
🔥 Lucebox DFlash 在 7900 XTX 上跑 Qwen3.6-27B — 完整复现与实测报告
-
Colt 说:
cmake -B server/build -S server -DCMAKE_BUILD_TYPE=Release -DDFLASH27B_GPU_BACKEND=hip -DCMAKE_HIP_ARCHITECTURES=gfx1100 -DROCM_PATH=/opt/rocm-7.2.3 -DDFLASH27B_HIP_SM80_EQUIV=ON -DCMAKE_C_STANDARD=11 -DCMAKE_CXX_STANDARD=17 -DGGML_CCACHE=OFF
还是靠Hermes,它5秒就定位问题,然后搞定了。编译的时候不能用 -DCMAKE_HIP_ARCHITECTURES=gfx1100。
@Colt 哈哈,我家的agent也在帮你看问题,然后我滚下来之后就看到你解决了
然后反正token都耗了,我也扔出来给你、或者其他人参考下吧这位老哥的 Segmentation fault 崩溃非常经典,在预填充阶段([prefill] token-seg ubatch=32)直接炸在 libamdhip64.so 里面,说明他在编译或者环境加载上中了这四个暗箭:
 致命诊断与排坑指南
致命诊断与排坑指南- 动态链接库“张冠李戴”
 ️ (最可能导致 segfault 的根源)
️ (最可能导致 segfault 的根源)
-
病因:看他的命令里写的是 LD_LIBRARY_PATH=/opt/rocm/lib:$LD_LIBRARY_PATH。但是他的编译参数指定的是 -DROCM_PATH=/opt/rocm-7.2.3!
-
危害:如果系统里的 /opt/rocm 是一个软链接,但其实指向了另外一个版本的旧 ROCm (比如 6.x 或 7.1),那么运行 test_dflash 时加载的动态库与编译时的头文件就会发生 ABI 冲突。只要跑 GPU 算子,必报 general protection fault 闪退!
-
解药:运行时必须显式指定与编译路径完全一致的 7.2.3 库文件目录:
export LD_LIBRARY_PATH=/opt/rocm-7.2.3/lib:$LD_LIBRARY_PATH
- 去掉“毒药参数” -DDFLASH27B_HIP_SM80_EQUIV=ON 🧪
- 病因:这个参数是用于把 NVIDIA Ampere (SM80) 的指令在 AMD 硬件上做等效处理的。但在我们 7900 XTX (Navi 31 / gfx1100) 这种消费级显卡上,ROCm 7.2 自身的 HIP 编译器其实已经能非常优秀地进行原生编译了。盲目开启 SM80 转换,反而容易在 GPU prefill 跑算子时产生不兼容的硬件指令。
- 解药:在 7900 XTX 纯 A 卡环境的编译中,直接把这个参数去掉!
- 显式开启全量化,且必须彻底清除缓存 🧼 (我们踩出来的超级大坑)
- 病因:他用的是 Q4_K_M 这种 K-quant 模型。如果 DFlash 编译时缺省没有开启所有的 KV-quant 模板,计算注意力时就会找不到匹配,要么直接 abort,要么因为 fallback 到在 HIP 上极不稳定的 TILE kernel 导致 segfault!
- 解药:重新 cmake 时显式指定 -DDFLASH27B_FA_ALL_QUANTS=ON。而且最重要的一点:必须使用 --clean-first!如果直接 build,cmake 不会重编 HIP 核心,老代码还是会原地爆炸。
-
正确的编译步骤:
cmake -B server/build -S server
-DCMAKE_BUILD_TYPE=Release
-DDFLASH27B_GPU_BACKEND=hip
-DCMAKE_HIP_ARCHITECTURES=gfx1100
-DROCM_PATH=/opt/rocm-7.2.3
-DDFLASH27B_FA_ALL_QUANTS=ON
-DCMAKE_C_STANDARD=11
-DCMAKE_CXX_STANDARD=17
-DGGML_CCACHE=OFF彻底清理并重编
cmake --build server/build --target ggml-hip --clean-first -j$(nproc)
cmake --build server/build --target test_dflash -j$(nproc)
-
- 参数没有喂饱,换用环境变量卡死
 ️
️
-
病因:看他的日志输出 [cfg] ... fa_window=2048 ...。这说明他在命令行传的 --fa-window 0 根本没有被解析成功!DFlash 还在用 2048 窗口,所以在 prefill 时发生了越界。
-
解药:在运行命令前直接用环境变量卡死它,最稳妥:
export DFLASH27B_FA_WINDOW=0
或者把命令最后的参数改成用等号连接:
--fa-window=0
- 动态链接库“张冠李戴”
-
@abaalei 大佬要不也嘗試下虛擬化方案? 我是走 PVE 顯卡直通,這樣可以同時 A+N 雙開任務

項目 品牌 規格 主機板 ASUS ProArt B850-CREATOR WIFI NEO CPU AMD Ryzen 9 9950X3D,16C / 32T CPU FAN DeepCool Digital ASSASSIN IV VC VISION FAN Noctua 12" PWA、14" FN 記憶體 Kingston DDR5 64GB,32GB x 2 顯示卡 AMD Radeon AI PRO R9700 顯示卡 NVIDIA RTX 3090 有線網路 Realtek RTL8126 5GbE x 2 無線網路 Realtek RTL8922AE Wi-Fi 7 / 802.11be 系統碟 Crucial / Micron T500 NVMe SSD,約 2TB 資料碟 Samsung 980 / PM9A1 類 NVMe SSD,約 477GB Windows 系統碟 Predator / Biwin NVMe SSD,約 1TB,獨立 Windows 11 系統,主要用途:星際公民 電源 NZXT 1500W Case Cooler Master QUBE 540 這是當前 PVE 實驗室佈局的簡短操作快照。詳細設定說明請參閱
Machines.md、Runbook.md及worklog/。主機 (Host)
項目 數值 PVE 主機 IP 角色 Hypervisor、NFS/共享儲存、子網路由 硬體 AMD 9950X3D, 64 GB RAM, 2 TB NVMe 已安裝 GPU AMD Radeon AI PRO R9700 32GB, ZOTAC RTX 3090 24GB GPU 資源映射 (GPU Resource Mappings)
