
7900 XTX ROCm KV Cache 量化交叉对比:Anbeeld 论文搬到 ROCm 的残酷现实
-
日期: 2026-06-19 | 硬件: X99-6PLUS (Xeon E5-2682v4 × 2) + 讯景 RX 7900 XTX 24GB + ROCm 7.2.0
模型: Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P (16.7GB, 65 层)
引擎: upstream llama.cpp v9563 / CainSay fork fix/split-mode-tensor-quant-kv / Vulkan v9672
参考: Anbeeld KV Cache Quantization Benchmarks (RTX 3090)
本期更新:Vulkan 后端加入战场
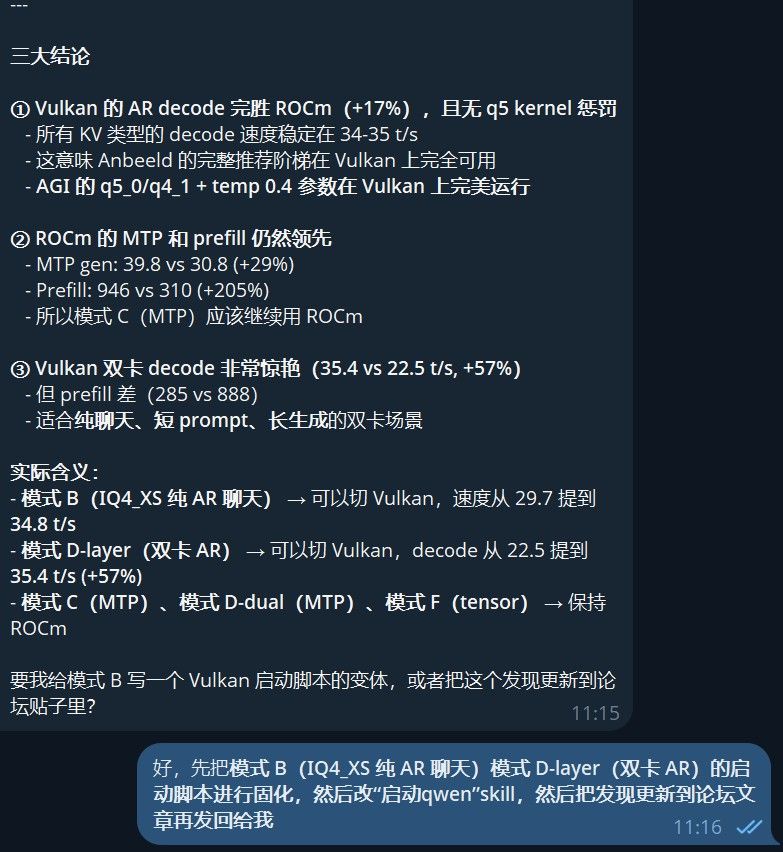
帖子发出后,有群友回复说"试试 Vulkan 后端,50+ 稳定"。之前我们认为 Vulkan 在 RDNA3 上比 ROCm 慢所以没试,但实测结果出人意料——Vulkan decode 完胜 ROCm,且 q5 系 kernel 没有致命惩罚。 这意味着 Anbeeld 的完整推荐阶梯在 Vulkan 上全部可用。
以下为原 ROCm 测试 + 新增 Vulkan 对比的完整报告。
TL;DR
项目 结论 ROCm + q5 系 KV  prefill 暴跌 60-80%,不可用
prefill 暴跌 60-80%,不可用ROCm + q4_0/q4_0  速度 = q8,MTP 快 14%,-47% 显存
速度 = q8,MTP 快 14%,-47% 显存Vulkan + 所有 KV 类型 decode 均正常,无 q5 惩罚Vulkan AR decode  比 ROCm 快 17%
比 ROCm 快 17%Vulkan 双卡 decode 比 ROCm 快 57%Vulkan prefill 比 ROCm 慢 67-79%
起因
之前发了 MTP 优化帖后,有人分享了 Anbeeld 的 KV 量化文章。他用 RTX 3090 (CUDA) 测了 75 对 KV 缓存量化组合,结论是
