
Qwen3.6-27B 六大启动模式详解:性能、参数与场景
-
辛苦了大牛哥。棒棒哒。很全面的总结
-
,
 W williamlouis 固定了此主题
W williamlouis 固定了此主题
-
辛苦了大牛哥。棒棒哒。很全面的总结
-
@williamlouis
哈哈,不牛不牛,只是心痛我的账单
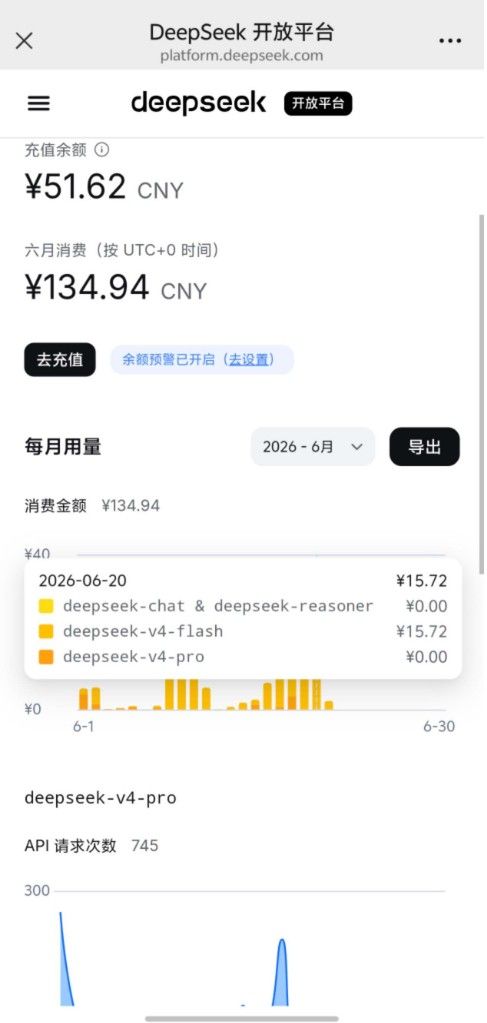
还没算上白嫖gemini的
-
@abaalei 知足常乐。兄弟。你已经选用了最经济的模型。 换个其他的你就知道什么叫肉疼。
-
-
准备搭个同样硬件抄作业
@Grayson-Ren 亲测 7900XTX 24G 可以做为门槛。做到入门级使用。可以干很多小显存项目。期待优化。
近期观察有 炒股,生图,无限制版小说,小短片等能力。 -
硬件环境:双路 7900 XTX (XFX MERC + Sapphire Pulse) + NVIDIA 3080 Ti (ACE-Step) | X99 DDR4-64G | ROCm 7.2.0/7.14 + Vulkan 双后端
编者注:
简而言之,对我来说
1.日常 Comfyui+Qwen 的话就选择----------### 模式 C — MTP 自我投机解码
2.写小说 --------------------------------### 模式 B — IQ4_XS 128K 长文本写作(30 / 37.7 tok/s)
3.想找个人/对象瞎聊一通--------------------### 模式 A — DFlash 投机解码(84 tok/s 纯跑分)
纯跑分)
3.想要双卡 进行Debug或者安全漏洞查测,就用---### 模式 E — 双卡 Q8_0 最高精度(~23 tok/s)前言
自从折腾上 Qwen3.6-27B 后,根据不同使用场景摸索出了 6 个标准模式(A/B/C 单卡 + D/E/F 双卡),外加 2 个 Vulkan 变体。每个模式针对不同的量化、后端、推理策略做了取舍。这篇文章把这些模式的性能数据、启动参数、适用场景完整整理出来,给后来者参考,也方便自己查阅。
模式命名规范:A/B/C = 单卡(用 XFX MERC,不影响 ComfyUI),D/E/F = 双卡(占用两张 7900 XTX,需停 ComfyUI)。Vulkan 变体加
-Vk后缀。
一、单卡模式 (A / B / C)
单卡统一用 XFX MERC(HIP_VISIBLE_DEVICES=0, UUID
GPU-8accafcdfee6fc4f),端口 11435,Sapphire Pulse 上的 ComfyUI 不受影响。总览
模式 速度 模型大小 量化 上下文 是否有 API 后端 A (DFlash) 84 tok/s 
15.4G+1.8G Q4_K_M + Q8 draft 32K  bench only
bench onlyROCm 7.2 B (IQ4_XS) ~30 / 37.7 tok/s 14G IQ4_XS (4.25 bpw) 131K 
ROCm / Vulkan C (MTP) ~40 tok/s 16.7G MTP Q4_K_P (65层) 65K ROCm 7.14
模式 A — DFlash 投机解码(84 tok/s
纯跑分)性能
- 单卡生成速度:~84 tok/s(Intel XEON E5-2680 v4 上验证)
- 使用 DFlash 草稿模型做投机解码,MTP 接受率 ~75%
- 限制:只能用
test_dflash/bench_he.py跑分,没有 llama-server,没有 OpenAI API
启动参数
