
自研工作流,最新进展
-
看了下发帖,我已经五天没来了. 论坛多了些新朋友,挺开心的. 说明老特的人缘挺高的.
这几天基本都是每天工作20个小时,日token消耗在3亿以上. 写下工作心得,也给论坛的朋友一些经验.之前发过工作流贴子:
https://lcz.me/topic/360/爆肝十天-每天睡三个小时-手搓一个工作流这次 我把 工作流 基本打通了. 现在已经支持 下面这三种工作流模式:
- 串行流(Sequential / 线性流)
- 并行流(Parallel)
Fan-out(扇出):单个父节点拆分出多个并行子任务;
Fan-in(扇入):所有并行子任务执行完毕后,结果统一汇总到下一个节点。 - 条件判断类(if else)
不管你怎么折腾工作流,就这三种模式. 要么就是这三种模式的混合.
我最常用的,就是串行,已经能解决80%的需求了.
我不推荐第三种,原因是如果工作流跑歪了,浪费token. 现在token涨价太多了.每个工作流,完成节点,一定要人工检查,千万不要盲目轻信顶级模型的能力.
其实这就像瞎子算命一样,大家玩的都是概率. 大模型就是瞎子算命.我现在的工作,就是 优化提示词,写skill,让流程跑的更顺畅,尤其在专业领域,肯定比通用模型自己回答更强. 这个工作流没打算开源,主要是没想好,开源这种工具 的意义是什么?
如果证明自己多厉害,那无所谓了,现实中我就是程序员中前1%. 如果借助AI工具,我的生产效率能达到1:10,通俗点说,我大概能达到10个五年工作经验的程序员的生产效率.
我发现一个道理,大家天天喊着claude opus 4.7或4.6 强,都是些小白.其实还是本质上 claude code,内置了提示词的优化和harness工程,尤其是在coding领域,这点我是同意老特说的. 这种吹牛,持续不了太长时间,如果价格太高.一般来说半年,最多一年,等国内这些厂商发力了,价格成白菜价.
claude code价格高,那是因为没有替代产品,如果出现替代产品,价格低,他扛不住多长时间.
其实LLM大模型就是瞎子算命,靠猜, 大家的基础都差不多. 只是那个领域训练的方向不一样罢了.
还有个建议,我建议小白,别上来花大价钱买独立显卡,自己先用在线模型api,花几百块钱,试试自己是不是那块料,因为本地开源模型,如果对比在线模型的话,属于宝宝级别.你投入几万块钱,你啥时候能回本?
我问大家一个常识问题: 在线模型和开源模型, 为什么开源模型要开源?资本家开源模型,他是做公益吗?你想多了.
好模型拿来卖钱不好吗?有商业价值,企业能付钱,个人一般都是白嫖.这些云厂商,硬件都是现成的,好模型+老黄显卡,开个在线API,卖token,这就是印钞机啊.
为啥要模型开源? 无非是让意向客户,展示自己的技术能力罢了,你还真以为开源模型,这东西多强.当然你也分场景,如果对话类,那够用,但是企业级,这个不太够.能投大价钱,都是专业领域, 比如coding,音视频领域,自己如果只是问答,花几万买显卡,我觉得没必要.