映射名稱 GPU PCI 路徑 IOMMU 分組 規則 gpu-r9700AMD Radeon AI PRO R9700 32GB 0000:03:0016 指派給 VM100 或 VM103,不可同時指派 gpu-rtx3090ZOTAC NVIDIA GeForce RTX 3090 24GB 0000:05:0019 指派給 VM104 或 VM105,不可同時指派 虛擬機群組 (VM Groups)
群組 VM ID GPU 映射 用途 備註 AMD / ROCm 100 gpu-r9700主 R9700 實驗 VM ROCm, vLLM, llama.cpp, TRELLIS.2 ROCm AMD / ROCm 103 預設 gpu-r9700實驗協同 / 備用 GPU VM 與 VM100 共用 R9700;可切換至 RTX 3090 進行測試 NVIDIA / CUDA 104 gpu-rtx3090CachyOS 圖形介面與 NVIDIA 桌面測試 與 VM105 共用 RTX 3090 NVIDIA / CUDA 105 gpu-rtx3090CUDA LLM 與 ComfyUI/TRELLIS.2 實驗 主 RTX 3090 基準測試 VM 服務 101 無 閘道服務 LiteLLM, 儀表板, 排程器, 常駐服務 當前實驗路線 (Current Experiment Lines)
VM ID 當前路線 100 R9700 ROCm 推理, vLLM, llama.cpp, TRELLIS.2 ROCm 103 協同開發沙盒;可重複使用 R9700 或臨時切換至 RTX 3090 104 NVIDIA 圖形介面, CachyOS, vkmark, 桌面/GPU 驅動驗證 105 RTX 3090 CUDA, LLM 基準測試, ComfyUI, TRELLIS.2, Gradio 排程規則 (Scheduling Rules)
- VM100 和 VM103 不能同時使用
gpu-r9700。 - VM104 和 VM105 不能同時使用
gpu-rtx3090。 - VM103 可以在
gpu-r9700和gpu-rtx3090之間切換,但不得與目前正在使用該映射的虛擬機發生衝突。 - 閘道 VM101 應保持獨立,不參與 GPU 實驗。
@CS6
感谢大佬的安利!看着大佬的 Ryzen 9 9950X3D + R9700 32G + 3090 24G 豪华 PVE 实验室,我的眼泪直接从嘴角流了出来……(虽然这段是AI打的,但是完全说中了我的真心话,我在买7900xtx之前的这段时间,基本上把从mi50~4080super都意淫了一个遍,最后迫于压力只能选择7900xtx,毕竟目前加卡对我来说还只是玩具,不详版主那么厉害,都能拿来当生产力赚钱了)这套 A+N 双 VM 直通隔离和 gateway 独立调度的架构设计,简直是生产力用户的终极梦幻装!关于 PVE 显卡直通方案,我之前在规划这台算力节点时也深度考虑过(我之前在HP Gen8也有玩过pve,但是目前对我来说不太合适),但结合我目前的硬件现状,最终还是选择了 Ubuntu 物理机直驱 + 进程分流 的软隔离路线。主要出于以下几点折腾痛点:
- 双路 E5 的“单核瓶颈”与 NUMA 跨 Socket 延迟

我的 CPU 是老旧的双路 E5-2682 v4,这代 Broadwell 核心的单核性能放到今天真的非常弱(主频低、单核 IPC 差)。跑大模型推理时,尤其是 DFlash / llama.cpp 的 Prefill 预填充阶段,对 CPU 单核性能和内存延迟极其敏感。如果走 PVE 虚拟化,在弱鸡单核上再剥离一层虚拟化损耗,再加上双路 NUMA 架构下虚拟机跨物理 CPU 调度的延迟,很容易在 Prefill 阶段被卡死,把 GPU 的高速带宽白白浪费掉。
- X99 主板的 IOMMU 分组玄学

华南这类寨板的 ACS 隔离和 IOMMU 划分往往非常狗血,经常会把 PCIe 插槽和板载 SATA、USB 控制器划分在同一个 Group 里,强行直通可能需要打 pcie_acs_override 内核补丁,稳定性难以保障(我们昨晚刚在华南 X99-6Plus 上翻过车。把 7900 XTX 塞进 5 槽(CPU0通道),系统加载后,板载网卡和 3 槽的 2.5G 独立网卡(RTL8125,插在pciex8插槽)直接物理掉线(PHY 灯全灭)。最后根本跑不通,只能退回折腾了5小时,最终在加 pcie_aspm=off 并写 systemd 脚本开机强行重载 r8169/r8125 驱动才把网卡拉起来。这种寨板在 PCIe 分配和硬件兼容性上全是玄学,玩 PVE 直通随时都会面临 Host 彻底失联的灾难,所以只能物理机直驱加 pm2 分流软隔离了……)。
- 物理机层面的“软分流”隔离
 ️
️
好在双路 X99 最大的优势是 PCIe lanes(通道数)多到用不完。目前我的 7900 XTX 和 3080 Ti 都跑在全速槽上。在软件层面:- 大模型推理:走 ROCm 后端,ROCm 天然就不认 NVIDIA 显卡,所以大模型推理自动锁死在 7900 XTX 上,吃满 24G 显存。
- 视频后处理 / 变声 (VoxCPM):我直接在 pm2 启动脚本里用 CUDA_VISIBLE_DEVICES 将 3080 Ti 隔离出来专门处理。
通过 pm2 进程管理,基本做到了“物理不拆卡,环境不污染,带宽不冲突”,算是压榨这台老 X99 主板剩余价值最省心的路子了。
顺便同步一下进度,我用 bench_he.py(10 HumanEval)在 DFlash 完整编译(FA_ALL_QUANTS=ON + --fa-window 0)下,跑 Huihui 真无审查 Q4_K_M 模型,7900 XTX 实测已经飚到了 81.38 tok/s!(在我的另一个贴上发了,虽然上下文只有32K)物理通道和驱动潜力几乎被榨干了。
大佬的那块 AI PRO R9700 32GB 实在太香了,32G 显存跑 vLLM 的 KV cache 简直可以横着走,未来如果有什么好玩的工作流或测试数据,求大佬多发帖分享,让我也饱饱眼福!
- VM100 和 VM103 不能同時使用
-
@Colt 哈哈,我家的agent也在帮你看问题,然后我滚下来之后就看到你解决了
然后反正token都耗了,我也扔出来给你、或者其他人参考下吧这位老哥的 Segmentation fault 崩溃非常经典,在预填充阶段([prefill] token-seg ubatch=32)直接炸在 libamdhip64.so 里面,说明他在编译或者环境加载上中了这四个暗箭:
致命诊断与排坑指南- 动态链接库“张冠李戴” ️ (最可能导致 segfault 的根源)
-
病因:看他的命令里写的是 LD_LIBRARY_PATH=/opt/rocm/lib:$LD_LIBRARY_PATH。但是他的编译参数指定的是 -DROCM_PATH=/opt/rocm-7.2.3!
