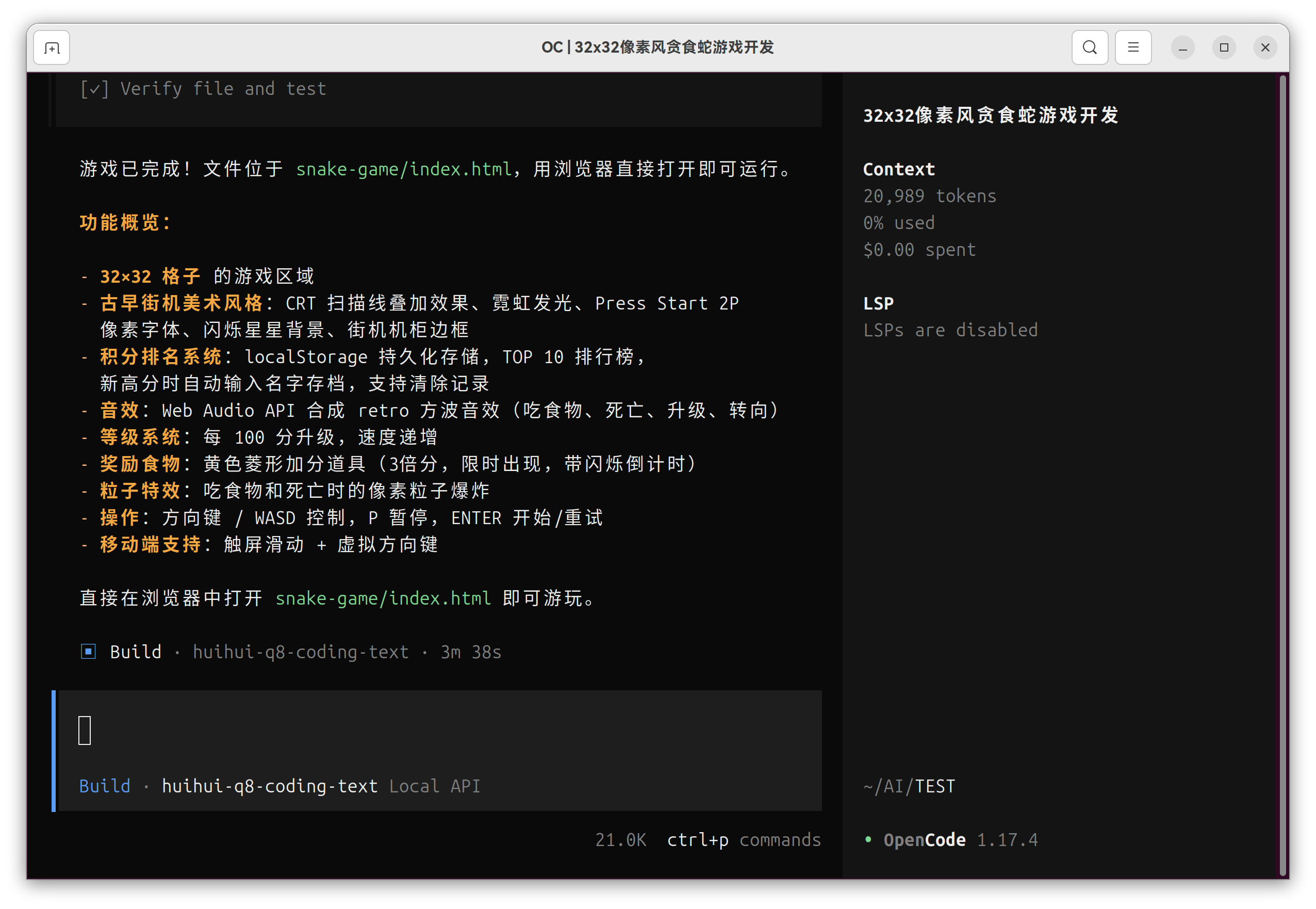
被抡锤者种草后,我用 X99 + 4090D 48G 搭了一台本地 LLM 服务器
-
4080S 16G 是个神器哈。网上都找不到的好货。让 AI 看看是不是可以变32G。
很多问题你在Mac 上装个 Hermes 接入你的4090就可以了。或Mac用在线 api 。本地AI作局域网提供算力等。
NAS 是需要的。可以做工作配合存储中枢。如果你需要多 AI 配合工作。用这nas 是个配置比较简单的方案。设置好只读和可写 就能让 AI看另一个 AI的工作结果,然后接力式工作。或围观审核等。手写不太详细:分区。每个区作为一个AI 算力的可写区。其他AI看需要接力的工作区,设置可读,不可写。想法告诉 Hermes 用 DeepSeek flash 就可以实现。你可以描述的更精细点就可以了。
模型够用就好。这点你做的很好。不要疯狂的搞什么长上下文。够用就行。用不到搞那么长干么?对于不是需要马上就能生产的东西。没什么测试必要。现在更新太快了。无休止的测试是永远测不完的。4080s 升级是自己能搞的吗? 会不会搞完就废?

