双卡AI Pro R9700 32g,Qwen 3.6 27b FP8 256k SGlang部署成功
-
Hermes+Deepseek整理,不保证全对。
硬件环境
组件 详情 CPU Intel Xeon E5-2686 v4 主板 X99(无 GPU P2P 直连) GPU 2× AMD Radeon AI PRO R9700 (RDNA4 / gfx1201) 显存 每卡 32 GB GDDR6 系统内存 62 GB OS Ubuntu 24.04 ROCm 7.2.4 Python 3.12 (conda: sglang-triton36) 模型信息
参数 数值 模型 Qwen3.6-27B-FP8(HuggingFace 本地缓存) 架构 Qwen3.5 (GDN + 混合注意力),64 层 量化 Native FP8 (e4m3, dynamic activation scheme) 模型大小 29 GB(磁盘) 隐藏维度 5120 注意力头 24 (Q) / 4 (KV),head_dim=256 词表 248,320 最大上下文 262,144 (256K) 当前配置 (2026-06-15)
启动命令
# 激活环境 export PATH="/home/xxx/miniforge3/bin:/home/XXX/.cargo/bin:$PATH" source /home/XXX/miniforge3/etc/profile.d/conda.sh conda activate sglang-triton36 # 启动服务 python -m sglang.launch_server \ --model-path /home/XXX/models-hf/Qwen3.6-27B-FP8 \ --tp-size 2 \ --mem-fraction-static 0.75 \ --context-length 262144 \ --attention-backend triton \ --fp8-gemm-backend triton \ --trust-remote-code \ --port 23334 \ --host 0.0.0.0 \ --disable-custom-all-reduce \ --cuda-graph-max-bs 1 \ --cuda-graph-bs 1 \ --max-running-requests 1 \ --num-continuous-decode-steps 8 \ --max-mamba-cache-size 8 \ --chunked-prefill-size 8192 \ --disable-overlap-schedule \ --tool-call-parser qwen3_coder \ --chat-template /home/XXX/models-hf/Qwen3.6-27B-FP8/chat_template_nothink.jinja \ --speculative-algorithm NEXTN \ --speculative-num-steps 5 \ --speculative-num-draft-tokens 2 \ --speculative-eagle-topk 1 \ --allow-auto-truncate \ --log-requests关键参数说明
参数 值 原因 --tp-size 2双卡 TP 256K 单卡装不下 KV cache --mem-fraction-static 0.7575% 显存 MTP draft graph 额外占用,0.80 会 OOM --context-length 262144256K 上下文 模型最大上下文 --fp8-gemm-backend tritonTriton GEMM RDNA4 最优 FP8 矩阵乘后端 --disable-custom-all-reduce禁用 X99 无 GPU P2P,必须禁用 --cuda-graph-max-bs 1单 batch graph CUDA graph 解码提速 --disable-overlap-schedule禁用 overlap Mamba no_buffer 不兼容 --tool-call-parser qwen3_coderQwen3 工具调用 Hermes Agent function calling --chat-template nothink.jinja自定义模板 关闭 thinking(无 reasoning_parser,模板去掉了 <think>标签)--speculative-algorithm NEXTNMTP (EAGLE) 内建 MTP 加速解码 --speculative-num-steps 55 步 draft 最优值:4.38 accept_len,68% accept_rate --speculative-num-draft-tokens 2每步 2 token 配合 steps=5 --speculative-eagle-topk 1单分支 topk=2 无额外收益且占更多显存 --allow-auto-truncate自动截断 超过 KV cache (147K tokens) 自动截断而非 400 报错 --max-running-requests 1单请求 单用户优化 --log-requests请求日志 生产调试 显存分配 (256K 上下文 + MTP)
GPU 模型权重 KV Pool Draft Graph CUDA Graph + 驱动 余量 GPU0 ~17 GB ~8 GB ~0.3 GB ~5 GB ~5.6 GB GPU1 ~17 GB ~8 GB ~0.3 GB ~5 GB ~5.6 GB max_total_num_tokens=146964,allow_auto_truncate=True超过自动截断。思考模式
reasoning_parser=None— 无 reasoning parserchat_template_nothink.jinja— 自定义模板,add_generation_prompt 中不输出<think>标签enable_thinking变量处理已完全移除- 模型训练行为残留的
<think>标签(output_ids 以 248068=`
<||DSML||tool_calls>
<||DSML||invoke name="write_file">