-
危害:如果系统里的 /opt/rocm 是一个软链接,但其实指向了另外一个版本的旧 ROCm (比如 6.x 或 7.1),那么运行 test_dflash 时加载的动态库与编译时的头文件就会发生 ABI 冲突。只要跑 GPU 算子,必报 general protection fault 闪退!
-
解药:运行时必须显式指定与编译路径完全一致的 7.2.3 库文件目录:
export LD_LIBRARY_PATH=/opt/rocm-7.2.3/lib:$LD_LIBRARY_PATH
- 去掉“毒药参数” -DDFLASH27B_HIP_SM80_EQUIV=ON 🧪
- 病因:这个参数是用于把 NVIDIA Ampere (SM80) 的指令在 AMD 硬件上做等效处理的。但在我们 7900 XTX (Navi 31 / gfx1100) 这种消费级显卡上,ROCm 7.2 自身的 HIP 编译器其实已经能非常优秀地进行原生编译了。盲目开启 SM80 转换,反而容易在 GPU prefill 跑算子时产生不兼容的硬件指令。
- 解药:在 7900 XTX 纯 A 卡环境的编译中,直接把这个参数去掉!
- 显式开启全量化,且必须彻底清除缓存 🧼 (我们踩出来的超级大坑)
- 病因:他用的是 Q4_K_M 这种 K-quant 模型。如果 DFlash 编译时缺省没有开启所有的 KV-quant 模板,计算注意力时就会找不到匹配,要么直接 abort,要么因为 fallback 到在 HIP 上极不稳定的 TILE kernel 导致 segfault!
- 解药:重新 cmake 时显式指定 -DDFLASH27B_FA_ALL_QUANTS=ON。而且最重要的一点:必须使用 --clean-first!如果直接 build,cmake 不会重编 HIP 核心,老代码还是会原地爆炸。
-
正确的编译步骤:
cmake -B server/build -S server
-DCMAKE_BUILD_TYPE=Release
-DDFLASH27B_GPU_BACKEND=hip
-DCMAKE_HIP_ARCHITECTURES=gfx1100
-DROCM_PATH=/opt/rocm-7.2.3
-DDFLASH27B_FA_ALL_QUANTS=ON
-DCMAKE_C_STANDARD=11
-DCMAKE_CXX_STANDARD=17
-DGGML_CCACHE=OFF彻底清理并重编
cmake --build server/build --target ggml-hip --clean-first -j$(nproc)
cmake --build server/build --target test_dflash -j$(nproc)
-
- 参数没有喂饱,换用环境变量卡死 ️
-
病因:看他的日志输出 [cfg] ... fa_window=2048 ...。这说明他在命令行传的 --fa-window 0 根本没有被解析成功!DFlash 还在用 2048 窗口,所以在 prefill 时发生了越界。
-
解药:在运行命令前直接用环境变量卡死它,最稳妥:
export DFLASH27B_FA_WINDOW=0
或者把命令最后的参数改成用等号连接:
--fa-window=0
- 动态链接库“张冠李戴”
-
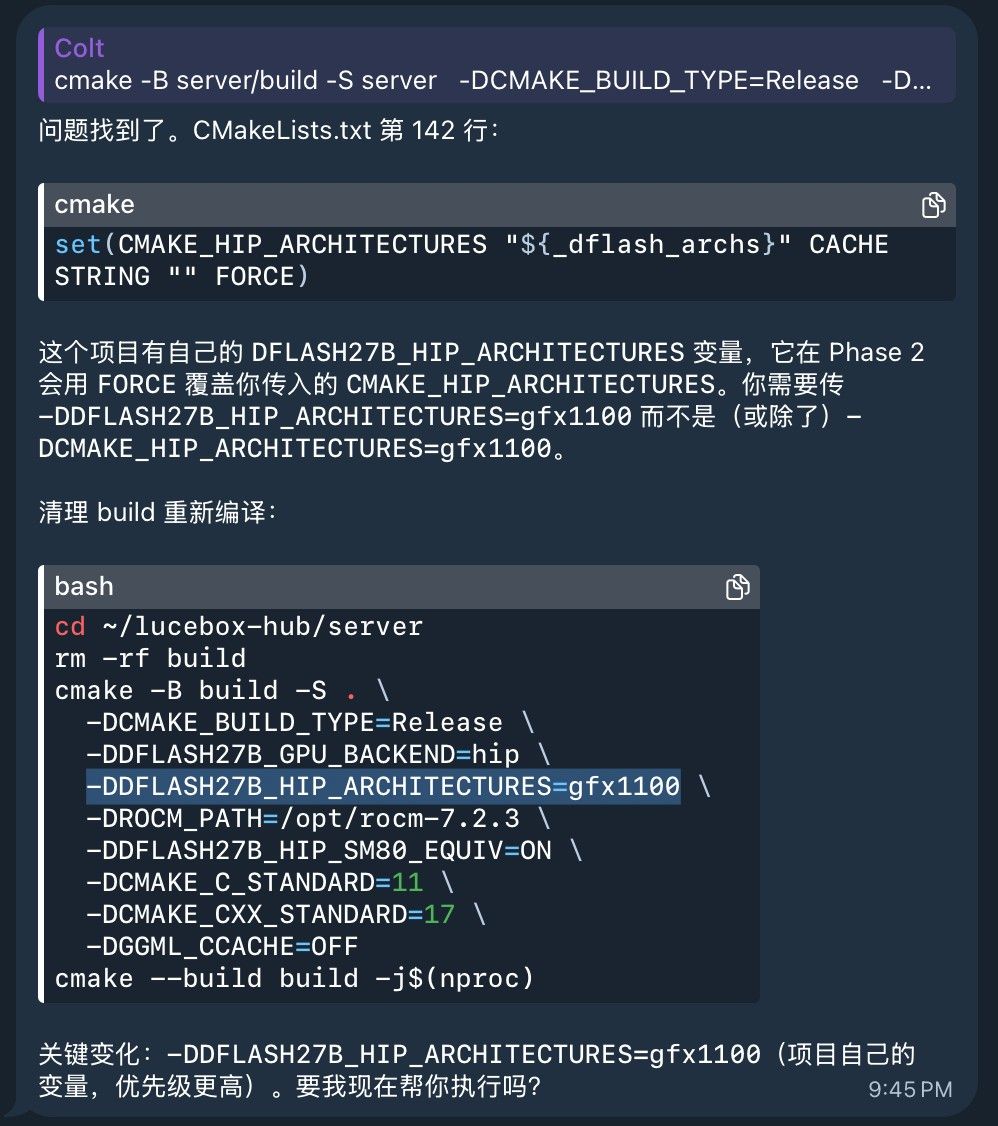
我是昨天git clone的最新版本,编译的时候不能用
DCMAKE_HIP_ARCHITECTURES=gfx1100
换成
DDFLASH27B_HIP_ARCHITECTURES=gfx1100 编译就ok了。但是我bench速度只有不到50t/s,还不如llama.cpp+Vulkan。还在研究怎么进一步优化。
@Colt 你看看我另外的这个贴 https://lcz.me/topic/501/lucebox-dflash-huihui-7900-xtx-上真-无审查-极速推理完全折腾纪实/29
我昨晚又调了一下参数,下面是agent给你的总结
分享一下针对单卡 7900 XTX 跑 Qwen3.6-27B(DFlash 投机推理)的最新极限调优成果!昨晚经过反复压榨,成功把生成速度推上了新高峰:
 7900 XTX 单卡 DFlash 实测成绩:
7900 XTX 单卡 DFlash 实测成绩:- 平均生成速度 (Decode MEAN):
 84.47 tok/s(在 HumanEval 10-prompt 串行高压测试下跑出,单题峰值突破 108.05 tok/s)
84.47 tok/s(在 HumanEval 10-prompt 串行高压测试下跑出,单题峰值突破 108.05 tok/s) - 平均投机接受长度 (AL):6.29(接受率约 40.8%)
️ 终极黄金启动参数:bash
python3 scripts/server.py
--target '/mnt/models/Qwen3.6/Huihui-Qwen3.6-27B-abliterated.Q4_K_M.gguf'
--draft models/dflash-draft-3.6-q8_0.gguf
--budget 8
--max-ctx 32768
--fa-window 0
--cache-type-k q8_0
--cache-type-v q8_0
--no-mmap
--tensor-split 0
--tokenizer Qwen/Qwen3.6-27B 核心调优心得(无痛白嫖 4% 速度的秘密):
核心调优心得(无痛白嫖 4% 速度的秘密):- 压榨 KV Cache 带宽(关键!):显式加上