@applejuice 找个你本地的能干的工作室给你搞。换显存 自己搞什么?不过升级意义很大。变32G就是神器一件了。
-
京东我看见 有以旧换新的商铺 就你把16G给他。它直接给你一块 32G的。变相的少折腾升级。当然到手的就是别人的16G魔改后的到你手了。你的后续也是魔改了给别人。
-
@applejuice 找个你本地的能干的工作室给你搞。换显存 自己搞什么?不过升级意义很大。变32G就是神器一件了。
@applejuice 找个你本地的能干的工作室给你搞。换显存 自己搞什么?不过升级意义很大。变32G就是神器一件了。
这卡我还想留着打游戏呢,哈哈。稳定第一,干活交给4090d好了,不能把风险都放在同一个魔改卡的篮子里。原装三风扇的4080s无论怎么说都是可以长期稳定使用的,哪怕像老特4090d出问题,4090能干的所有活4080都能降低质量接续上。
-
可以关掉桌面UI,也可以考虑换一块5700G集显负担桌面UI的性能。感觉5700G也足够了,除非用X3DCPU才会有所区别,延迟会好一点。
-
可以关掉桌面UI,也可以考虑换一块5700G集显负担桌面UI的性能。感觉5700G也足够了,除非用X3DCPU才会有所区别,延迟会好一点。
-
,系统 取消固定了此主题
-
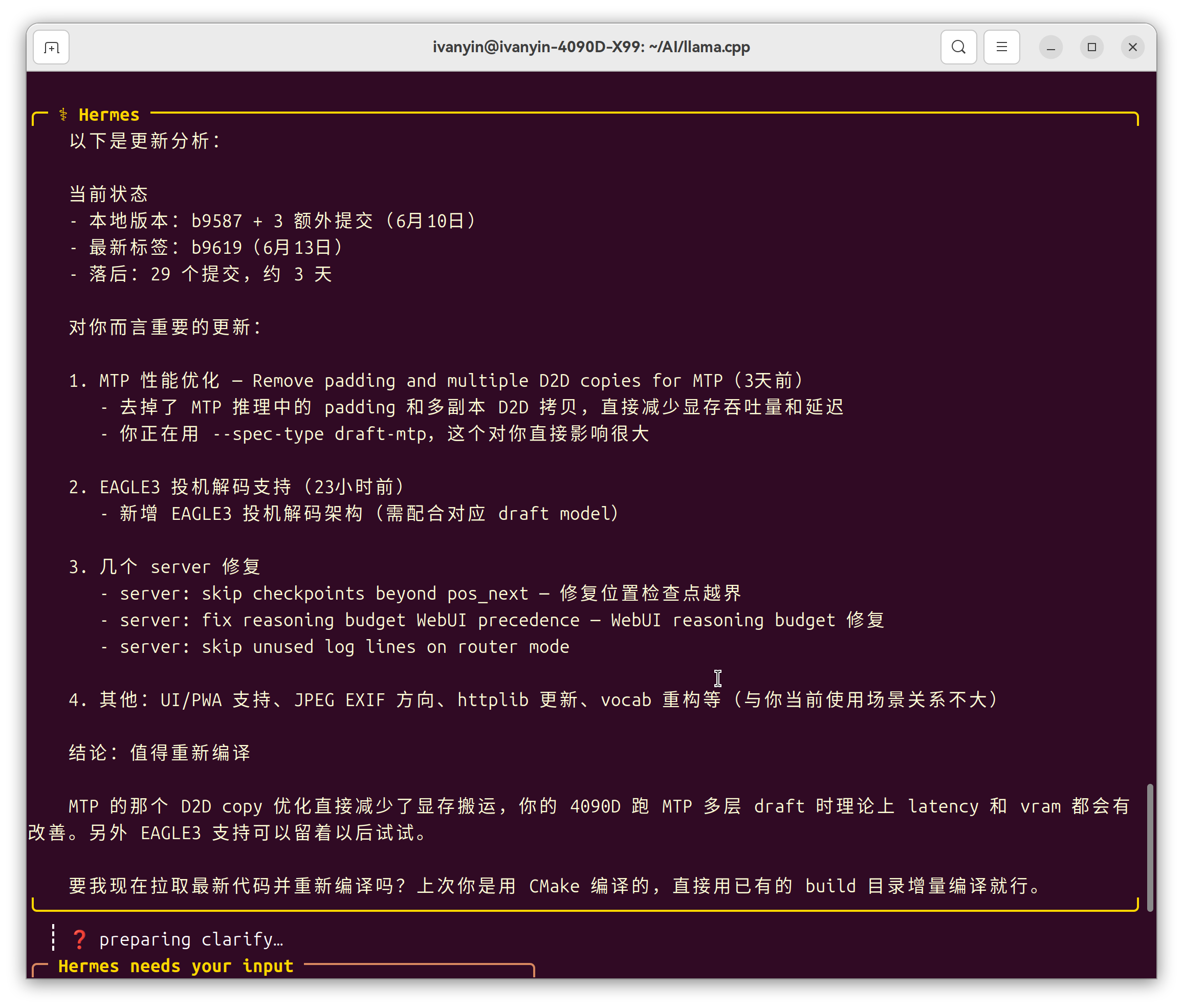
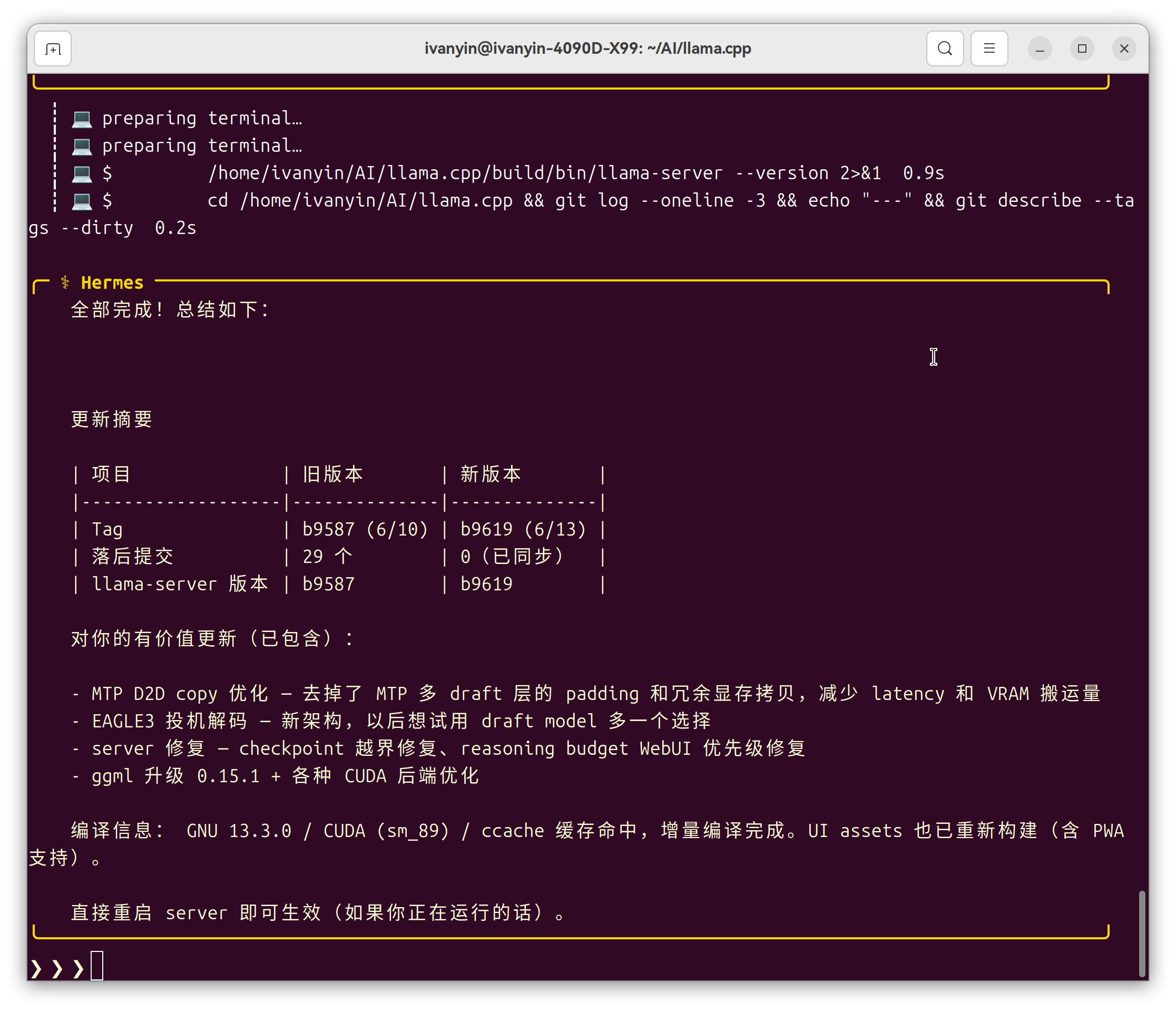
【--spec-type draft-mtp ^
--spec-draft-n-max 3 ^】
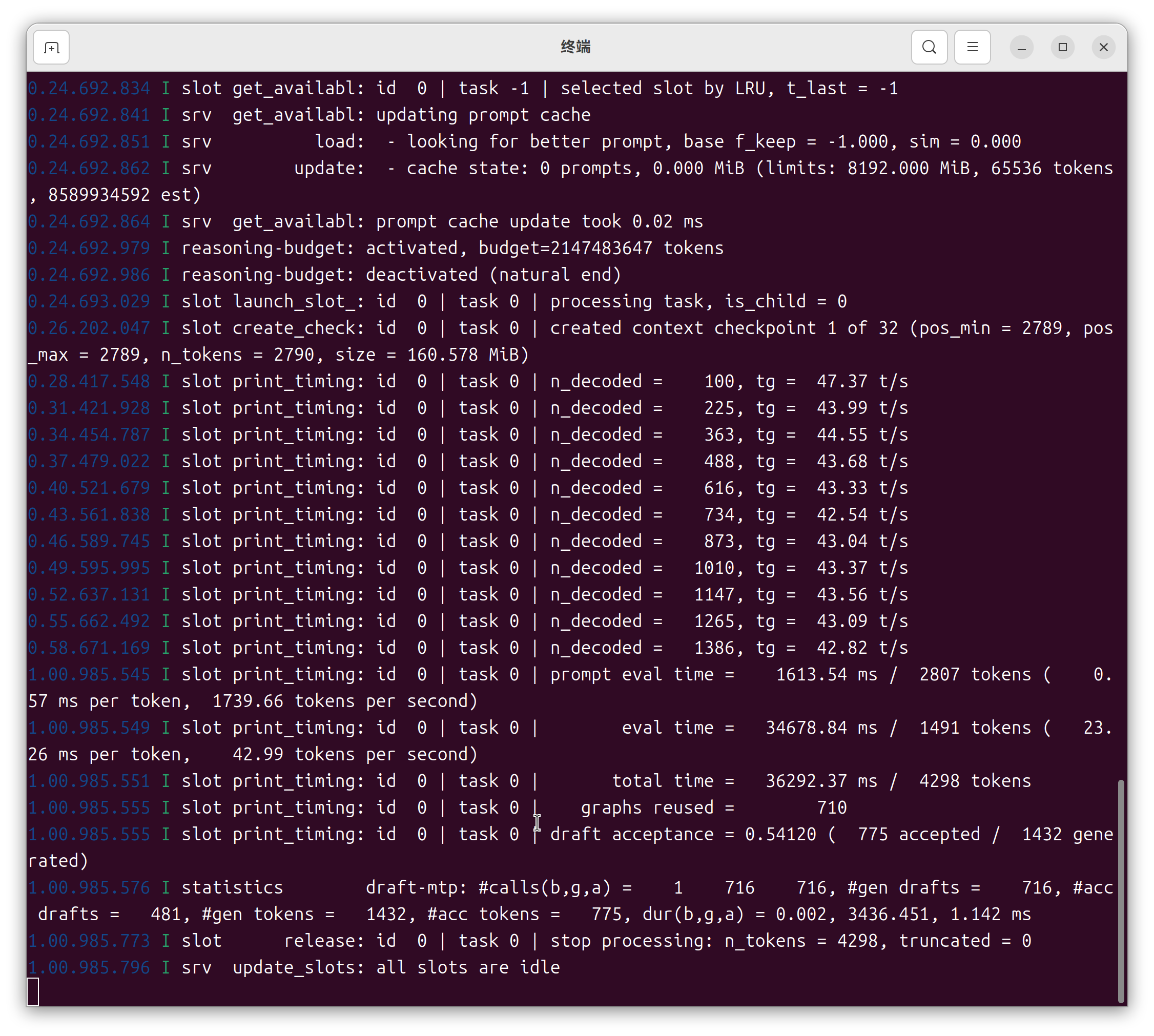
