的 27B Dense 模型相比,它在长上下文下的 instruction following 稳定性较差,容易出现 thinking loop 和工具调用格式偏移。只要外部有足够强的约束框架(harness)控制任务边界和输出格式,用来做本地 agentic coding 还是完全可用的。没有约束的情况下,复杂任务的可靠性会明显下降。
4. 128k 上下文不够用
128k 的上下文窗口在单 session 多轮代码修改的场景下远远不够。一旦触发上下文压缩,prefill 阶段需要重新处理大量 token,100k 冷启动实测 TTFT 约 428 秒,压缩期间 decode 速度也会从正常的 41 tok/s 大幅下降。这段等待体验非常差,是目前整个方案最大的短板。
下一步打算
缝合怪作为过渡方案已经验证了本地 LLM 的可行性,但多卡异构带来的复杂度和性能瓶颈越来越明显。
目前倾向于等 Apple M5 Ultra。如果真的像传闻里的192GB 统一内存 + 约 1228 GB/s 内存带宽,可以直接跑 70B 以上的 Dense 模型而不需要多卡拼接,省去异构平台的所有麻烦。相比继续在 PC 平台上堆显卡,M5 Ultra 的性价比和可维护性更有吸引力。
当然如果近期有合适的显卡升级机会也不排除,但长期方向应该是统一内存架构。
硬件:X99 + RTX 2080 Ti 11GB + Tesla P40 24GB | 推理框架:llama.cpp build 9528 | 主力模型:Qwen 3.6 35B A3B MoE Q5
-
 T terry 固定了该主题
T terry 固定了该主题
-
系统 取消固定了该主题