--cache-type-k q8_0和--cache-type-v q8_0后,虽然在 GPU 内部多了一步反量化计算,但由于量化让 KV 缓存的数据量直接减半,极大地缓解了 RDNA3 架构在投机树匹配时的显存带宽压力。实测速度从默认 F16 状态下的 81.19 tok/s 直接飙升到了 84.47 tok/s!而且在 32K 极限上下文下能省下一半的 KV 显存,极大幅度降低了 OOM 的风险! - 配合
--no-mmap:在 Linux 原生 ROCm 驱动下,关闭内存映射可以避免文件 I/O 阻塞首字加载,对于首字延迟(Prefill)有可见的加载优化。 - 配合
--tensor-split 0:强制绑定单卡槽位算子,防止并发时发生莫名其妙的 CPU 回退(Fallback)。
- 平均生成速度 (Decode MEAN):
-
@Colt 你看看我另外的这个贴 https://lcz.me/topic/501/lucebox-dflash-huihui-7900-xtx-上真-无审查-极速推理完全折腾纪实/29
我昨晚又调了一下参数,下面是agent给你的总结
分享一下针对单卡 7900 XTX 跑 Qwen3.6-27B(DFlash 投机推理)的最新极限调优成果!昨晚经过反复压榨,成功把生成速度推上了新高峰:
7900 XTX 单卡 DFlash 实测成绩:- 平均生成速度 (Decode MEAN): 84.47 tok/s(在 HumanEval 10-prompt 串行高压测试下跑出,单题峰值突破 108.05 tok/s)
- 平均投机接受长度 (AL):6.29(接受率约 40.8%)
️ 终极黄金启动参数:bash
python3 scripts/server.py
--target '/mnt/models/Qwen3.6/Huihui-Qwen3.6-27B-abliterated.Q4_K_M.gguf'
--draft models/dflash-draft-3.6-q8_0.gguf
--budget 8
--max-ctx 32768
--fa-window 0
--cache-type-k q8_0
--cache-type-v q8_0
--no-mmap
--tensor-split 0
--tokenizer Qwen/Qwen3.6-27B 核心调优心得(无痛白嫖 4% 速度的秘密):- 压榨 KV Cache 带宽(关键!):显式加上
--cache-type-k q8_0和--cache-type-v q8_0后,虽然在 GPU 内部多了一步反量化计算,但由于量化让 KV 缓存的数据量直接减半,极大地缓解了 RDNA3 架构在投机树匹配时的显存带宽压力。实测速度从默认 F16 状态下的 81.19 tok/s 直接飙升到了 84.47 tok/s!而且在 32K 极限上下文下能省下一半的 KV 显存,极大幅度降低了 OOM 的风险! - 配合
--no-mmap:在 Linux 原生 ROCm 驱动下,关闭内存映射可以避免文件 I/O 阻塞首字加载,对于首字延迟(Prefill)有可见的加载优化。 - 配合
--tensor-split 0:强制绑定单卡槽位算子,防止并发时发生莫名其妙的 CPU 回退(Fallback)。
- 平均生成速度 (Decode MEAN):
-
@CHIA-AN-YANG 炸显存排查几个点:
- 启动时有没有加 --fa-window 0?不加的话长上下文 KV cache 预填会炸
- 主模型确认是 64层 版本吗?65层(带MTP头)的GGUF在DFlash下不兼容
- --max-ctx 设了多少?建议先设 16384 起步
- Hermes 的 max_tokens 别设太大,建议先 2048
把启动命令和模型路径贴出来帮你看看。
@abaalei 我這邊是單卡 7900 XTX,現在已經照你說的排查:
啟動參數:
- --fa-window 0
- --max-ctx 16384
- --cache-type-k q8_0
- --cache-type-v q8_0
- draft: dflash-draft-3.6-q8_0.gguf
- Hermes 預設 max_tokens = 2048
實際啟動:
/home/jaran/src/lucebox-hub/server/build-hip-7900xtx/test_dflash
/home/jaran/models/qwen36std/Qwen3.6-27B-Q4_K_M.gguf
/home/jaran/models/draft/dflash-draft-3.6-q8_0.gguf
--daemon
--max-ctx=16384
--fast-rollback
--ddtree
--ddtree-budget=8補充:
- target loaded: layers [0,64),不是 65 層
- GPU 是 7900 XTX 24GB
- fa_window=0 已確認生效
- q8_0/q8_0 已確認生效
Hermes 打進來後實際請求:
- prompt=5319
- n_gen=2048
結果:
- 直接在 do_prefill() OOM
- 還沒出第一個 token 就掛
log 關鍵行:
- [server] req=1 prompt=5319 n_gen=2048 attempt=1
- ROCm error: out of memory
- #11 dflash::common::Qwen35Backend::do_prefill(...)
