
-
-
我测试了vllm 3090 24G 开启MTP就爆显存了 没法用 llama有45t/s不错了 我的vllm只有34t/s
-
llama.cpp mtp 确实可以用, 我的 ai max 395 跑 qwen3.6-27b 24T/s
参考这个社区主题
mtp 分支还没有合并到主分支,目前还存在的问题
- 只支持np = 1
- 暂不支持多模态
-
llama.cpp mtp 确实可以用, 我的 ai max 395 跑 qwen3.6-27b 24T/s
参考这个社区主题
mtp 分支还没有合并到主分支,目前还存在的问题
- 只支持np = 1
- 暂不支持多模态
@高乐天
感谢这位仁兄,我也一样是 ai max 395 目前用Ollama 跑 qwen3.6-27b 只有 12T/s
但是用了你介绍的方法,速度几乎翻倍了。以下贴上具体数据给大家参考一下。
再次感谢 @高乐天 !<当前运行环境 & 模型>
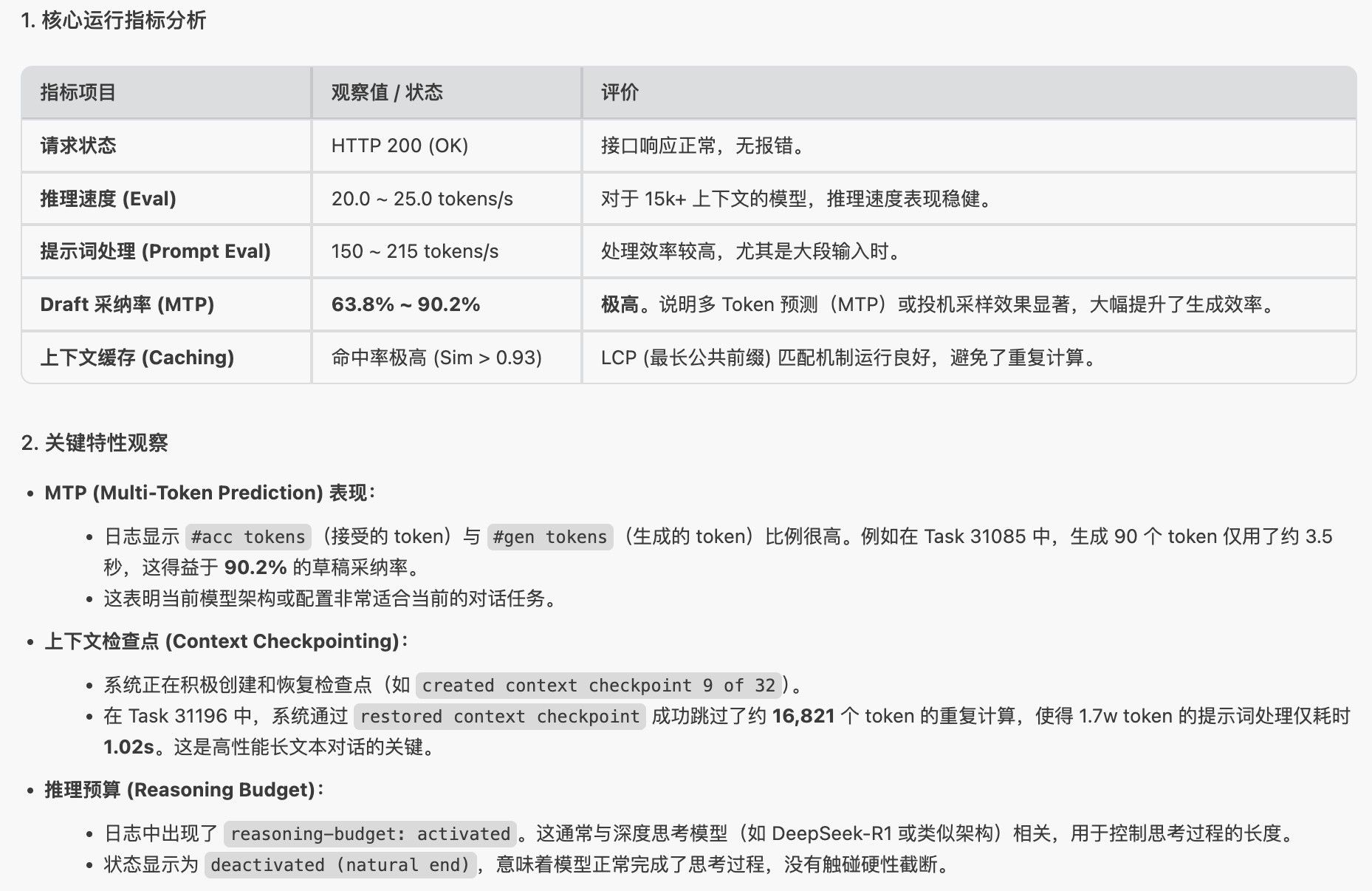
项目 详情 模型 qwen3.6-27b-mtp(Qwen 3.6 27B + MTP 推测解码)运行硬件 Ryzen AI Max+ 395 + Radeon 8060S 集显 MTP draft 设定 3 <最新测速结果>
阶段 Token 数 耗时 速度 Prompt 处理 45 tokens 421ms ~107 token/s Token 生成(MTP) 500 tokens 24.8s ~20.2 token/s 总计 545 tokens ~25.2s ~21.6 token/s <MTP 推测解码效率>
指标 数值 说明 Draft tokens(草稿) 585 推测解码产生的草稿 token 总数 Accepted(接受) 304 通过验证直接跳过的 token 接受率 ~52% 约一半的草稿被直接接受,省掉了验证开销 预测加速比 500 / 304 ≈ 1.64x 相比无 MTP 的纯串行生成,理论加速约 1.6 倍 -
闻闻 4090-24G 的味都是好的。前代神卡。够玩一段了。
-
 T terry 于 将此主题从 AI硬件 移至此处
T terry 于 将此主题从 AI硬件 移至此处