RTX PRO 5000的qwen3.6-27B性能优化
-
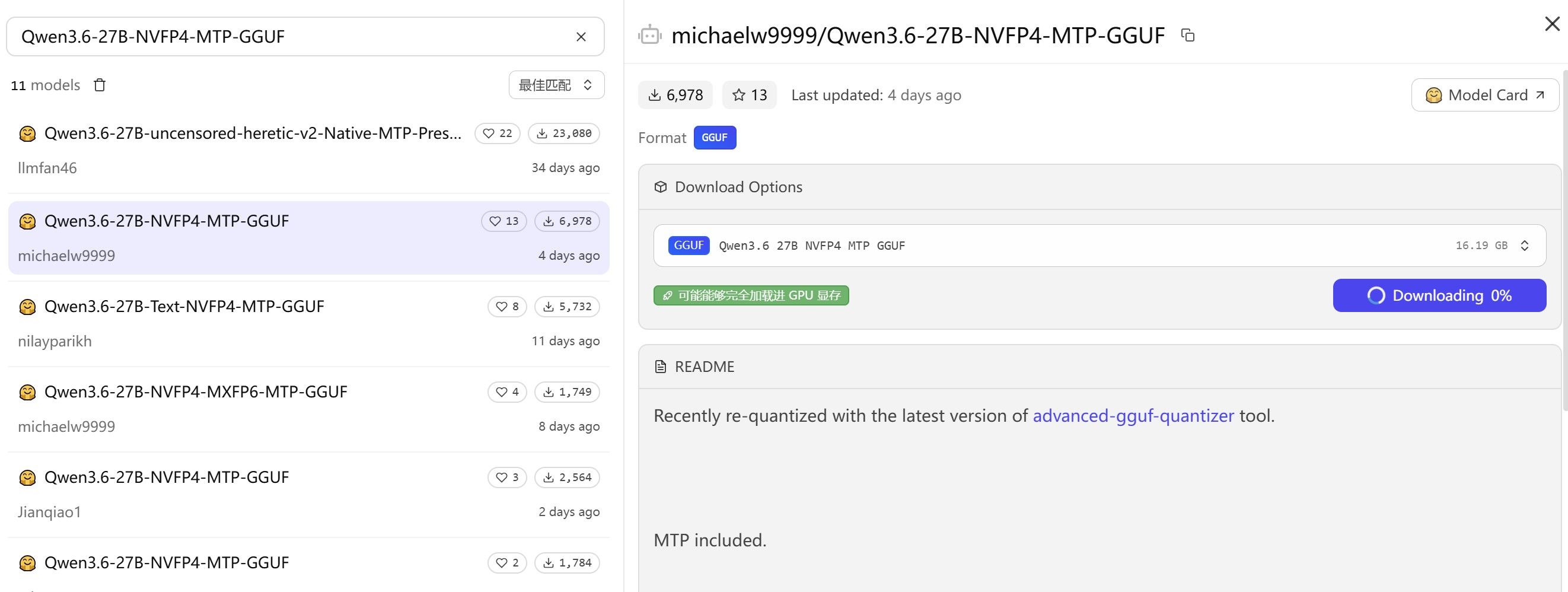
基于上帖:RTX PRO 5000碎碎念@566656661 老哥的鞭策,基本上遍历了市面上所有比较火的qwen3.6-27B模型。最终找到了一个相对性价比最高的版本:Qwen3.6-27B-NVFP4-MTP-GGUF
驱动版本:
596.59
CUDA 13.0
优势:
多模态,nvfp4,llama-cpp,MTP支持,MTP-nvfp4量化(目前唯一)
劣势:
不是非拒绝模型
启动参数如下:
~/projects/llama.cpp/build/bin/llama-server \ -m ~/.local/models/Qwen3.6-27B-NVFP4-MTP-GGUF.gguf \ --mmproj ~/.local/models/Qwen3.6-27B-mmproj-BF16.gguf \ -ngl 99 \ --flash-attn on \ --cache-type-k q8_0 \ --cache-type-v q8_0 \ -c 262144 \ --port 8081 \ --host 0.0.0.0 \ --temp 0.6 \ --top-p 0.95 \ --top-k 40 \ --repeat-penalty 1.05 \ --repeat-last-n 512 \ --spec-type draft-mtp \ --spec-draft-n-max 2最终实战结果:
在Hermes Agent中实战调用,上下文总长256K,已占用100K的前提下,跑出了prefill:1400t/s decode:60t/s 的成绩,至少在hermes调用上,LLM的逻辑推理已经不成瓶颈。且在我自用的两天中,并没有出现无限循环的情况。推荐给大家。
-
跑起来速度和在线的相比如何,我4090跑不了NVFP4,INT4量化智力足够了,速度我感觉也就那样,跑任务我觉得也不比xtx强多少,上下文你长一点,意义不大。超过128基本没啥意义。多来点实际体验。对了,多谈谈Turboquant,MTP,Dflash这些,MTP,DFlash对比等等。我还是Q8 KV,这几天AMD的卡我就偶尔玩玩,N卡已经把VLLM的环境都给卸载了,以后就Llama.cpp,不折腾了,甚至N卡以后都不碰大模型了。专职ComfyUI。
-
基于上帖:RTX PRO 5000碎碎念@566656661 老哥的鞭策,基本上遍历了市面上所有比较火的qwen3.6-27B模型。最终找到了一个相对性价比最高的版本:Qwen3.6-27B-NVFP4-MTP-GGUF
驱动版本:
596.59
CUDA 13.0
优势:
多模态,nvfp4,llama-cpp,MTP支持,MTP-nvfp4量化(目前唯一)
劣势:
不是非拒绝模型
启动参数如下:
~/projects/llama.cpp/build/bin/llama-server \ -m ~/.local/models/Qwen3.6-27B-NVFP4-MTP-GGUF.gguf \ --mmproj ~/.local/models/Qwen3.6-27B-mmproj-BF16.gguf \ -ngl 99 \ --flash-attn on \ --cache-type-k q8_0 \ --cache-type-v q8_0 \ -c 262144 \ --port 8081 \ --host 0.0.0.0 \ --temp 0.6 \ --top-p 0.95 \ --top-k 40 \ --repeat-penalty 1.05 \ --repeat-last-n 512 \ --spec-type draft-mtp \ --spec-draft-n-max 2最终实战结果:
在Hermes Agent中实战调用,上下文总长256K,已占用100K的前提下,跑出了prefill:1400t/s decode:60t/s 的成绩,至少在hermes调用上,LLM的逻辑推理已经不成瓶颈。且在我自用的两天中,并没有出现无限循环的情况。推荐给大家。
最终实战结果:
在Hermes Agent中实战调用,上下文总长256K,已占用100K的前提下,跑出了prefill:1400t/s decode:60t/s 的成绩,至少在hermes调用上,LLM的逻辑推理已经不成瓶颈。且在我自用的两天中,并没有出现无限循环的情况。这个结果我觉得不错了, 假设thinking 2048
TTFT = 100000/1400 = 71.4s
thinking = 2048/60 = 34.1s
有效首字 = 71.4 + 34.1 = 105.5s100K上下文, 深度思考的情况下, 有效首字能到 105秒, 我觉得还算不错了. decode 60肯定足够用了.
-
跑起来速度和在线的相比如何,我4090跑不了NVFP4,INT4量化智力足够了,速度我感觉也就那样,跑任务我觉得也不比xtx强多少,上下文你长一点,意义不大。超过128基本没啥意义。多来点实际体验。对了,多谈谈Turboquant,MTP,Dflash这些,MTP,DFlash对比等等。我还是Q8 KV,这几天AMD的卡我就偶尔玩玩,N卡已经把VLLM的环境都给卸载了,以后就Llama.cpp,不折腾了,甚至N卡以后都不碰大模型了。专职ComfyUI。
-
跑起来速度和在线的相比如何,我4090跑不了NVFP4,INT4量化智力足够了,速度我感觉也就那样,跑任务我觉得也不比xtx强多少,上下文你长一点,意义不大。超过128基本没啥意义。多来点实际体验。对了,多谈谈Turboquant,MTP,Dflash这些,MTP,DFlash对比等等。我还是Q8 KV,这几天AMD的卡我就偶尔玩玩,N卡已经把VLLM的环境都给卸载了,以后就Llama.cpp,不折腾了,甚至N卡以后都不碰大模型了。专职ComfyUI。
-
总体上来讲,前100k上下文的速度体验和deepseek-v4没有太本质的区别。但是上了100k之后就会拉开了。
当然,这里有个llama.cpp的对话缓存被高频舍弃的问题,最严重的时候每次调用LLM都会舍弃缓存重新prefill这个对话。
这在150K+上下文的时候就相当灾难了。每跑一步都罚站20秒~1分钟。这个我看是llama.cpp对于27B这个模型的已知问题(对应的issues),明天我更新llama.cpp的版本再试试看。
-
 K kop wang 于 引用了 此主题
K kop wang 于 引用了 此主题