
作为一个ai新手,想尝鲜尝试和学习,打算入一张V100 16G的,但是为啥论坛里完全不聊这张卡?真的是没有生产力?还是性价比太低?
-
我觉得一个工具还是看他用在哪里,怎么用。直接武断地说某一个卡是垃圾了的话,有点儿过于偏执。如果只是本地跑agent的基础对话,帮助基础系统维护,或者再最多就是生个图,解决一下一些自动化生产力的问题的话,应该还是问题不大的吧。毕竟有的事情是不愿意放到api上面去调用的,local LLM还是有一些价值的。主要看使用方向和侧重了!
不知道大家对于本地部署大模型,还有什么建议?以及应用上的实践呢?
-
我觉得一个工具还是看他用在哪里,怎么用。直接武断地说某一个卡是垃圾了的话,有点儿过于偏执。如果只是本地跑agent的基础对话,帮助基础系统维护,或者再最多就是生个图,解决一下一些自动化生产力的问题的话,应该还是问题不大的吧。毕竟有的事情是不愿意放到api上面去调用的,local LLM还是有一些价值的。主要看使用方向和侧重了!
不知道大家对于本地部署大模型,还有什么建议?以及应用上的实践呢?
@hotpigwk
咸鱼上二手V100 16G的成品卡(转接好PCIE直插)就1100左右价格,直接买一张上来测试跑大模型,或者你要跑27B的就买2张,总价2200,自己折腾然后把实测数据截图发论坛里,就有话题有人聊了
-
建議買兩張, 32G 夠跑很多語言模型了
-
做RAG嵌入的话,比16GV100更香的卡还有么?
-
贴主抱歉了,泡了一下论坛,发现v100 跑大模型还真可能,附上27b模型链接,https://huggingface.co/sokann/Qwen3.6-27B-GGUF-4.262bpw, 不过它要用ik_llama.cpp加载,要自己编译, 好处是集成了turboQuant, KV可以翻倍。 论坛有人在V100 16G 上测试, 可以跑起来,上下文可以开到100K,大概在28tokens/s。关键参数 -c 102400 -np 1 -fa on -ngl 99 -ctk q4_0 -khad -ctv q4_0 -vhad -wgt 1
-
贴主抱歉了,泡了一下论坛,发现v100 跑大模型还真可能,附上27b模型链接,https://huggingface.co/sokann/Qwen3.6-27B-GGUF-4.262bpw, 不过它要用ik_llama.cpp加载,要自己编译, 好处是集成了turboQuant, KV可以翻倍。 论坛有人在V100 16G 上测试, 可以跑起来,上下文可以开到100K,大概在28tokens/s。关键参数 -c 102400 -np 1 -fa on -ngl 99 -ctk q4_0 -khad -ctv q4_0 -vhad -wgt 1