而且老黄,最近更新显卡速度也快,基本不愁销售,天天搞什么各种秀?串行工作流:
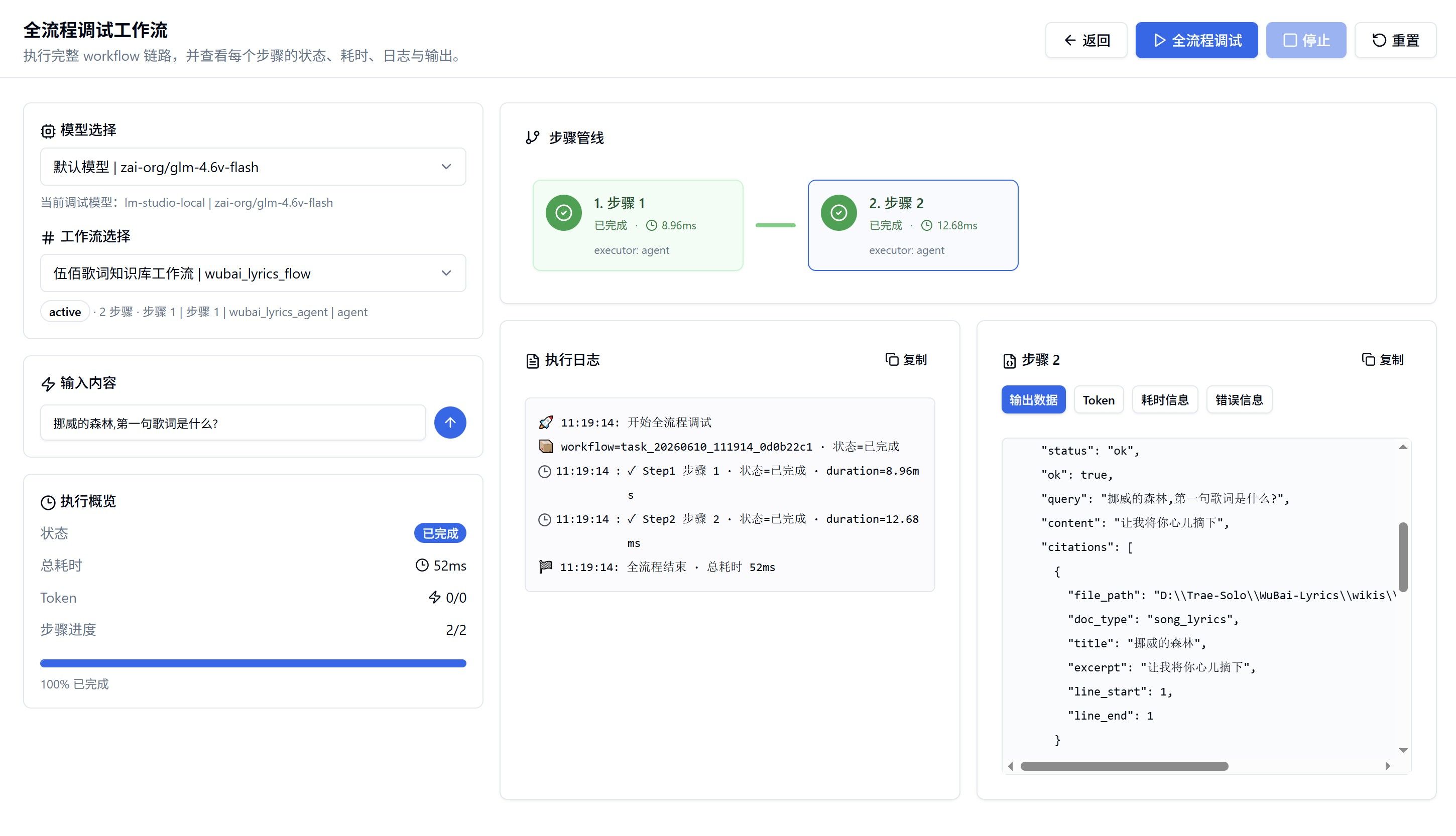
并行工作流:
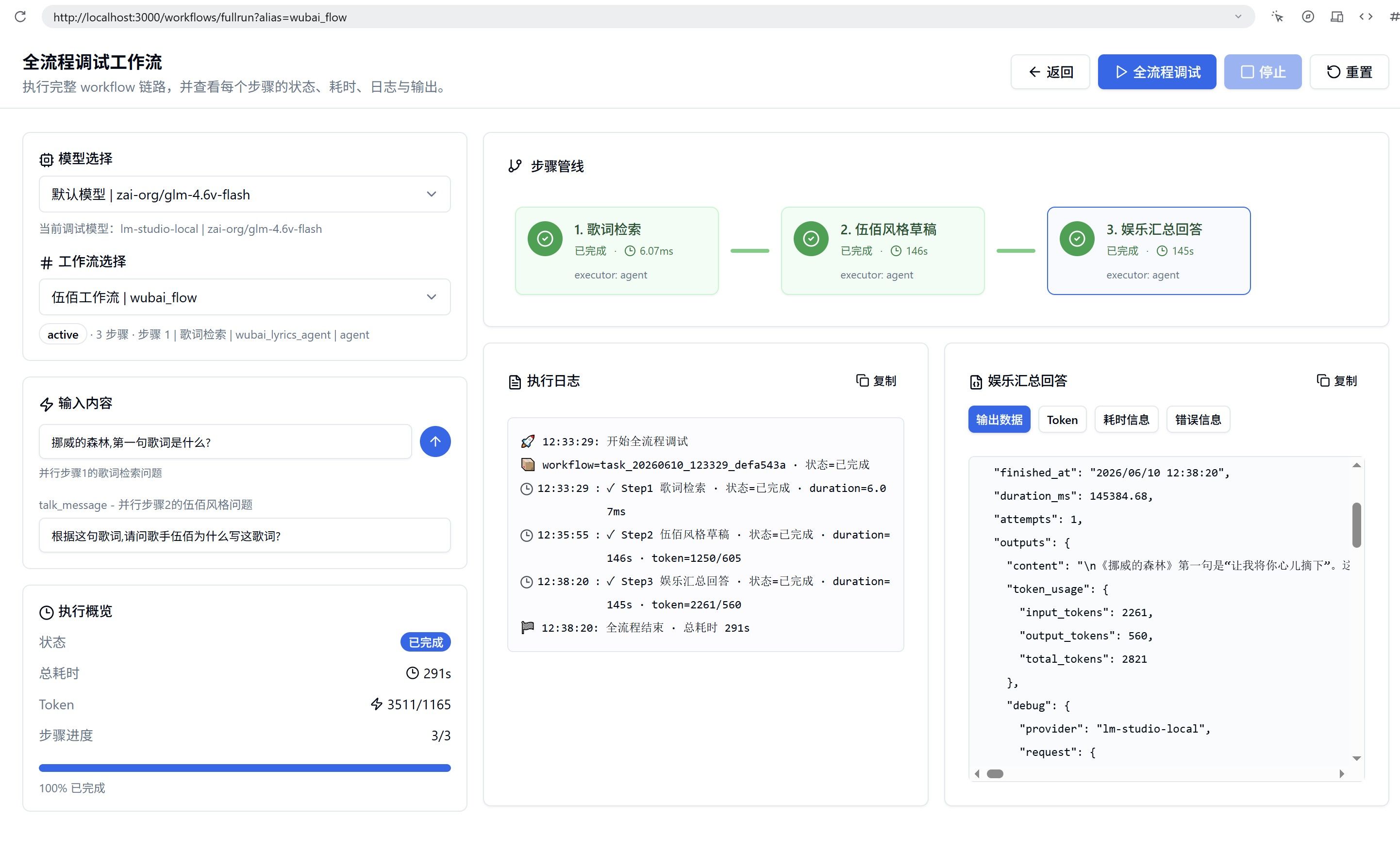
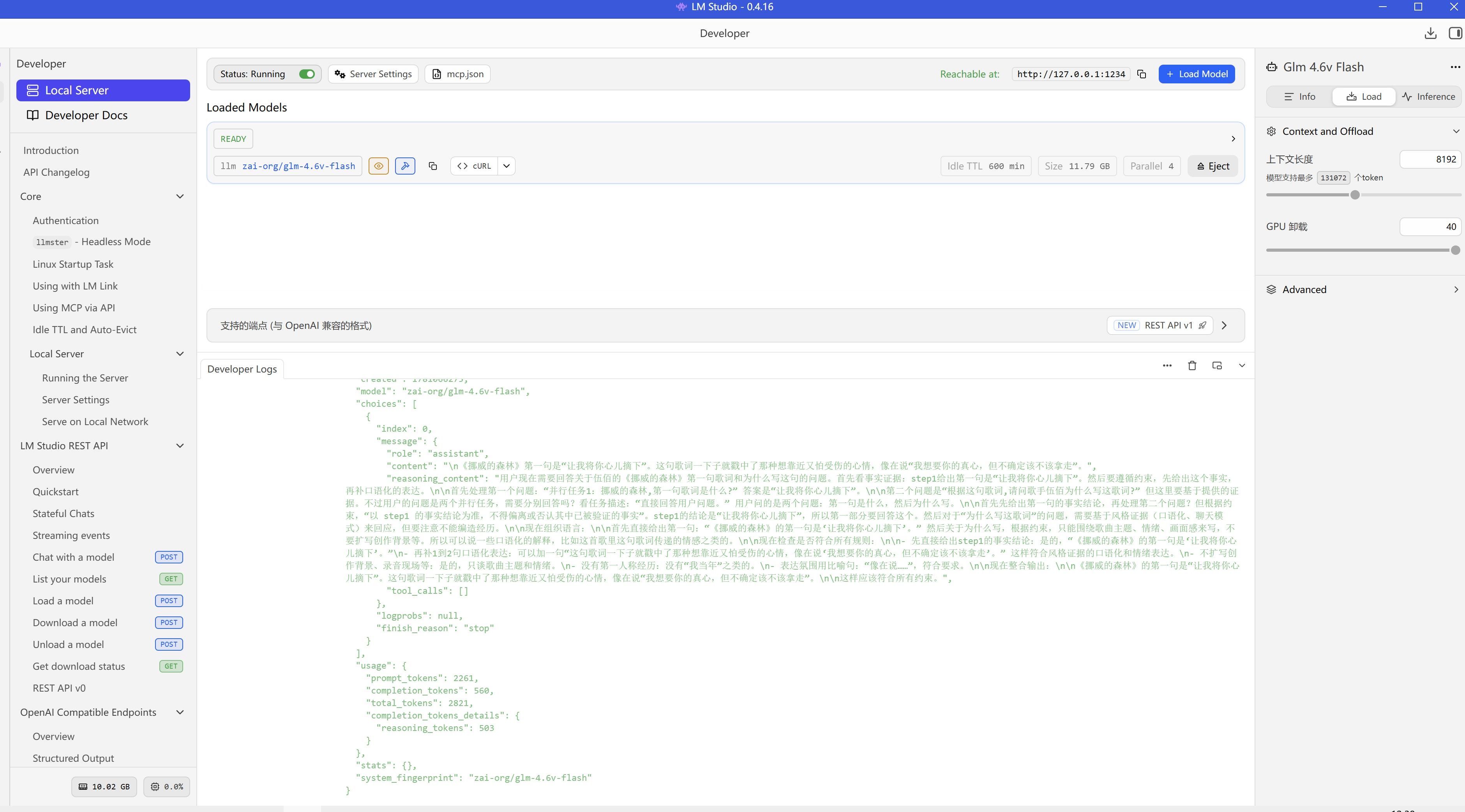
lm studio 的截图(只是本地测试,如果更强的API模型效果更好):
-
 T terry 固定了该主题
T terry 固定了该主题
-
顶。确实如此。我在 API 价格可以接受的情况 也是一直没用本地模型工作。上了一块7900 也娱乐属性。
此帖看破了 AI这个大局。我们都是局中人。站好自己的位置就行。
能拥抱最好,毕竟这是风口。
不拥抱其实也无伤大雅。现实中大家不用AI不也照常日出日落。 -
-
系统 取消固定了该主题
-
随着AI能力的暴增。显卡的价格也会越涨越疯。还能涨涨。我坐等 7900XTX爆火。卖了回血。
-
看了下发帖,我已经五天没来了. 论坛多了些新朋友,挺开心的. 说明老特的人缘挺高的.