export HIP_VISIBLE_DEVICES=GPU-8accafcdfee6fc4f export LD_LIBRARY_PATH=/opt/rocm-7.2.0/lib:$LD_LIBRARY_PATH export HSA_OVERRIDE_GFX_VERSION=11.0.0 cd /home/peter/lucebox-hub/dflash numactl --cpunodebind=0 --membind=0 python3 scripts/server.py \ --target '/mnt/models/Qwen3.6/Huihui-Qwen3.6-27B-abliterated.Q4_K_M.gguf' \ --draft models/dflash-draft-3.6-q8_0.gguf \ --budget 8 \ --max-ctx 32768 \ --fa-window 0 \ --tokenizer Qwen/Qwen3.6-27B \ --cache-type-k q8_0 \ --cache-type-v q4_0 \ --host 0.0.0.0 --port 11435适用场景
- 纯跑分/基准测试:验证硬件、对比投机策略效果
- 研究用途:DFlash 架构实验,不用于日常使用
 ️ 如果你需要速度且有 API server,选模式 C(MTP)更好
️ 如果你需要速度且有 API server,选模式 C(MTP)更好
血训:严禁把模式 A 的模型 + 标准 AR 引擎称为"模式 A"。正确命名应该是 A-AR(四不像,~30 tok/s 无投机),这已经是个独立配置,和模式 A(DFlash 84 tok/s)完全不同。
模式 B — IQ4_XS 128K 长文本写作(30 / 37.7 tok/s)
性能
后端 Prefill (pp512) Decode (tg128) 相对 ROCm ROCm 7.2.0 946 t/s 29.7 t/s — Vulkan 697 t/s (-26%) 37.7 t/s (+27%) 
短 prompt 优 ROCm 7.14 + XNACK=1 ~950 t/s ~29.4 t/s 无收益键发现:IQ4_XS 在 ROCm 7.14 + HSA_XNACK=1 上无收益(pp+1%, tg-2%)。高压缩比量化(4.25 bpw)的访存模式不利于 XNACK 机制。
启动参数
ROCm 版(start-qwen-b.sh):
export LD_LIBRARY_PATH=/home/peter/llama.cpp/build-rocm/bin:/opt/rocm-7.2.0/lib:$LD_LIBRARY_PATH export HIP_VISIBLE_DEVICES=GPU-8accafcdfee6fc4f export HSA_OVERRIDE_GFX_VERSION=11.0.0 numactl --cpunodebind=0 --membind=0 llama-server \ -m /mnt/models/Qwen3.6/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-IQ4_XS.gguf \ -c 131072 -ngl 99 \ -fa 1 \ --no-mmap \ --tensor-split 0 \ --cont-batching \ --cache-type-k q4_0 --cache-type-v q4_0 \ --host 0.0.0.0 --port 11435Vulkan 版(start-qwen-b-vk.sh,decode +27%):