-
@terry 我手上没这个卡,下午抽了点时间。用5060ti试了一下,同样是16g显存,应该有参考意义,之前用官网的llama.cpp跑qwen3.6-27b q4,最多开20k就不行了,下午试了一下这个ik_llama.cpp跑了一下。100k是跑不了,不过试了开50k上下文驱动hermes没有问题!速度25t/s。因为开着向日葵远程测试的,把向日葵关了估计能上到60k,用着算是不错!我发一下参数-c 51200
-np 1
-fa on
-ngl 99
-ctk q4_0
-khad
-ctv q4_0
-vhad
--host 0.0.0.0
--port 8000
--cont-batching
--jinja
--mlock
--threads 10
--threads-batch 12
附下载地址:https://github.com/Thireus/ik_llama.cpp/releases/tag/main-b4744-8d7891f
且行且珍惜 -
@terry 我手上没这个卡,下午抽了点时间。用5060ti试了一下,同样是16g显存,应该有参考意义,之前用官网的llama.cpp跑qwen3.6-27b q4,最多开20k就不行了,下午试了一下这个ik_llama.cpp跑了一下。100k是跑不了,不过试了开50k上下文驱动hermes没有问题!速度25t/s。因为开着向日葵远程测试的,把向日葵关了估计能上到60k,用着算是不错!我发一下参数-c 51200
-np 1
-fa on
-ngl 99
-ctk q4_0
-khad
-ctv q4_0
-vhad
--host 0.0.0.0
--port 8000
--cont-batching
--jinja
--mlock
--threads 10
--threads-batch 12
附下载地址:https://github.com/Thireus/ik_llama.cpp/releases/tag/main-b4744-8d7891f
且行且珍惜 -

3个速度都差不多,25t/S,建议用 k q8 ,v q4,这样压缩质量和空间都比较好。集成了turboQuant的ik_llama.cpp确实可以大幅提升上下文压缩空间。N卡,A卡都有效果。以后16g卡跑27b模型会越来越好用
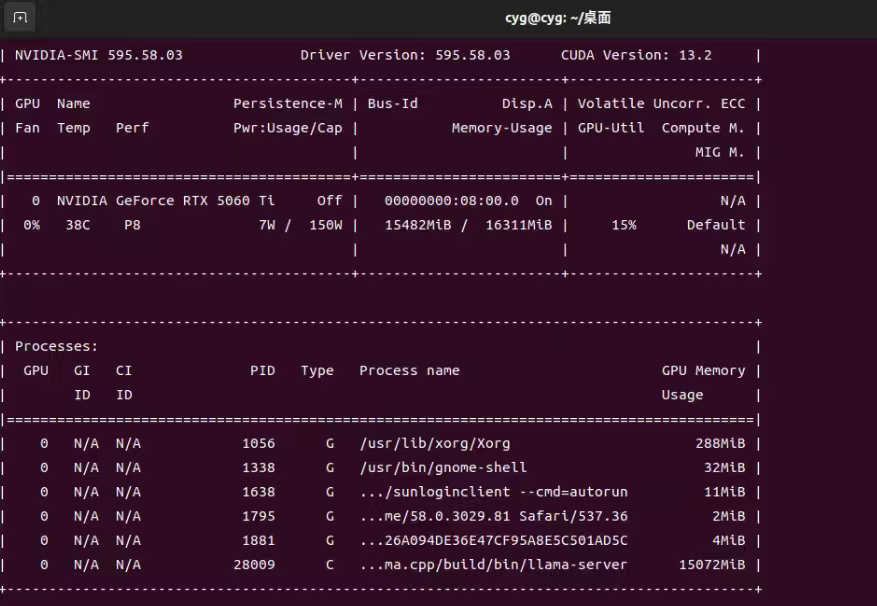
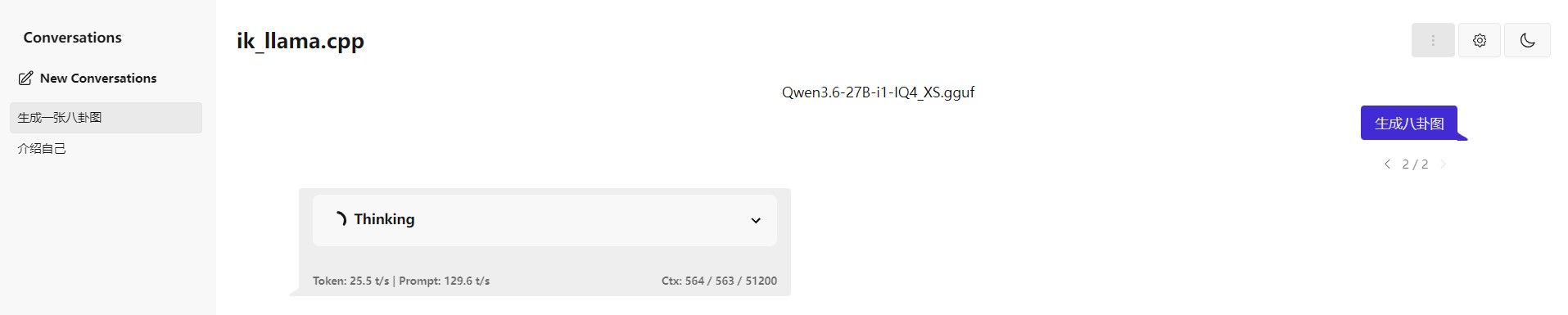
 不错,很有参考价值,你多上点图,我云一期,实际截图啊,别坑我。单独发个帖子,我给置顶。
不错,很有参考价值,你多上点图,我云一期,实际截图啊,别坑我。单独发个帖子,我给置顶。