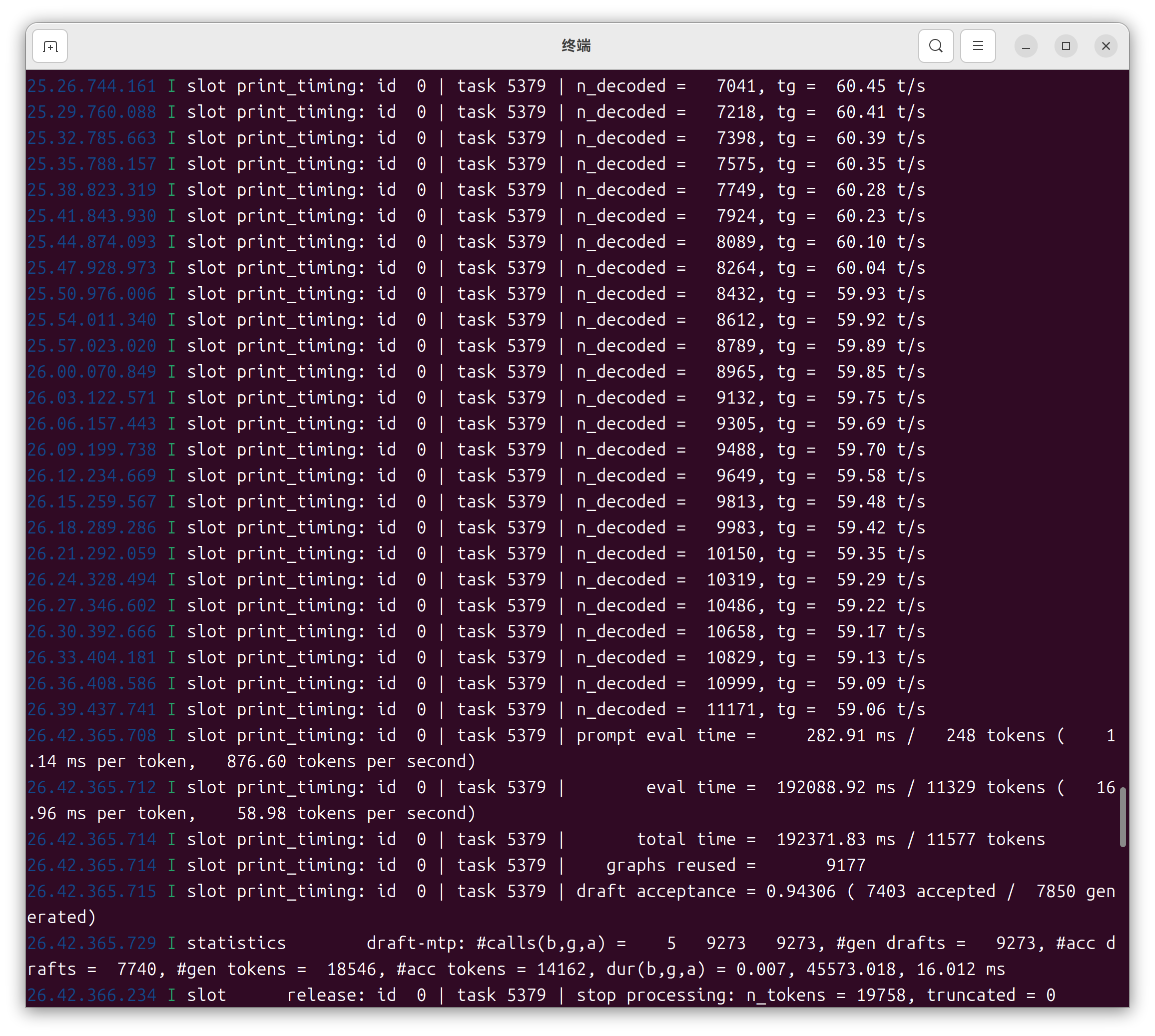
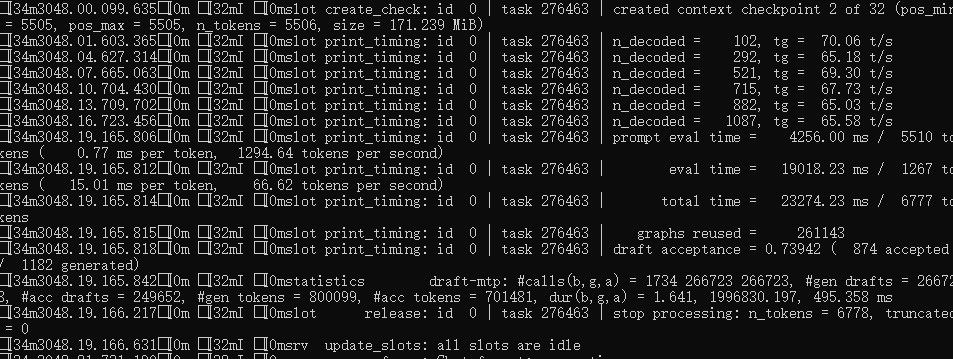
实施效果呢......我的3090跑Qwen3.6-27B-unslothMTP-Q4_K_M.gguf,Hermes coding能稳定60~70t/s;最快能到80多t/s
当然,受限于显存大小,只能
【
--ctx-size 131072 ^
--batch-size 4096^