export VK_ICD_FILENAMES=/usr/share/vulkan/icd.d/radeon_icd.json export LD_LIBRARY_PATH=/home/peter/llama.cpp/build-vulkan-new/bin:$LD_LIBRARY_PATH export HSA_OVERRIDE_GFX_VERSION=11.0.0 numactl --cpunodebind=0 --membind=0 llama-server \ -m /mnt/models/Qwen3.6/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-IQ4_XS.gguf \ --host 0.0.0.0 --port 11435 \ -c 131072 -ngl 99 \ -b 512 -ub 512 \ --no-mmap \ --main-gpu 0 \ --cont-batching \ --cache-type-k q4_0 --cache-type-v q4_0关键参数说明
参数 含义 为什么这么设 -c 131072上下文窗口 128K IQ4_XS 显存余量充足(~15.6 GB/24 GB) -ctk q4_0 -ctv q4_0KV 缓存 q4_0 ROCm 上 q4_0 速度等同 q8_0,体积减半 -fa 1Flash Attention 提升 prefill 50%+,仅 ROCm 可用 --tensor-split 0锁单卡 防 IO 延迟波动 --cont-batching连续批处理 多请求并发时有效 -b 512 -ub 512batch/ubatch 512 省显存,不影响速度 --no-mmap不进 page cache 防 X99 劣化 ️ Vulkan 注意事项-fa 1在 Vulkan 上不可用,会导致模型 fallback CPUVK_ICD_FILENAMES仅加载 AMD 驱动,3080 Ti 不会被拉入- 短 prompt 场景强烈推荐 Vulkan(decode +27%),长 prompt 切回 ROCm
适用场景
- 长文本写作:小说、论文、技术文档(128K 上下文)
- 文档处理:分析长报告、源代码库
- 聊天/日常使用:短 prompt 用 Vulkan 后端,长对话用 ROCm
- Hermes 后端:配合
start-comfyui-with-qwen.sh分卡并行
模式 C — MTP 自我投机解码(~40 tok/s)
性能(ROCm 7.14 + HSA_XNACK=1)
测试项 q4_0/q4_0 KV q8_0/q8_0 KV 变化 AR pp512 946 t/s 956 t/s -1% AR tg128 29.7 t/s 30.1 t/s -1.4% MTP cli Prompt 52.7 t/s 52.5 t/s 持平 MTP cli Generation 39.8 t/s 34.8 t/s +14.4% KV 体积 (vs bf16) 28.1% 53.1% -47% 关键发现:q4_0/q4_0 KV 在 MTP 模式下比 q8_0 更快!原因是 KV 带宽减少 47%,利好多 token 投机生成。Anbeeld 99.9% 尾部精度 89.84%(vs q8_0 的 94.61%),质量可接受。
MTP 接受率:~76%(预热后),短对话先跑 ngram 缓存填充期。
启动参数