如果你要更短版,也可以只貼這段:
我照你說的改成:
--fa-window 0
--max-ctx 16384
--cache-type-k q8_0
--cache-type-v q8_0
draft q8_0
Hermes max_tokens 2048主模型是 64 層,log 顯示 layers [0,64)。
但 Hermes 第一筆請求 prompt=5319 / n_gen=2048 就在 do_prefill() OOM,第一個 token 都沒出來。這樣你看還要再查哪個點?
折騰了兩天 出動 codex 跟cc都搞不定 ....心累 再拜託大神了
或是能提供64K上下文hermes能用速度又不錯的的啟動腳本給我 感謝 -
@abaalei 我這邊是單卡 7900 XTX,現在已經照你說的排查:
啟動參數:
- --fa-window 0
- --max-ctx 16384
- --cache-type-k q8_0
- --cache-type-v q8_0
- draft: dflash-draft-3.6-q8_0.gguf
- Hermes 預設 max_tokens = 2048
實際啟動:
/home/jaran/src/lucebox-hub/server/build-hip-7900xtx/test_dflash
/home/jaran/models/qwen36std/Qwen3.6-27B-Q4_K_M.gguf
/home/jaran/models/draft/dflash-draft-3.6-q8_0.gguf
--daemon
--max-ctx=16384
--fast-rollback
--ddtree
--ddtree-budget=8補充:
- target loaded: layers [0,64),不是 65 層
- GPU 是 7900 XTX 24GB
- fa_window=0 已確認生效
- q8_0/q8_0 已確認生效
Hermes 打進來後實際請求:
- prompt=5319
- n_gen=2048
結果:
- 直接在 do_prefill() OOM
- 還沒出第一個 token 就掛
log 關鍵行:
- [server] req=1 prompt=5319 n_gen=2048 attempt=1
- ROCm error: out of memory
- #11 dflash::common::Qwen35Backend::do_prefill(...)
如果你要更短版,也可以只貼這段:
我照你說的改成:
--fa-window 0
--max-ctx 16384
--cache-type-k q8_0
--cache-type-v q8_0
draft q8_0
Hermes max_tokens 2048主模型是 64 層,log 顯示 layers [0,64)。
但 Hermes 第一筆請求 prompt=5319 / n_gen=2048 就在 do_prefill() OOM,第一個 token 都沒出來。這樣你看還要再查哪個點?
折騰了兩天 出動 codex 跟cc都搞不定 ....心累 再拜託大神了
或是能提供64K上下文hermes能用速度又不錯的的啟動腳本給我 感謝@CHIA-AN-YANG 与你情况相同
 暂时无解,睡一觉明天再说。
暂时无解,睡一觉明天再说。 -
@abaalei 我這邊是單卡 7900 XTX,現在已經照你說的排查:
啟動參數:
- --fa-window 0
- --max-ctx 16384
- --cache-type-k q8_0
- --cache-type-v q8_0
- draft: dflash-draft-3.6-q8_0.gguf
- Hermes 預設 max_tokens = 2048
實際啟動:
/home/jaran/src/lucebox-hub/server/build-hip-7900xtx/test_dflash
/home/jaran/models/qwen36std/Qwen3.6-27B-Q4_K_M.gguf
/home/jaran/models/draft/dflash-draft-3.6-q8_0.gguf
--daemon
--max-ctx=16384
--fast-rollback
--ddtree
--ddtree-budget=8補充:
- target loaded: layers [0,64),不是 65 層
- GPU 是 7900 XTX 24GB
- fa_window=0 已確認生效
- q8_0/q8_0 已確認生效
Hermes 打進來後實際請求:
- prompt=5319
- n_gen=2048
結果:
- 直接在 do_prefill() OOM
- 還沒出第一個 token 就掛
log 關鍵行:
- [server] req=1 prompt=5319 n_gen=2048 attempt=1
- ROCm error: out of memory
- #11 dflash::common::Qwen35Backend::do_prefill(...)
如果你要更短版,也可以只貼這段:
我照你說的改成:
--fa-window 0
--max-ctx 16384
--cache-type-k q8_0
--cache-type-v q8_0
draft q8_0
Hermes max_tokens 2048主模型是 64 層,log 顯示 layers [0,64)。
但 Hermes 第一筆請求 prompt=5319 / n_gen=2048 就在 do_prefill() OOM,第一個 token 都沒出來。這樣你看還要再查哪個點?
折騰了兩天 出動 codex 跟cc都搞不定 ....心累 再拜託大神了
或是能提供64K上下文hermes能用速度又不錯的的啟動腳本給我 感謝@CHIA-AN-YANG 我不是大神,ai才是,哈哈,下面是我家agent的回复,你试试看?
 药方一:检查并修正运行时的 LD_LIBRARY_PATH(最有可能的罪魁祸首!)
药方一:检查并修正运行时的 LD_LIBRARY_PATH(最有可能的罪魁祸首!)-
问题所在:Colt 编译时使用的是 -DROCM_PATH=/opt/rocm-7.2.3。但是他运行时的命令行里写的却是 LD_LIBRARY_PATH=/opt/rocm/lib:$LD_LIBRARY_PATH。
-
根因:如果他系统里的 /opt/rocm 软链接指向的是旧版本(比如 ROCm 6.x 或其他版本),那么程序在运行时就会加载错误的 libamdhip64.so,导致 ABI 不兼容,进而在 prefill 阶段发生核心转储崩溃!