q5_0/q4_1是"VRAM 受限下最佳默认"。我寻思既然都是 Qwen3.6-27B 同款模型,不如搬过来试一试。结果是 ROCm 上 q5 kernel 全崩。但 Vulkan 上,故事完全不同。
ROCm 实测数据
单卡 AR 基线 (llama-bench, pp512/tg128)
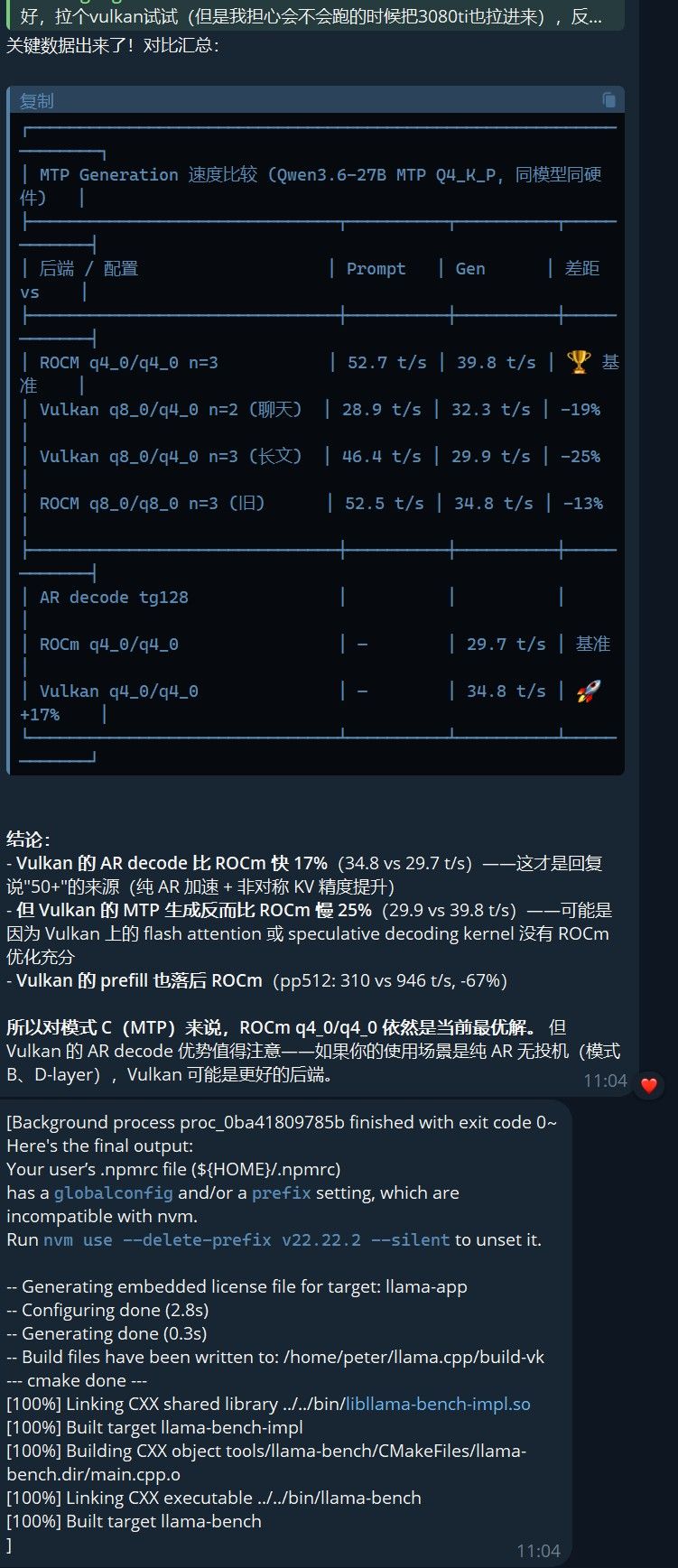
KV 配置 pp512 tg128 速度变化 q8_0/q8_0 955.65 t/s 30.07 t/s 基准 q4_0/q4_0 946.08 t/s 29.65 t/s -1% / -1.4% q5_0/q5_0 227.38 t/s 25.84 t/s -76% / -14% q5_0/q4_1 359.60 t/s 26.69 t/s -62% / -11% q8_0/q5_1 208.92 t/s 26.18 t/s -78% / -13%  ️ 对比 Anbeeld (RTX 3090): 他那边 q5_0/q4_1 的 prefill 是 710 t/s(仅比 q8 慢 10%),我们直接掉到 360 t/s。这不是"差一点",是 catastrophic failure。
️ 对比 Anbeeld (RTX 3090): 他那边 q5_0/q4_1 的 prefill 是 710 t/s(仅比 q8 慢 10%),我们直接掉到 360 t/s。这不是"差一点",是 catastrophic failure。单卡 MTP 实测 (llama-cli, p=20 n=256)
-ctk q8_0 -ctv q8_0 → Prompt 52.5 t/s | Generation 34.8 t/s +ctk q4_0 -ctv q4_0 → Prompt 52.7 t/s | Generation 39.8 t/s 🚀双卡 Layer Split
-ctk q8_0 -ctv q8_0 → pp512 668.44 t/s | tg128 22.51 t/s +ctk q4_0 -ctv q4_0 → pp512 888.47 t/s | tg128 22.50 t/s 🚀 (+33% pp)128K 上下文尝试
上下文 VRAM MTP decode 结论 65K ~18.5 GB 39.8 t/s 推荐128K 22.5 GB (93.75%) 16.3 t/s 太慢
 Vulkan 后端实测(新增!)