export HSA_XNACK=1 export HSA_OVERRIDE_GFX_VERSION=11.0.0 export HIP_VISIBLE_DEVICES=GPU-8accafcdfee6fc4f export LD_LIBRARY_PATH=/opt/rocm-7.14-therock/lib:$LD_LIBRARY_PATH numactl --cpunodebind=0 --membind=0 /home/peter/llama.cpp/build-rocm-7.14/bin/llama-server \ -m /mnt/models/Qwen3.6/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf \ --host 0.0.0.0 --port 11435 \ -c 65536 \ -fa 1 \ --spec-type draft-mtp \ --spec-draft-n-max 3 \ --batch-size 2048 --ubatch-size 512 \ -ctk q4_0 -ctv q4_0 \ --no-mmap \ --tensor-split 0 \ --reasoning off \ --swa-checkpoints 0 \ --ctx-checkpoints 69 \ --repeat-penalty 1.1 --repeat-last-n 64 \ --temp 0.4 --top-p 0.95 --top-k 20关键参数说明
参数 含义 为什么必须加 --spec-type draft-mtpMTP 自我投机 核心特性 --spec-draft-n-max 3每次投机 3 个 token 甜点值 --reasoning off禁用思考模式 必须:否则 content 永远为空 --repeat-penalty 1.1 --repeat-last-n 64防重复循环 MTP 血训 --temp 0.4 --top-p 0.95 --top-k 20AGI 社区甜点采样 平衡创造性与准确度 --swa-checkpoints 0关闭 SWA checkpoint 根治 60K token re-prefill 卡顿 --ctx-checkpoints 69每 69 层 checkpoint 防长上下文 OOM VRAM 预算(q4_0 KV, 65K)
模型权重: 16.7 GB MTP head 开销: 0.4 GB q4_0 KV (65K): ~2.8 GB 合计峰值: ~19.9 GB / 24 GB(余量 4.1 GB)为什么不选 ROCm 7.2? 模式 C 的 MTP 模型在 ROCm 7.14 + XNACK=1 上 decode 快 11%(24.85 vs 22.15 t/s),且 7.2 上 server 模式启动就崩溃。
适用场景
- 日常聊天:Hermes 后端首选
- 编程助手:MTP 投机在代码生成中接受率很高
- 需要 API server 的场景:模式 A(DFlash)只有跑分工具,模式 C 有完整 OpenAI API
- 中长对话:预热后 MTP 接受率接近 100%
二、双卡模式 (D / E / F)
双卡用 GPU 0+1(XFX + Sapphire),自动停 ComfyUI。
总览
模式 速度 模型 量化 端口 引擎 D (layer) ~29 / 36.6 tok/s Huihui Q4_K_M Q4_K_M 18080 ROCm / Vulkan D (MTP) ~22.5 tok/s HauhauCS MTP Q4_K_P Q4_K_P 18080 ROCm layer E (Q8_0) ~23 tok/s DavidAU / ggml-org Q8_0 Q8_0 ★★★★★ 18081 ROCm layer F (tensor) 38-172 tok/s HauhauCS MTP Q4_K_P Q4_K_P 18080 CainSay fork
模式 D — 双卡 layer split(29 / 36.6 tok/s)