这几天基本都是每天工作20个小时,日token消耗在3亿以上. 写下工作心得,也给论坛的朋友一些经验.之前发过工作流贴子:
https://lcz.me/topic/360/爆肝十天-每天睡三个小时-手搓一个工作流这次 我把 工作流 基本打通了. 现在已经支持 下面这三种工作流模式:
- 串行流(Sequential / 线性流)
- 并行流(Parallel)
Fan-out(扇出):单个父节点拆分出多个并行子任务;
Fan-in(扇入):所有并行子任务执行完毕后,结果统一汇总到下一个节点。 - 条件判断类(if else)
不管你怎么折腾工作流,就这三种模式. 要么就是这三种模式的混合.
我最常用的,就是串行,已经能解决80%的需求了.
我不推荐第三种,原因是如果工作流跑歪了,浪费token. 现在token涨价太多了.每个工作流,完成节点,一定要人工检查,千万不要盲目轻信顶级模型的能力.
其实这就像瞎子算命一样,大家玩的都是概率. 大模型就是瞎子算命.我现在的工作,就是 优化提示词,写skill,让流程跑的更顺畅,尤其在专业领域,肯定比通用模型自己回答更强. 这个工作流没打算开源,主要是没想好,开源这种工具 的意义是什么?
如果证明自己多厉害,那无所谓了,现实中我就是程序员中前1%. 如果借助AI工具,我的生产效率能达到1:10,通俗点说,我大概能达到10个五年工作经验的程序员的生产效率.
我发现一个道理,大家天天喊着claude opus 4.7或4.6 强,都是些小白.其实还是本质上 claude code,内置了提示词的优化和harness工程,尤其是在coding领域,这点我是同意老特说的. 这种吹牛,持续不了太长时间,如果价格太高.一般来说半年,最多一年,等国内这些厂商发力了,价格成白菜价.
claude code价格高,那是因为没有替代产品,如果出现替代产品,价格低,他扛不住多长时间.
其实LLM大模型就是瞎子算命,靠猜, 大家的基础都差不多. 只是那个领域训练的方向不一样罢了.
还有个建议,我建议小白,别上来花大价钱买独立显卡,自己先用在线模型api,花几百块钱,试试自己是不是那块料,因为本地开源模型,如果对比在线模型的话,属于宝宝级别.你投入几万块钱,你啥时候能回本?
我问大家一个常识问题: 在线模型和开源模型, 为什么开源模型要开源?资本家开源模型,他是做公益吗?你想多了.
好模型拿来卖钱不好吗?有商业价值,企业能付钱,个人一般都是白嫖.这些云厂商,硬件都是现成的,好模型+老黄显卡,开个在线API,卖token,这就是印钞机啊.
为啥要模型开源? 无非是让意向客户,展示自己的技术能力罢了,你还真以为开源模型,这东西多强.当然你也分场景,如果对话类,那够用,但是企业级,这个不太够.能投大价钱,都是专业领域, 比如coding,音视频领域,自己如果只是问答,花几万买显卡,我觉得没必要.
而且老黄,最近更新显卡速度也快,基本不愁销售,天天搞什么各种秀?串行工作流:
并行工作流:
lm studio 的截图(只是本地测试,如果更强的API模型效果更好):
-
我如果早2个星期看了你的贴子就好了。普通小白确实没有必要搞本地大模型。我脑子一热,投了6万,搞了太电脑,现在折腾好了,不知道跑什么,用他干什么?完全没有头绪。电脑天天还是看老特视频,其他啥都没有,完全浪费。真该先用在线api玩玩,玩清楚了,再去买电脑。
@zhu-wenzheng 配置好了做油管啊!