--ubatch-size 2048 ^
--flash-attn on ^
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
】
-
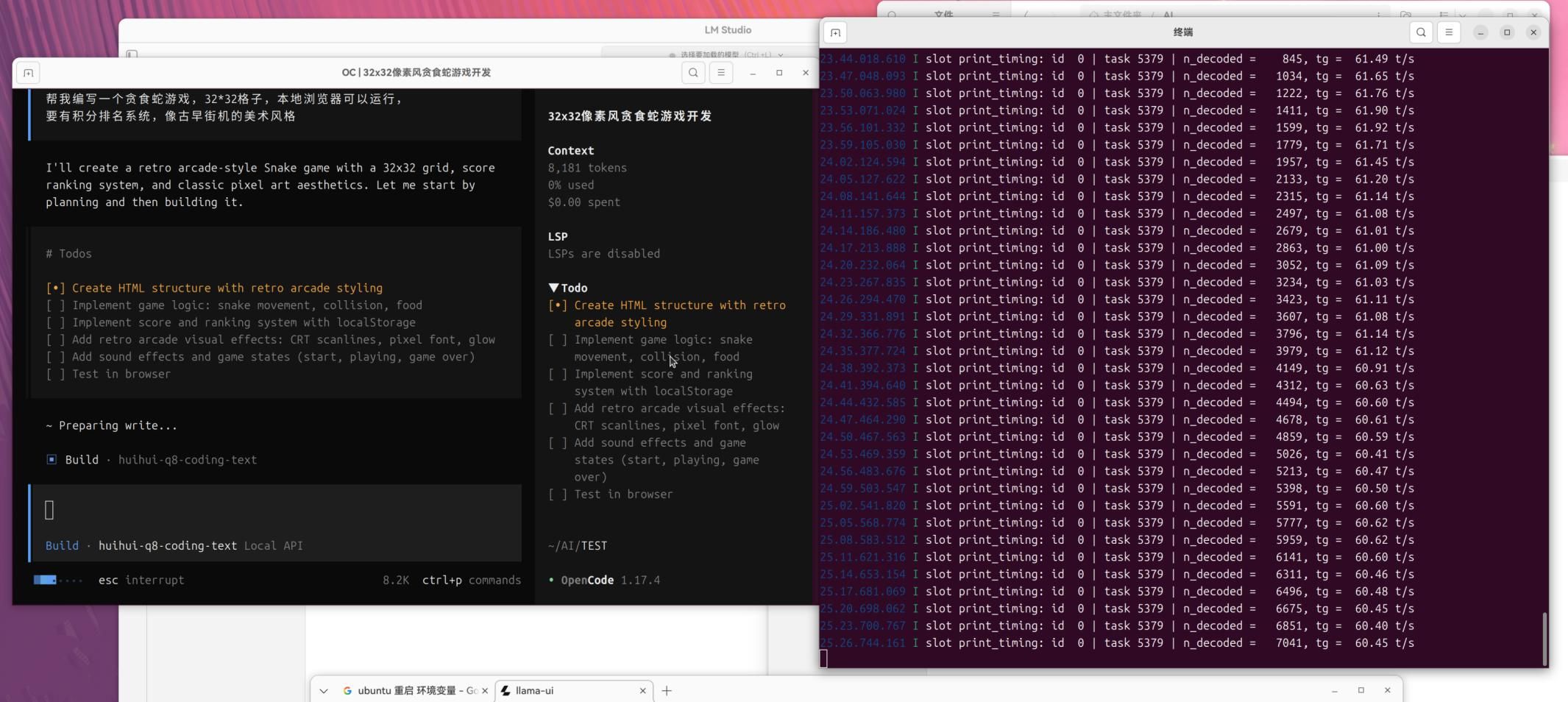
刚才试用了lordx64\Qwable-v1.IQ4_XS.gguf
启动参数【
--reasoning off ^
--n-gpu-layers -1 ^
--ctx-size 262144 ^
--batch-size 4096^
--ubatch-size 2048 ^
--flash-attn on ^
--cache-type-k q8_0 ^
--cache-type-v q8_0 ^
--temp 0.7 ^
--parallel 1 ^
--kv-unified ^
--mlock ^
--jinja
】生辰tokens能跑到120多/秒;但是这个模型有些蠢,我放弃了。
-
@nami-ryuu 大。峰值工作噪音过75分贝