性能对比
后端 Prefill (pp512) Decode (tg128) 相对 ROCm 7.2 (q4_0) 888 t/s 22.5 t/s — ROCm 7.14 + XNACK (q4_0) 854 t/s 24.78 t/s tg +12% Vulkan (q4_0) 285 t/s (-68%) 36.6 t/s (+63%) 长生成最优 启动参数(ROCm Huihui Q4_K_M)
export HSA_OVERRIDE_GFX_VERSION=11.0.0 export LD_LIBRARY_PATH=/opt/rocm-7.2.0/lib:$LD_LIBRARY_PATH export HIP_VISIBLE_DEVICES=0,1 numactl --cpunodebind=0 --membind=0 llama-server \ -m /mnt/models/Qwen3.6/Huihui-Qwen3.6-27B-abliterated.Q4_K_M.gguf \ --host 0.0.0.0 --port 18080 \ -c 65536 -fa 1 \ --split-mode layer \ --cache-type-k q4_0 --cache-type-v q4_0 \ -b 1024 -ub 1024 \ --no-mmap启动参数(Vulkan,decode +63%)
export VK_ICD_FILENAMES=/usr/share/vulkan/icd.d/radeon_icd.json export LD_LIBRARY_PATH=/home/peter/llama.cpp/build-vulkan-new/bin:$LD_LIBRARY_PATH export HSA_OVERRIDE_GFX_VERSION=11.0.0 numactl --cpunodebind=0 --membind=0 /home/peter/llama.cpp/build-vulkan-new/bin/llama-server \ -m /mnt/models/Qwen3.6/Huihui-Qwen3.6-27B-abliterated.Q4_K_M.gguf \ --host 0.0.0.0 --port 18080 \ -c 65536 \ --split-mode layer \ --cache-type-k q4_0 --cache-type-v q4_0 \ -b 512 -ub 512 \ --no-mmap启动参数(双卡 MTP layer,HauhauCS MTP 模型)
export HIP_VISIBLE_DEVICES=GPU-16dc66d1309c376b,GPU-8accafcdfee6fc4f export NCCL_P2P_DISABLE=1 RCCL_P2P_DISABLE=1 export NCCL_PROTO=Simple export HSA_FORCE_FINE_GRAIN_PCIE=1 HSA_ENABLE_SDMA=0 numactl --cpunodebind=0 --membind=0 llama-server \ -m /mnt/models/Qwen3.6/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf \ --host 0.0.0.0 --port 18080 \ -c 65536 -fa 1 \ --split-mode layer --tensor-split 1,1 \ --spec-type draft-mtp --spec-draft-n-max 3 \ --cache-type-k q4_0 --cache-type-v q4_0 \ --no-mmap️ P2P 说明:双卡间 hipDeviceCanAccessPeer=0(不同 root port),必须设置NCCL_P2P_DISABLE=1+RCCL_P2P_DISABLE=1,否则 layer split 初始化死锁。适用场景