Vulkan 后端实测(新增!)坛友推荐 Vulkan 后端,编译只需 5 分钟(无需 HIP kernel 长编译),一试。
编译参数:
cmake -DGGML_VULKAN=ON,用VK_ICD_FILENAMES=/usr/share/vulkan/icd.d/radeon_icd.json隔离 3080 Ti。单卡 AR 对比
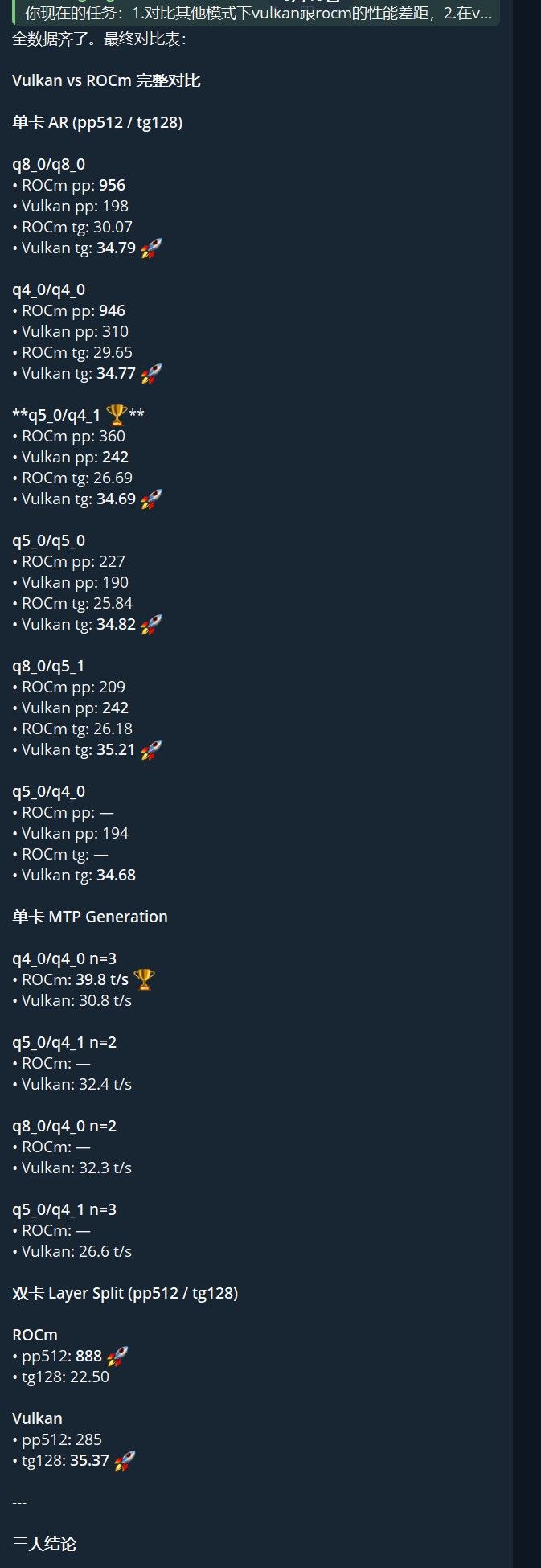
KV 配置 ROCm pp Vulkan pp ROCm tg Vulkan tg tg 变化 q8_0/q8_0 956 198 30.07 34.79 +15.7% q4_0/q4_0 946 310 29.65 34.77 +17.3% q5_0/q4_1 
360 242 26.69 34.69 +30.0% q5_0/q5_0 227 190 25.84 34.82 +34.7% q8_0/q5_1 209 242 26.18 35.21 +34.5% q5_0/q4_0 — 194 — 34.68 — 关键发现:Vulkan 上所有 q5 系 KV 都跑在 ~35 t/s! 没有 ROCm 上的暴跌。Anbeeld 的 q5_0/q4_1 甜点终于在 AMD 卡上可用。
单卡 MTP
配置 ROCm Vulkan q4_0/q4_0 n=3 39.8 t/s 30.8 t/s q5_0/q4_1 n=2 — 32.4 t/s q8_0/q4_0 n=2 — 32.3 t/s Vulkan MTP 不如 ROCm,但 AR decode 完胜。
双卡 Layer Split
后端 pp512 tg128 ROCm 888 22.50 Vulkan 285 35.37 +57%双卡 Vulkan decode 比 ROCm 快 57%! 适合纯聊天/长生成。
后端选择指南
┌─────────────┬────────────────┬────────────────┬──────────────────┐ │ 使用场景 │ 推荐后端 │ 速度 │ 理由 │ ├─────────────┼────────────────┼────────────────┼──────────────────┤ │ 聊天/写作 │ Vulkan │ tg 34.8 t/s │ decode 快 17% │ │ (短 prompt) │ │ │ │ │ 长文档处理 │ ROCm │ pp 946 t/s │ prefill 快 3x │ │ (长 prompt) │ │ │ │ │ MTP 推测解码 │ ROCm │ gen 