<||DSML||parameter name="content" string="true"> 开头)属于模型输出内容,不影响 reasoning_tokens(始终为 0)- NOTE: 编辑
chat_template_nothink.jinja后禁止还原 <think> 标签。如 SGLang 版本升级后模板行为变化,参考本文件的"思考模式"说明进行调试。
性能基准
Decode 速度 (MTP steps=5)
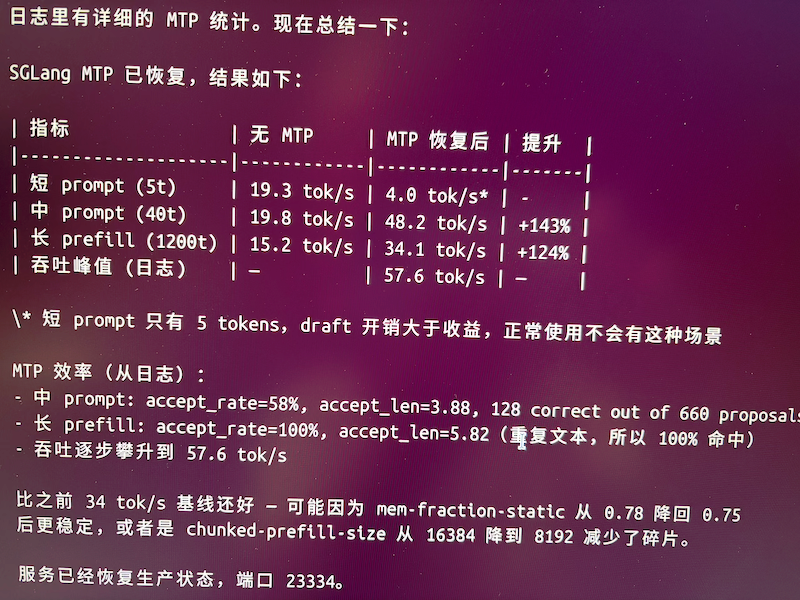
场景 速度 (MTP) 速度 (无 MTP) 提升 短上下文 (<1K) ~34 tok/s ~18 tok/s +89% 中等上下文 (4K–32K) ~30 tok/s ~18 tok/s +67% MTP 参数对比测试结果
steps draft_tokens topk 速度 accept_len accept_rate 无 MTP - - ~18 tok/s - - 1 2 1 ~24 tok/s 1.88 88% 3 2 1 ~29 tok/s 3.08 69% 4 2 1 ~30 tok/s 3.38 56% 5 2 1 ~34 tok/s 4.38 68% 6 2 1 ~33 tok/s 4.62 60% 5 4 2 ~28 tok/s 3.23 72% 最优:steps=5, draft_tokens=2, topk=1。Steps=2 以上会在 CUDA graph 捕获阶段增加 draft graph(约 0.3GB 显存开销)。
Prefill 速度 (chunk_size=8K)
上下文 速度 16K ~473 tok/s 64K ~450 tok/s 108K ~407 tok/s 环境搭建步骤
1. 安装 Miniforge3
curl -L -o /tmp/miniforge.sh "https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-Linux-x86_64.sh" bash /tmp/miniforge.sh -b -p /home/gaopy/miniforge32. 安装 Rust (SGLang 编译需要)
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- -y3. 克隆并运行 SGLang RDNA4 setup
git clone https://github.com/mattbucci/2x-R9700-RDNA4-GFX1201-sglang-inference.git sglang-rdna4 cd sglang-rdna4 export PATH="/home/gaopy/miniforge3/bin:/home/gaopy/.cargo/bin:$PATH" bash scripts/setup.sh4. 修复依赖冲突
conda activate sglang-triton36 cp components/sglang/sgl-kernel/python/sgl_kernel/*.py $CONDA_PREFIX/lib/python3.12/site-packages/sgl_kernel/ pip install kernels==0.14.1 pip install --force-reinstall --no-deps transformers==5.8.0 bash scripts/build_awq_gemv.sh --env sglang-triton36 cd components/sglang git checkout v0.5.12 for p in ../../patches/0*.patch; do git apply --3way "$p" 2>/dev/null; done pip install -e "python[all]" --no-build-isolation --no-deps5. 下载模型(FP8)
huggingface-cli download Qwen/Qwen3.6-27B-FP8 \ --local-dir /home/gaopy/models-hf/Qwen3.6-27B-FP8 \ --max-workers 4服务接口
# 健康检查 curl http://localhost:23334/health # 模型列表 curl http://localhost:23334/v1/models # 推理 (OpenAI 兼容) curl http://localhost:23334/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "/home/XXX/models-hf/Qwen3.6-27B-FP8", "messages": [{"role": "user", "content": "Hello"}], "max_tokens": 100, "temperature": 0.7 }'已知问题
- thinking 残留 — 模型训练行为,
</think>标签以248068/248069token 形式出现在输出开头,不影响内容质量 - X99 无 GPU P2P — 多卡必须用
--disable-custom-all-reduce - 首次启动慢 — 模型加载 + KV cache 分配 + CUDA graph + draft graph 捕获约 90 秒
- FP8 GEMM 警告 — 启动时提示
Using default W8A8 Block FP8 kernel config,性能可能未达最优,等待社区提交 R9700 调优配置 - Triton deprecation warning —
tl.where with non-boolean condition,当前不影响运行
版本历史
日期 变更 2026-06-15 MTP 加速 (+89%, ~34 tok/s);思考关闭 (no-think v2 模板);添加 --allow-auto-truncate;上下文 256K 2026-06-14 从 AWQ 切换到 Native FP8;添加 no-think 模板绕过 reasoning_parser 自动检测 2026-06-13 初始部署:AWQ + 256K,后因 OOM 切换 FP8 -
,
 T terry 固定了此主题
T terry 固定了此主题
-
,系统 取消固定了此主题