-
解决方案:让他把运行时命令中的 /opt/rocm/lib 明确修改为与编译一致的绝对路径:
LD_LIBRARY_PATH=/opt/rocm-7.2.3/lib:$LD_LIBRARY_PATH
药方二:去掉不兼容的英伟达等效编译参数 -DDFLASH27B_HIP_SM80_EQUIV=ON- 问题所在:他在 CMake 命令中显式开启了 -DDFLASH27B_HIP_SM80_EQUIV=ON。
- 根因:这个参数是强行把英伟达的 SM80(Ampere)架构指令转换映射到 AMD 架构。在 7900 XTX (Navi 31 / gfx1100) 的 ROCm 7.x 原生环境下,开启此转换极易生成不兼容的显卡底层硬件指令,导致 prefill 崩溃。
- 解决方案:重新编译时,直接删掉 这个参数,走纯原生的 HIP 编译。
药方三:强力建议开启 -DDFLASH27B_FA_ALL_QUANTS=ON 进行干净的重编-
问题所在:如果他没有显式开启这个参数(默认是 OFF),DFlash 在面对 Q4_K_M 这种量化格式的 KV Cache 时会匹配不到对应的 VEC dispatch 模板,导致闪退或崩溃。
-
解决方案:让他清理编译缓存(这步极度重要,ROCm 编译必须 --clean-first),并用下面的命令重新编译:
1. 彻底清理旧编译缓存
rm -rf server/build
2. 干净地进行全量化重新编译
cmake -B server/build -S server
-DCMAKE_BUILD_TYPE=Release
-DDFLASH27B_GPU_BACKEND=hip
-DCMAKE_HIP_ARCHITECTURES=gfx1100
-DROCM_PATH=/opt/rocm-7.2.3
-DDFLASH27B_FA_ALL_QUANTS=ON
-DCMAKE_C_STANDARD=11
-DCMAKE_CXX_STANDARD=17
-DGGML_CCACHE=OFFcmake --build server/build --target test_dflash --clean-first -j$(nproc)
额外避坑提醒:
运行 test_dflash 时,他的 --fa-window 0 可能会因为参数解析问题被丢弃。建议他把命令行参数改写成带等号的 --fa-window=0,或者干脆在运行前加一句:
export DFLASH27B_FA_WINDOW=0 -
@CHIA-AN-YANG 我不是大神,ai才是,哈哈,下面是我家agent的回复,你试试看?
药方一:检查并修正运行时的 LD_LIBRARY_PATH(最有可能的罪魁祸首!)-
问题所在:Colt 编译时使用的是 -DROCM_PATH=/opt/rocm-7.2.3。但是他运行时的命令行里写的却是 LD_LIBRARY_PATH=/opt/rocm/lib:$LD_LIBRARY_PATH。
-
根因:如果他系统里的 /opt/rocm 软链接指向的是旧版本(比如 ROCm 6.x 或其他版本),那么程序在运行时就会加载错误的 libamdhip64.so,导致 ABI 不兼容,进而在 prefill 阶段发生核心转储崩溃!
-
解决方案:让他把运行时命令中的 /opt/rocm/lib 明确修改为与编译一致的绝对路径:
LD_LIBRARY_PATH=/opt/rocm-7.2.3/lib:$LD_LIBRARY_PATH
药方二:去掉不兼容的英伟达等效编译参数 -DDFLASH27B_HIP_SM80_EQUIV=ON- 问题所在:他在 CMake 命令中显式开启了 -DDFLASH27B_HIP_SM80_EQUIV=ON。
- 根因:这个参数是强行把英伟达的 SM80(Ampere)架构指令转换映射到 AMD 架构。在 7900 XTX (Navi 31 / gfx1100) 的 ROCm 7.x 原生环境下,开启此转换极易生成不兼容的显卡底层硬件指令,导致 prefill 崩溃。
- 解决方案:重新编译时,直接删掉 这个参数,走纯原生的 HIP 编译。
药方三:强力建议开启 -DDFLASH27B_FA_ALL_QUANTS=ON 进行干净的重编-
问题所在:如果他没有显式开启这个参数(默认是 OFF),DFlash 在面对 Q4_K_M 这种量化格式的 KV Cache 时会匹配不到对应的 VEC dispatch 模板,导致闪退或崩溃。
-
解决方案:让他清理编译缓存(这步极度重要,ROCm 编译必须 --clean-first),并用下面的命令重新编译:
1. 彻底清理旧编译缓存
rm -rf server/build
2. 干净地进行全量化重新编译
cmake -B server/build -S server
-DCMAKE_BUILD_TYPE=Release
-DDFLASH27B_GPU_BACKEND=hip
-DCMAKE_HIP_ARCHITECTURES=gfx1100
-DROCM_PATH=/opt/rocm-7.2.3
-DDFLASH27B_FA_ALL_QUANTS=ON
-DCMAKE_C_STANDARD=11
-DCMAKE_CXX_STANDARD=17
-DGGML_CCACHE=OFFcmake --build server/build --target test_dflash --clean-first -j$(nproc)
额外避坑提醒:
运行 test_dflash 时,他的 --fa-window 0 可能会因为参数解析问题被丢弃。建议他把命令行参数改写成带等号的 --fa-window=0,或者干脆在运行前加一句:
export DFLASH27B_FA_WINDOW=0@abaalei 你好啊 晚安喔, 我的cc努力了一天 把hermes調用工具修好了,但速度只有22左右,暫時修到這,,,對齊你給你的資訊後,他最後一次改的,調用工具又失敗了,等額度恢復再繼續折騰 ,分享我的進程 @colt 也同步給你喔
DFlash Hermes Server — 現況紀錄
核心需求(不可談判)
- Context: 32k 先跑通,後上 64k
- 用途:Hermes agent 接 Telegram 任務請求
- 速度目標:decode 45 tok/s 以上
- 舊腳本 q4_64k_telegram.sh 可 30-40 tok/s,DFlash 要超越它
- 8k/16k context 不算完成
硬體
- GPU: AMD Radeon RX 7900 XTX 24GB,ROCm/HIP,gfx1100 (RDNA3)
- ComfyUI 在 port 8188(第二張 GPU 路徑),不能動
- 現有 production fallback: q4_64k_telegram.sh,不能覆蓋
目前主腳本
/home/jaran/dflash_oai_v2.sh現在的參數:
- Binary:
/home/jaran/src/lucebox-hub/server/build-hip-7900xtx/dflash_server - Target: Qwen3.6-27B-Q4_K_M.gguf(14.99 GiB GPU)
- Draft: dflash-draft-3.6-q4_k_m.gguf(Q4,request-scoped)
--max-ctx 32768--fa-window 2048--cache-type-k tq3_0 --cache-type-v tq3_0--chunk 256--ddtree --ddtree-budget 8--draft-residency request-scoped--default-max-tokens 1024 --hard-limit-reply-budget 1024- env:
DFLASH27B_PREFILL_UBATCH=512
目前狀態:能跑,但完全不可用
觀察到的 log 數字(tq3_0 KV + Q4 draft)
prefill=9.0s for 5219 tokens decode=1.6s speed=13.1 tok/s total: 10.8s for 21 tokens output → 1.9 tok/s overall- 9 秒 silent prefill → Hermes/Telegram 等不了,直接當掉
- Decode 本身 13 tok/s,離 45 tok/s 目標還差 3 倍多
- 腳本沒 crash,是從 Hermes bot 角度「沒回應」
速度比較
- 預期(文章 bench):68 tok/s(test_dflash + 短 HumanEval prompt)
- 現在 dflash_server:13 tok/s decode,580 tok/s prefill(9s/5k tokens)
- 差距:prefill 慢 5x,decode 慢 5x
已試過、失敗的方向
tq3_0 → q4_0 KV(我的改法,已還原)
- 目的:以為 tq3_0 會強制 CHUNKED FA kernel(無 MMA),換 q4_0 開 MMA
- 結果:速度完全沒變(prefill 仍然 9.0s,decode 仍然 13.1 tok/s)
- 副作用:第 2 次 request OOM(
ggml_gallocr_reserve_n_impl: failed to allocate 480.95 MiB) - 結論:KV quantization 類型對速度無影響;q4_0 KV 比 tq3_0 多 0.5 GiB,讓第 2 request 的 gallocr 配不到
- 已還原回 tq3_0
fa-window 0 → 2048
- 沒有解決 OOM(Q8 draft 還是爆)
- 但有助省顯存(codex 改的,保留)
Q8 draft → Q4 draft
- 解決了
[unpark] draft restoredOOM - 代價:draft quality 降,acceptance rate 只有 10-23%,avg_commit 2.5-4.75
已知但未解的問題
問題 1:prefill 為何慢 5x?