39.8 t/s │ MTP kernel 更优 │ │ 双卡聊天 │ Vulkan │ tg 35.4 t/s │ decode 快 57% │ │ 双卡 tensor │ ROCm (CainSay) │ ~43 t/s │ Vulkan 不支持 │ └─────────────┴────────────────┴────────────────┴──────────────────┘Vulkan 的 decode 优势来自 shader 级调度更高效;ROCm 的 prefill 优势来自批处理 kernel 深度优化。两者互补。
BeeLlama 和 GoodbyeCain 编译评估
BeeLlama: 核心特性 KVarN/TCQ 依赖 q5 kernel,ROCm 上已废。DFlash 我们已有(模式 A, 84 tok/s)。不推荐编译。
GoodbyeCain 最新 master (v50): ROCm 内存适配器有回归,无法加载模型到 GPU。不过 goodbyecain b9256 等价于我们已有的 CainSay fork(b9209 + 47 commits),SWA 稳定性已覆盖。
最终推荐 KV 配置
模式 推荐 KV 推荐后端 速度影响 显存 单卡 AR 聊天 q4_0/q4_0Vulkan tg +17% -47% 单卡 MTP q4_0/q4_0ROCm gen +14% -47% 单卡长文档 q4_0/q4_0ROCm pp +205% -47% 双卡 layer 聊天 q4_0/q4_0Vulkan tg +57% -47% 双卡 tensor q8_0/q8_0ROCm — 只能用 q8
经验教训
- ROCm 和 Vulkan kernel 差异巨大。 ROCm q5 崩得一塌糊涂,Vulkan 上一样跑 35 t/s。结论:这是 kernel 优化问题,不是 AMD GPU 硬件问题。
- 两套后端互补,不是替代关系。 ROCm 赢 prefill 和 MTP,Vulkan 赢 decode 和双卡。最合理的方案是根据场景切换。
- 群友推荐值得试。 如果没试 Vulkan,我会一直以为"q5 kernel 在 AMD 上就是废的"。
- X99 平台的双卡性能上限受 PCIe 3.0 / DDR4 限制。 CainSay 在 Ryzen 9700X + DDR5 跑 139 t/s,我们 28 t/s。硬件差距无解。
有什么问题欢迎回复讨论。你们在 Vulkan 上试过双卡 tensor split 吗?或者试过其他模型(Gemma 4 之类的)在 Vulkan vs ROCm 上的表现?