- 双卡稳定性首选:layer split 最成熟、最稳定
- Vulkan 长生成:如果 prompt 短(<2K tokens),Vulkan decode 比 ROCm 快 63%
- 中间过渡方案:从单卡升级到双卡的最佳起点
模式 E — 双卡 Q8_0 最高精度(~23 tok/s)
性能
- AR decode: ~23 tok/s(双卡 layer split)
- Prefill: 受 Q8_0 大模型(29.9G)和 X99 PCIe 3.0/魔改4.0 瓶颈限制
- 质量:★★★★★ — 社区公认 Qwen3.6-27B 最佳变体(DavidAU NEO-CODE-HERE)
启动参数
export HSA_OVERRIDE_GFX_VERSION=11.0.0 export LD_LIBRARY_PATH=/opt/rocm-7.2.0/lib:$LD_LIBRARY_PATH export HIP_VISIBLE_DEVICES=GPU-16dc66d1309c376b,GPU-8accafcdfee6fc4f export NCCL_PROTO=Simple export HSA_FORCE_FINE_GRAIN_PCIE=1 HSA_ENABLE_SDMA=0 numactl --cpunodebind=0 --membind=0 llama-server \ -m /mnt/models/Qwen3.6/Qwen3.6-27B-NEO-CODE-HERE-2T-OT-HIGH-Q8_0.gguf \ --host 0.0.0.0 --port 18081 \ -c 65536 -fa 1 \ --split-mode layer --tensor-split 1,1 \ --cache-type-k q8_0 --cache-type-v q8_0 \ -b 256 -ub 64 \ -fit off几个坑
-fit off:关闭 KV cache 大小自适应,防 OOM- 小 batch(256/64):Q8_0 KV 显存占用大,必须保守
-c 65536:131K 塞不下(双卡 48G 显存,Q8_0 模型 29.9G + Q8_0 KV 在 65K 下已近顶)
适用场景
- 代码任务:DavidAU 变体专为代码优化(2T token 预训练)
- 高质量输出场景:Q8_0 量化几乎没有精度损失
- 对比基准:用于和其他量化(Q4_K_M, IQ4_XS)做质量对比
- 必须双卡:Q8_0 29.9G 单卡 24GB 塞不下
模式 F — 双卡 tensor MTP+ngram(38-172 tok/s
)(编者注:这个模式跟大佬的性能差距打破了我对LLM大模型不吃CPU的刻板认知)
性能
场景 速度 说明 短对话(X99 DDR4) ~38 tok/s ngram 缓存初始化期 长文本(X99 预热后) ~43 tok/s MTP 接受率 ~86% 长文本(Ryzen 9700X 参考) 140-172 tok/s X99 DDR4 是瓶颈 基准 MTP gen 52.7 t/s (prompt) / 39.8 t/s (gen) 单卡 q4_0 KV 参考 启动参数