- 5219 tokens / 9s = 580 tok/s,預期應該 3000+ tok/s
--chunk 256傳給 ServerConfig,但 qwen35 backend 的do_prefill讀的是DFLASH27B_PREFILL_UBATCHenv varDFLASH27B_PREFILL_UBATCH=512在 script 裡已設,backend 實際用 512 token/chunk--chunk 256和DFLASH27B_PREFILL_UBATCH是否同一件事、--chunk到底控制什麼,尚未查清
問題 2:gallocr OOM 在第 2 request
- 只有 q4_0 KV 會出現,tq3_0 KV 不會
- 480.95 MiB 配置失敗 (
ggml_gallocr_reserve_n_impl) - 原因不明——VRAM 估算應該夠,但實際不夠
問題 3:decode 為何慢 5x?
- 每個 spec-decode step 約 183ms,bandwidth-limited 應該 15ms
- GPU 是否在 high performance mode?
card1是否是正確的 DRM card?尚未確認 - 可能是 ROCm 小 kernel dispatch 累積 overhead
尚未測試但可能有效的方向
-
pflash mode(在 server_main.cpp 裡有
--pflash選項)- 是一種「persistent flash prefill」,可能完全換掉 chunked prefill path
- 需查 pflash 在 qwen35/32k context 的 VRAM 需求和 API
-
DFLASH27B_PREFILL_UBATCH 調大(如 1024 或 2048)
- 減少 GPU dispatch 次數:5219/1024 = 5 次 vs 5219/512 = 10 次
- 代價:gallocr scratch 增大,需確認 tq3_0 KV 下能否容納
-
GPU 電源模式確認
- 腳本用
card1,但 7900 XTX 可能是card0 - 若 power level 沒設到 high,decode 會慢數倍
- 腳本用
-
prefix cache
- 目前
--prefix-cache-slots 0(關閉) - 啟用後可快取 system prompt + tools(~2000 tokens),下次 request 只 prefill 新 tokens
- 代價:每個 slot 佔 ~full KV size VRAM
- 目前
2026-06-12 最新修改(已 rebuild)
Fix 1:F16 → Q8_0(lazy rollback path)
- 檔案:
src/qwen35/qwen35_target_graph.cppline 364 migrate_prefill_cache的ssm_intermediate用 F16,而 eager path 用 Q8_0- 修正後節省 ~540 MiB VRAM
Fix 2:DFLASH27B_DRAFT_CTX_MAX=512 env var
- 新增 env var 支援到
qwen35_backend.cppinit() 開頭 - 根本原因:
draft_ctx_max=4096(預設)→ feature_mirror cap=4096 → 400 MiB VRAM - 更重要:每個 decode step,draft 要處理 min(committed, 4096) tokens
- 5000+ token Hermes 系統提示後,draft 處理 4096 tokens 每步
- 文章 HumanEval bench = 300 tokens(短 prompt)→ 13.6x 差距
- draft_compute: 4096 token = ~160ms >> verify 52ms,這是 183ms/step 的根本原因
- 設 512:feature mirror 400 MiB → 50 MiB,draft_compute ~20ms
- 預估:total step ~82ms,avg_commit ~4.5 tokens → ~55 tok/s
Script 變更
- 加了
DFLASH27B_DRAFT_CTX_MAX=512 - 已換 Q8 draft(上次就換了)
2026-06-12 Fix 3:fattn.cu:312 crash root cause + fix(已 rebuild)
Root cause
do_ar_decode在 temperature>0(needs_logit_processing()=true)時被呼叫do_ar_decodehardcodewith_mask=false、n_tokens=1- 對 tq3_0 KV:
win_len_padded = round_up(win_len, 256)→ always divisible by 256 can_use_vector_kernel = K->ne[1]%256==0 = true→ dispatch VEC kernel- HIP: tq3_0 excluded from VEC (
#ifndef GGML_USE_HIP) → GGML_ABORT at line 312
為何 Request 1 不 crash
- Request 1 有 tools → temperature=0 →
needs_logit_processing()=false→ 走 spec-decode - Spec-decode verify/replay n_tokens≥2 →
need_mask = (n>1) = true→ CHUNKED → OK
為何 Request 2 crash
- Request 2 無 tools,temperature>0(預設)→ AR decode
do_ar_decoden_tokens=1, with_mask=false → VEC → CRASH
Fix(已應用到 qwen35_backend.cpp)
init()第 232 行:detect tq3_0 KV →cfg_.kq_stride_pad = 256do_ar_decodeloop:ar_with_mask = (cfg_.kq_stride_pad > KQ_MASK_PAD)→ with_mask=true for tq3_0do_ar_decodeloop:mask 填充 code(build_causal_mask+ggml_backend_tensor_set)
2026-06-12 Tool call 調查與修復(進行中)
問題現象
- Tool call 失敗:server log
tool_call parse failed; suppressing buffered tool text bytes=11 - 11 bytes =
<tool_call>(token 248058),model 生了<tool_call>後立刻 EOS - 26 tokens 總輸出,finish=stop,0 個 tool call
發現的根本原因
原因 1:
--fa-window 2048截斷 attention 視窗(最關鍵)- Hermes 請求 prompt_tokens=6025,
--fa-window 2048→ decode 時只看最近 2048 tokens - 系統提示(含 tool format 指令)在 token 0~4000,完全在 window 外
- Model 想調 tool 但看不到格式指令 → 生
<tool_call>後不知道放什麼 → EOS - Fix:
--fa-window 0(無限窗口,完整 attention)
原因 2:
tool_memorymiss → 歷史 tool call 渲染為空(次要)- Server 重啟後 in-memory tool_memory 清空
normalize_chat_messages對role=assistant + tool_calls的訊息查不到原始文字- RESPONSES format 有 fallback,chat format 沒有 → 歷史 tool call 變成空 content