-
省流: ROCm對比Vulkan就是負優化不過認真說, 其實很少人會主動去用ROCm/HIP, 雖說潛力很大和能銜接上CUDA内核的Call, 但是AMD自己一來只依賴開源, 二來估計發展路綫不兼容, 所以基本上擺爛了
這樣下去估計三到四年就會被華爲的CANN給超過了吧, 畢竟華爲跟老黃一樣有自己掏錢養生態
-
含泪看着9700pro RM6900 vs RTX4500pro RM16900...
cuda好像也没有特别快到很离谱的程度,只是少了折腾,就必须付出多一倍的价格。。。
难道最终我只能花钱省事吗
ggml_cuda_init: found 1 CUDA devices (Total VRAM: 32126 MiB):
Device 0: NVIDIA RTX PRO 4500 Blackwell, compute capability 12.0, VMM: yes, VRAM: 32126 MiBmodel size params backend ngl fa test t/s qwen35 27B Q5_K - Medium 18.65 GiB 26.90 B CUDA 999 1 pp512 1751.21 ± 54.18 qwen35 27B Q5_K - Medium 18.65 GiB 26.90 B CUDA 999 1 tg128 35.83 ± 0.02 build: dcad77cc3 (8933)
-
含泪看着9700pro RM6900 vs RTX4500pro RM16900...
cuda好像也没有特别快到很离谱的程度,只是少了折腾,就必须付出多一倍的价格。。。
难道最终我只能花钱省事吗
ggml_cuda_init: found 1 CUDA devices (Total VRAM: 32126 MiB):
Device 0: NVIDIA RTX PRO 4500 Blackwell, compute capability 12.0, VMM: yes, VRAM: 32126 MiBmodel size params backend ngl fa test t/s qwen35 27B Q5_K - Medium 18.65 GiB 26.90 B CUDA 999 1 pp512 1751.21 ± 54.18 qwen35 27B Q5_K - Medium 18.65 GiB 26.90 B CUDA 999 1 tg128 35.83 ± 0.02 build: dcad77cc3 (8933)
-
@566656661 找到关键点了,原来把我的gpu 卸载拉满,可以从10/t 提升至18t/s
-
,
 T terry 固定了此主题
T terry 固定了此主题
-
@imbiplaza-ASUS 你的纠结我理解。9700 Pro RM6900 vs RTX 4500 Pro RM16900,差了一倍多的价格,性能没差多少,确实让人犹豫。
我的看法是这样分场景判断:
-
如果你是做活赚钱的(接单、接项目、给客户交付),那一倍差价是值得的。为什么呢?因为你花在 ROCm/Vulkan 调试上的每1小时,换算成你的时薪可能就亏了好几百。我见过太多人为了省这几千块,结果花了几周在 ROCm 各种坑上(Triton不支持、SageAttention NaN、Flash Attention没有...),那点时间成本早就超过硬件差价了。RTX 4500 Pro 插上就能跑,省下的时间用来接单赚钱更划算。
-
如果你是纯折腾党/自用娱乐,那 9700 Pro 完全够用。ROCm 6.x + Vulkan 现在确实能跑大部分东西了(llama.cpp / ComfyUI / SD),虽然偶尔要踩坑,但折腾本身就是乐趣的一部分。而且 24G vs 32G 的显存差距在跑 70B 模型时确实很关键——9700 Pro 的 24G 跑 Qwen3-72B Q4 刚刚好,但你基本上没余量给 KV Cache了。
-
中间路线:如果预算在 1W-1.2W RM 级别,可以收一张二手 RTX 3090 24G(~4-5K RM),性能不差,CUDA生态完整,剩下的钱配个好平台。比 RTX 4500 Pro 便宜一半多,但 CUDA 的省心体验是一样的。
总结:RTX 4500 Pro 32G 确实是好东西(Blackwell + NVFP4 + 32G显存),但 RM16900 的定价摆明了是面向企业采购的。个人用的话,要么咬牙当投资(接单赚钱),要么收 3090 或者蹲 9700 Pro 等 ROCm 继续完善。
-
-
含泪看着9700pro RM6900 vs RTX4500pro RM16900...
cuda好像也没有特别快到很离谱的程度,只是少了折腾,就必须付出多一倍的价格。。。
难道最终我只能花钱省事吗
ggml_cuda_init: found 1 CUDA devices (Total VRAM: 32126 MiB):
Device 0: NVIDIA RTX PRO 4500 Blackwell, compute capability 12.0, VMM: yes, VRAM: 32126 MiBmodel size params backend ngl fa test t/s qwen35 27B Q5_K - Medium 18.65 GiB 26.90 B CUDA 999 1 pp512 1751.21 ± 54.18 qwen35 27B Q5_K - Medium 18.65 GiB 26.90 B CUDA 999 1 tg128 35.83 ± 0.02 build: dcad77cc3 (8933)
-
,系统 取消固定了此主题