export HSA_OVERRIDE_GFX_VERSION=11.0.0 export LD_LIBRARY_PATH=/opt/rocm-7.2.0/lib:$LD_LIBRARY_PATH export HIP_VISIBLE_DEVICES=0,1 export NCCL_PROTO=Simple export HSA_FORCE_FINE_GRAIN_PCIE=1 HSA_ENABLE_SDMA=0 numactl --cpunodebind=0 --membind=0 /home/peter/llama-cainsay/build-hip/bin/llama-server \ -m /mnt/models/Qwen3.6/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf \ --host 0.0.0.0 --port 18080 \ -c 65536 -fa 1 \ --kv-unified \ --split-mode tensor --tensor-split 7,7 \ --cache-type-k q8_0 --cache-type-v q8_0 \ -b 1024 -ub 1024 \ --spec-type draft-mtp,ngram-mod,ngram-map-k4v \ --spec-draft-n-max 4 \ --spec-ngram-map-k4v-size-m 64 \ --repeat-penalty 1.1 --repeat-last-n 64 \ --reasoning off \ --temp 0.4 --top-p 0.95 --top-k 20 \ -np 1 \ --no-mmap关键参数说明
参数 含义 为什么 --split-mode tensor --tensor-split 7,7张量并行 双卡 7:7 平分层数 --spec-type draft-mtp,ngram-mod,ngram-map-k4v三重投机 MTP + ngram + map 链式投机 --spec-draft-n-max 4每步投机 4 token ngram 链式最大收益 --spec-ngram-map-k4v-size-m 64ngram map 大小 64M 缓存上下文匹配 --kv-unified统一 KV tensor split 必需 -np 1单批处理 必须:防 GGML 内存池崩溃 -ctk q8_0 -ctv q8_0KV q8_0 只能 q8_0:q4_0 触 tensor split GGML_ASSERT ️ 限制- 只能 q8_0 KV:
llama_params_fit未为SPLIT_MODE_TENSOR实现,q4_0 触发 GGML_ASSERT 崩溃 - SWA checkpoint bug:CainSay fork 和 upstream 一样,>60K context 后 SWA checkpoint 失效,触全量 re-prefill(2-3 分钟卡顿)
- 需要 CainSay fork(
fix/split-mode-tensor-quant-kv分支),upstream 没有 tensor split
适用场景
- 双卡最强输出:tensor split + MTP + ngram 三重投机,预热后极快
- 长文本生成:预热后稳定 ~43 tok/s(X99)、140+ tok/s(Ryzen)
- 适合能接受 60K 以内上下文的场景,超 60K 有 SWA bug
- 注意必须双卡(不能单卡 tensor split)
三、Vulkan 变体补充