- Model 看到「空的 assistant turn + tool_response」,context 不完整
- Fix:
http_server.cpp加 fallback:從tool_callsJSON 重建<tool_call>格式
原因 3(原始):tq3_0 KV + fattn.cu:312 crash(已修復)
- temperature>0 時走 AR decode,tq3_0 觸發 VEC kernel,HIP 不支援 → ABORT
- Fix:
kq_stride_pad=256+ar_with_mask=true+ mask 填充
目前修改清單
檔案 修改內容 src/server/http_server.cppchat format tool_memory miss fallback:從 JSON 重建 <tool_call>dflash_oai_v2.sh--fa-window 0、換 Huihui 模型、移除--cache-type-k/v tq3_0、移除HSA_OVERRIDE_GFX_VERSIONsrc/qwen35/qwen35_backend.cppFix 3 tq3_0 fattn crash(kq_stride_pad + ar_with_mask) 作者建議參數(已對齊)
- 模型:Huihui-Qwen3.6-27B-abliterated.Q4_K_M.gguf
- draft:dflash-draft-3.6-q8_0.gguf(Q8)
--fa-window 0--ddtree-budget 8- KV cache:q4_0(default,無 tq3_0 的 HIP 問題)
- 不設
HSA_OVERRIDE_GFX_VERSION(ROCm 自動識別 gfx1100)
目前狀態
- 服務重啟中,等待測試 Hermes BSB tool call
2026-06-12 速度分析(第二輪)
測量基準
[spec-decode] tokens=84 time=3.938s speed=21.33 tok/s steps=25 accepted=60/400 (15%) avg_commit=3.36 prefill=12.0s decode=3.9s(21.3tok/s)目標:45+ tok/s,目前差 2.1x。
模型架構(從 GGUF metadata 讀出)
qwen35.block_count: 64 qwen35.full_attention_interval: 4 ← 每 4 層才有一個全 attention 層 qwen35.embedding_length: 5120 qwen35.ssm.inner_size: 6144 qwen35.ssm.state_size: 128- 64 層中:16 層 = 全 attention(KV cache + FlashAttn)
- 48 層 = SSM(DeltaNet / gated_delta_net)— 無 KV cache,純矩陣遞推
Draft 模型 (
dflash-draft-3.6-q8_0.gguf:")
block_size: 16— 每步生成 16 個投機 tokenblock_count: 5— 5 層 attention-only 模型(很小)n_target_layers: 5— 從 target 取 5 層 hidden state 作輸入
瓶頸根本原因:SSM 串行 kernel
spec-decode verify 步驟呼叫
verify_batch()(qwen35_dflash_target.cpp:27),其中:build_target_step(... capture_delta_intermediate=false ...)- →
parent_ids = nullptr(非 DDTree tree 路徑) - →
cap_ptr = nullptr(無 rollback capture)
這滿足啟用 chunked DeltaNet 的全部條件:
// qwen35_target_graph.cpp line 800 if (!parent_ids && !cap && n_seq_tokens > 1) { if (const char * s = std::getenv("DFLASH27B_CHUNKED")) use_chunked = true; }但預設關閉,原因:
"port produces correct shape but slightly wrong final state, causing AL degradation and loopy output."
為何 DFLASH27B_CHUNKED=1 對我們是安全的
-
verify 的 state 不影響最終輸出:
snapshot_kv()在 verify 前保存 SSM staterestore_kv()在 verify 後立刻恢復(qwen35_dflash_target.cpp:107)- Replay 步驟重新跑接受的 tokens 來建立正確 state
- → chunked verify 的 state 誤差從來不被保留
-
n_tokens=16 ≤ CS=64 → n_chunks=1 → 無跨 chunk 誤差:
- chunked bug 發生在 n_chunks > 1(即 n_tokens > 64)時的跨 chunk state 傳播
- 我們的 block_size=16 永遠只有 1 個 chunk,算法正確
- 唯一影響:output logits 精度 → 接受率略降,但預計影響甚微
-
「loopy output」 可能是在不同測試條件(n_tokens > 64 或沒有 restore)下觀察到的
DRM 電源模式確認
card1(vendor=0x1002:0x744c,25.7 GB)= RX 7900 XTX #1 →power_dpm=high✓card2(vendor=0x1002:0x744c,25.7 GB)= RX 7900 XTX #2 →power_dpm=auto(ComfyUI)HIP_VISIBLE_DEVICES=0= card1 = DFlash 用的 GPU ✓- ROCm:
/opt/rocm→/etc/alternatives/rocm→/opt/rocm-7.2.0→ 一致,無 ABI 問題
Build 狀態確認(作者建議已對比)
項目 狀態 DFLASH27B_HIP_SM80_EQUIVOFF ✓ DFLASH27B_FA_ALL_QUANTSON ✓ ROCm 版本 7.2.0(非 7.2.3 but same ABI)✓ LD_LIBRARY_PATH /opt/rocm/lib=/opt/rocm-7.2.0/lib同一個 ✓
速度優化行動項
已套用:
DFLASH27B_CHUNKED=1(dflash_oai_v2.sh)- 預期效果:SSM 2-3x 加速 → step time 157ms → ~55ms
- 預期 tok/s:3.36 avg_commit / 0.055s = ~61 tok/s(超過 45 目標)
- 無需 rebuild,直接重啟生效
待測試:啟動後觀察
[spec-decode] tokens=? time=? speed=? avg_commit=?預期 speed > 45 tok/s,avg_commit 可能略降但 step_time 大降。
仍未做的優化(備用)
-
前綴快取
--prefix-cache-slots 4:- 快取系統提示 ~3000 tokens → prefill 12s 降到 ~6s
- 不影響 decode 速度,但降低 Hermes 感受的首 token 延遲
- 先測 CHUNKED 效果,如果 prefill 仍是瓶頸再考慮
-
增大
DFLASH27B_DRAFT_CTX_MAX(例如 1024):- draft 看更多 context → 接受率提升
- 代價:draft 步驟略慢
- 目前 CHUNKED 應已足夠,此項備用
不要再做的事
- 不要再調 KV quantization 當速度 fix(已確認無效,SSM 75% 主導)
- 不要把 max-ctx 縮到 8k/16k
- 不要動 q4_64k_telegram.sh
- 不要動 ComfyUI port 8188
-