变体 Decode 相对 ROCm 适用场景 B-Vk (单卡 IQ4_XS) 37.7 t/s +27% 短 prompt 聊天 D-layer-Vk (双卡 layer) 36.6 t/s +63% 长文本生成 B (ROCm) 29.7 t/s — 长 prompt D-layer (ROCm) 22.5 t/s — 极长 prompt Vulkan 特点:decode 恒定(不受 batch 大小影响),推荐
b=512 ub=512或b=1024 ub=512。 -fa 1不可用。️ q5_0/q4_1 KV 在 Vulkan 上可用(ROCm 不行)。编译后必须验证 --list-devices确实显示 GPU。Vulkan 选型策略
- prompt < 2K tokens → Vulkan(decode 快 27-63%)
- prompt > 2K tokens → ROCm(prefill 快 26-68%)
四、模式选择决策树
你想做什么? ├── 跑分/基准测试 → 模式 A (DFlash 84 tok/s) ├── 日常聊天/编程助手 │ ├── 短对话 → 模式 B-Vk (Vulkan 37.7 t/s) 或 模式 C (MTP 40 t/s) │ └── 长对话 → 模式 B ROCm (29.7 t/s, 131K ctx) ├── 长文本写作/文档处理 → 模式 B (IQ4_XS 131K) ├── 代码/高质量输出 → 模式 E (Q8_0 ★★★★★) ├── 双卡吞吐最大化 │ ├── 60K 以内上下文 → 模式 F (tensor MTP+ngram 🏆) │ └── 稳定优先 → 模式 D (layer split) └── 和 ComfyUI 并行运行 └── start-comfyui-with-qwen.sh (默认模式 B)
五、性能测试方法论
所有数据来自 llama-bench 和 llama-server 实测,测试条件:
- 模型:Qwen3.6-27B 各量化变体
- 后端:ROCm 7.2.0 / 7.14-TheRock / Vulkan
- CPU:Intel Xeon E5-2680 v4 (DDR4 2400)
- GPU:双路 7900 XTX (XFX MERC + Sapphire Pulse)
- NVMe SSD 加载模型,非 mmap
测试脚本和详细方法论见
references/rocm-comparison-testing.md和references/cross-backend-parameter-testing-20260619.md
六、更新日志
日期 更新内容 2026-06-19 q4_0/q4_0 推翻旧结论:MTP 模式 +14.4%;模式 C 更新 ROCm 7.14 + XNACK=1 2026-06-19 Vulkan 回归测试:双卡 decode +63%;q5_0/q4_1 KV Vulkan 可用 2026-06-19 全局推荐 --swa-checkpoints 0+--ctx-checkpoints 692026-06-19 新增模式 F (tensor MTP+ngram) 和 CainSay fork 基准 2026-06-16 初始版本:6 大模式 + 命名纪律确立
有问题欢迎交流!硬件环境(双 7900 XTX + X99)相近的兄弟可以直接抄参数。🫡
至此,7900 XTX 调教/折腾/学习篇到暂告一段落了,设备要开始投入进去找路子赚钱了,感谢各位的关注~!!!
以下是模式C运行时的截图
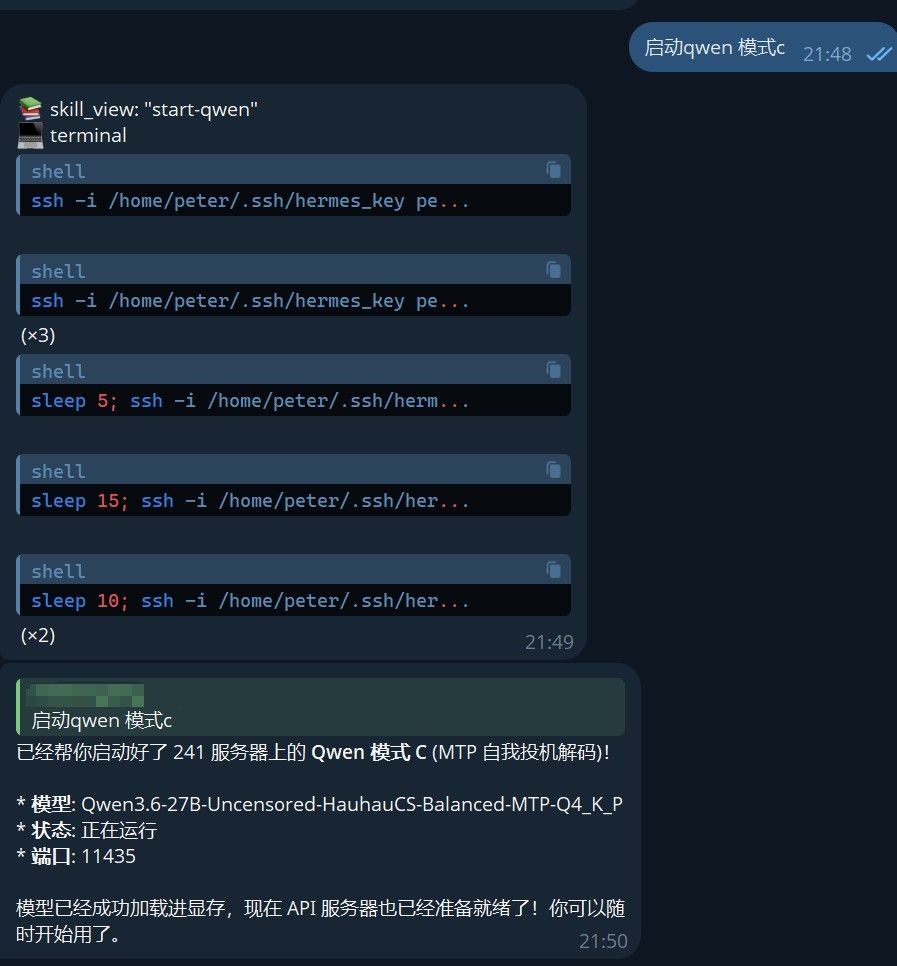
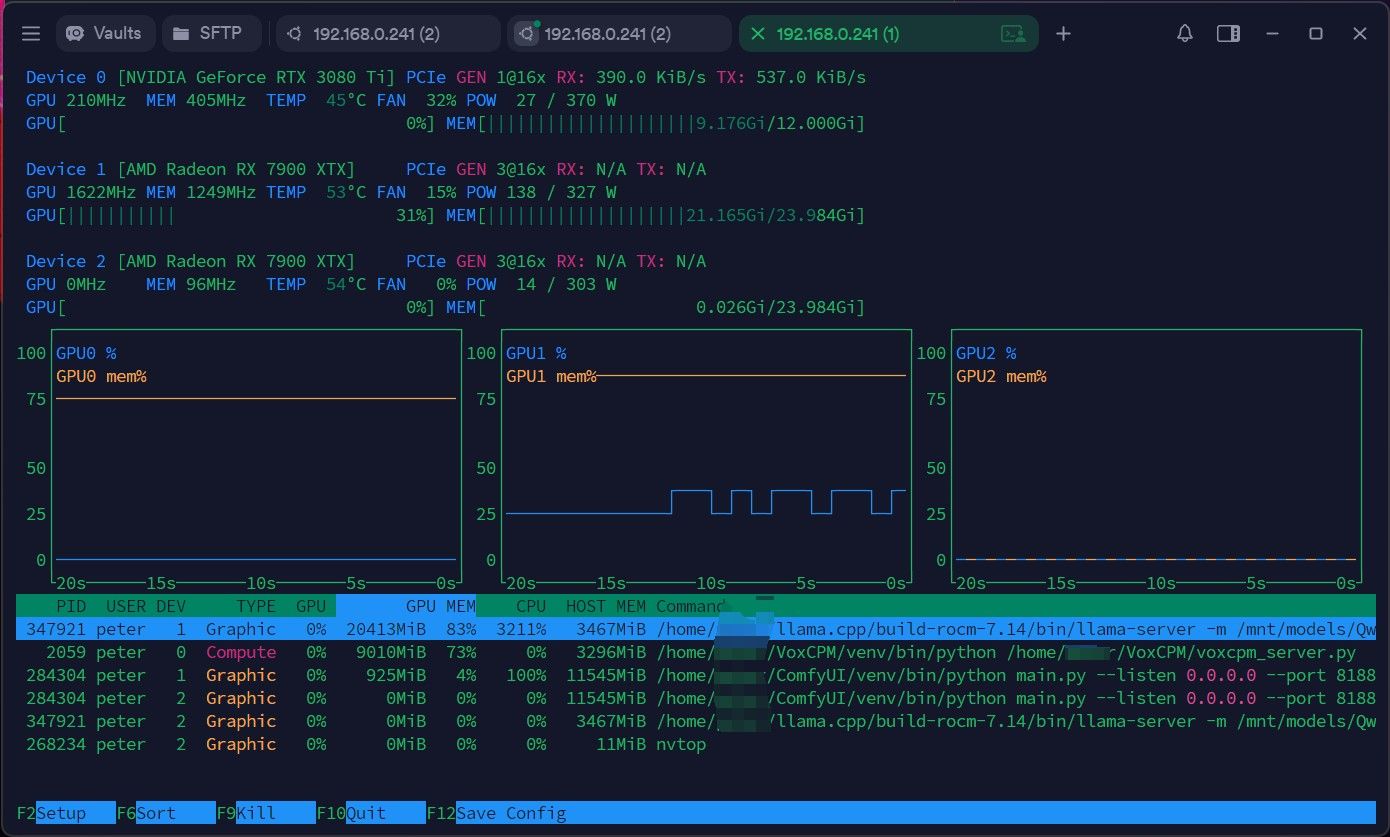


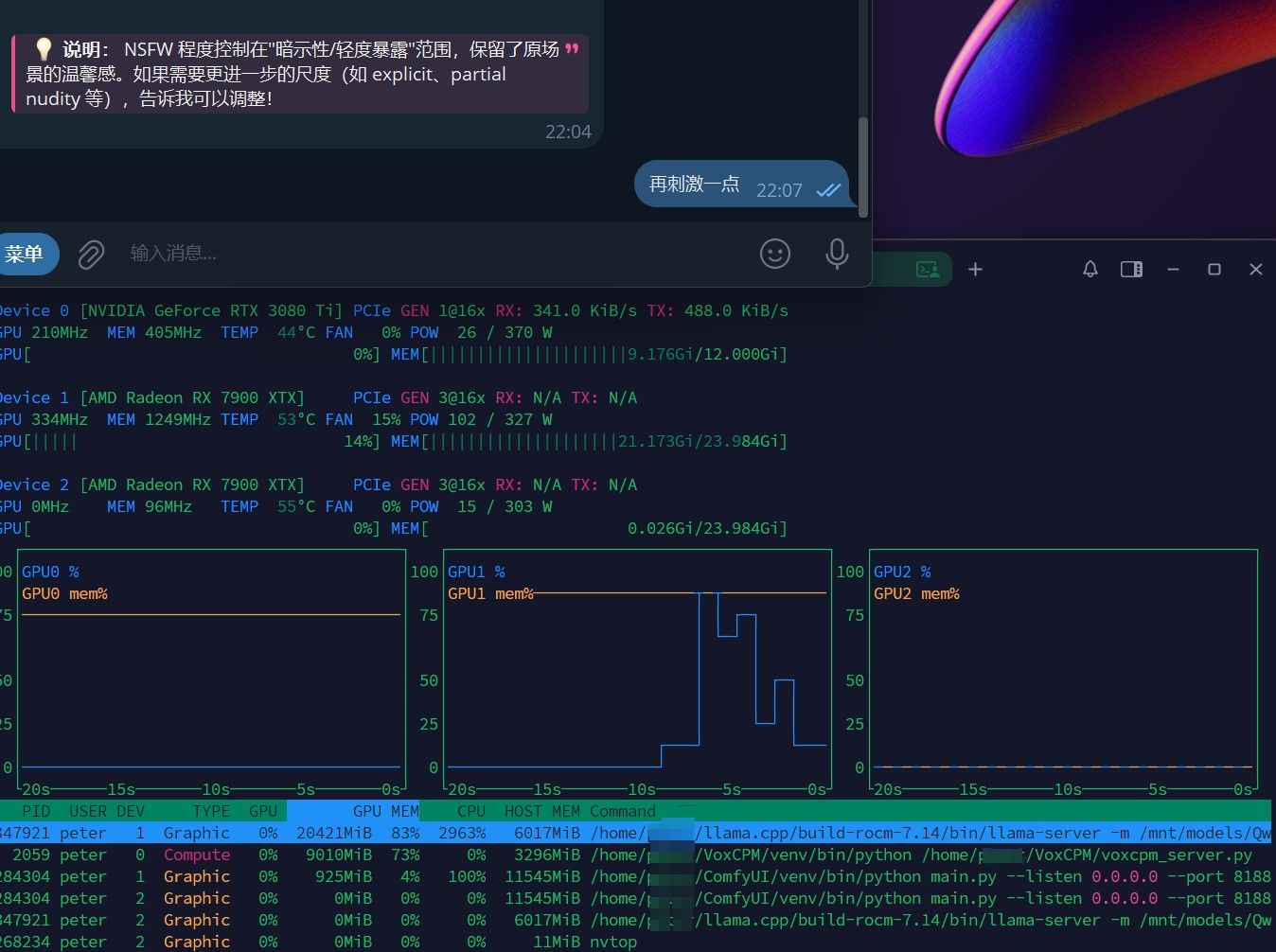
免责声明:
以下截图仅为展示模型性能,非搞黄色
-
,系统 取消固定了此主题
-
