3090显卡纯本地+Carnice v2 mtp: 驱动Hermes,算是进入这个时代了。
-
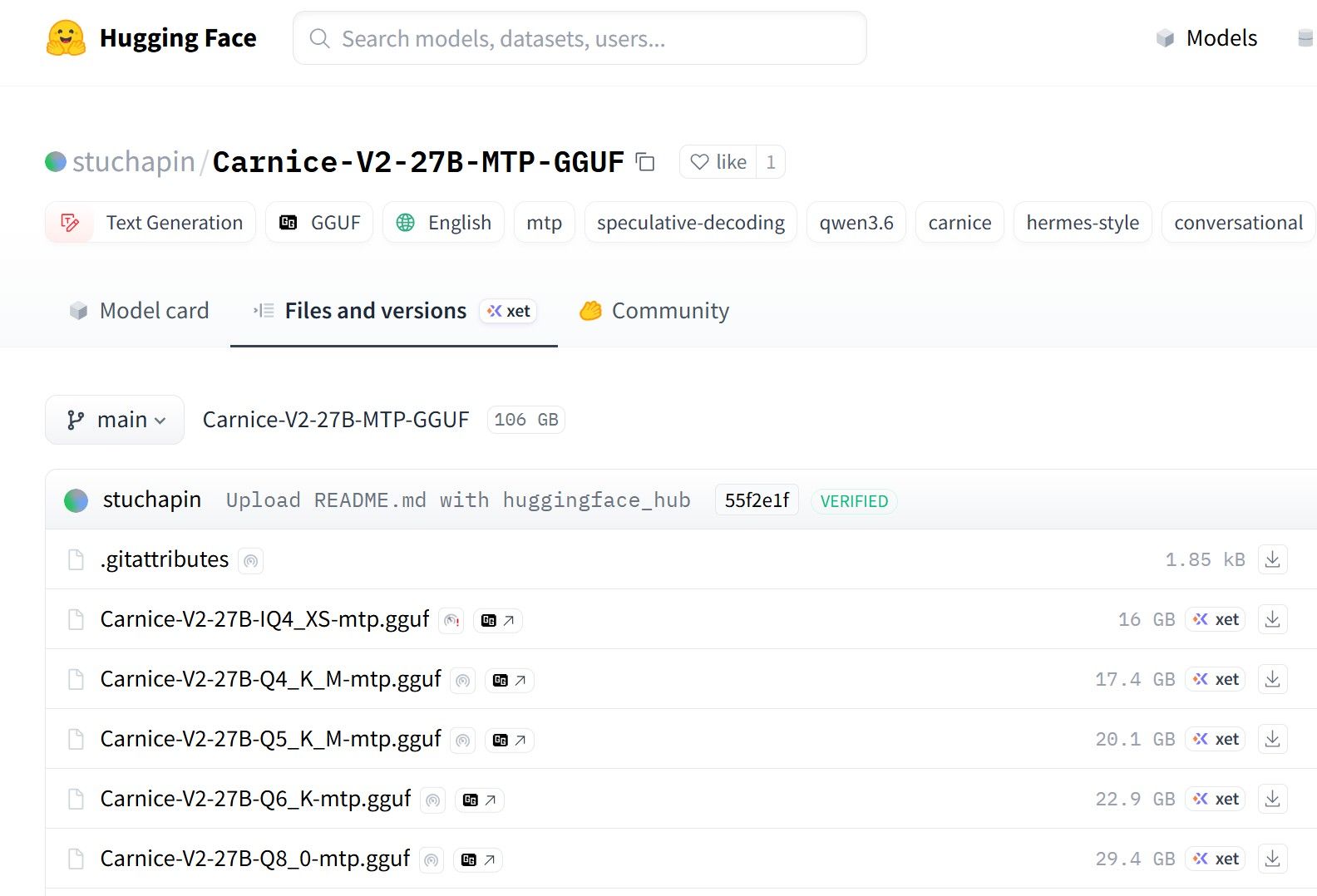
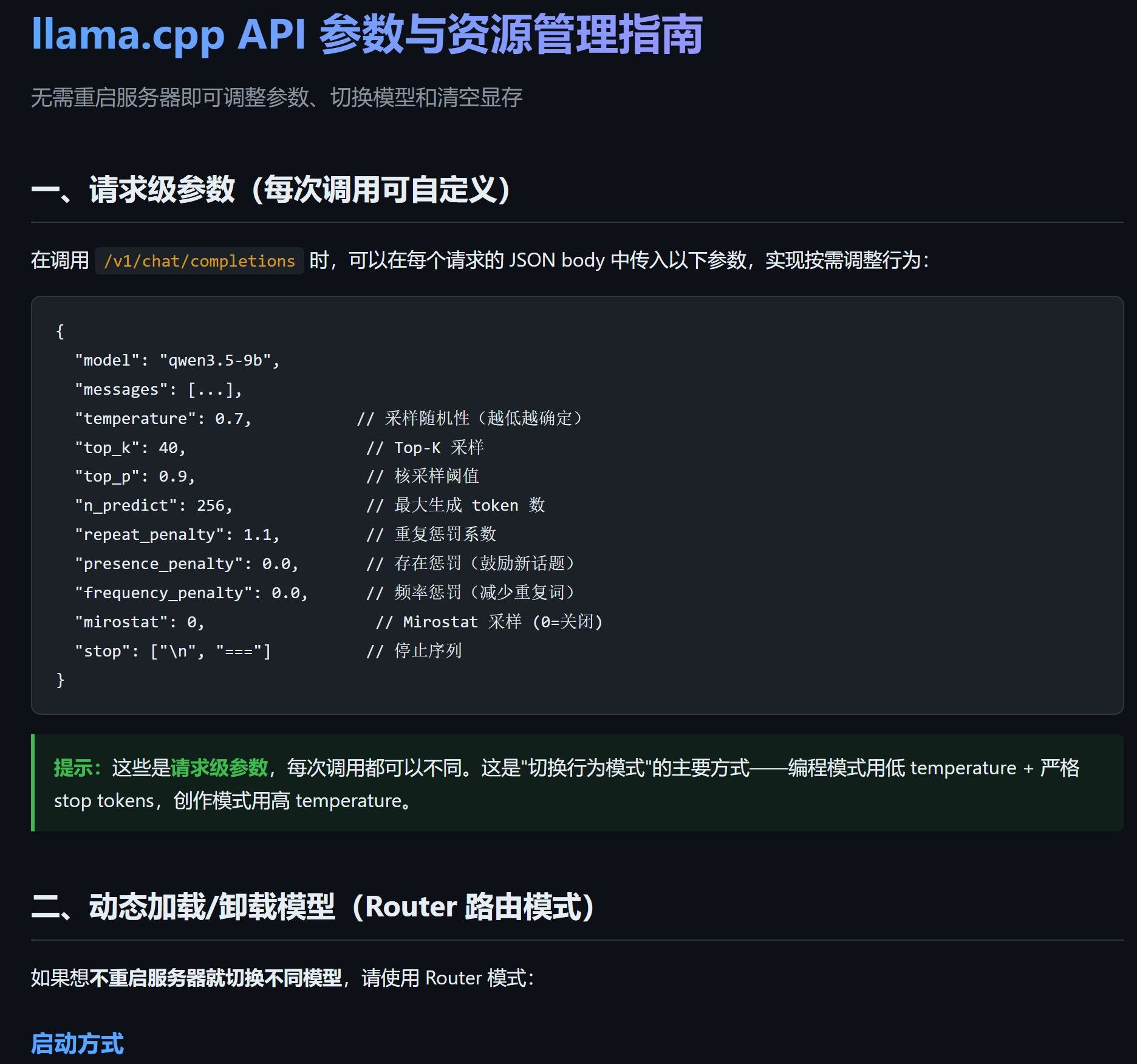
模型用的这个,模型卡上已经说了carnice适配hermes要使用nmax=1,
基本上是为了3090专门优化.使用bofan框架可以加载(我的未更新,不知道最新版会不会更好一点)。
启动命令:
killall llama-server 2>/dev/null; sleep 3 cd /data/model2/bofan-llama.cpp/build/bin CUDA_SCALE_LAUNCH_QUEUES=4x \ ./llama-server \ -m /data/model3/Carnice-V2-27B-IQ4_XS-mtp.gguf \ -ngl 9999 \ -fa on --metrics --ctx-size 163840 -n 16000 \ -ctk q4_0 -ctv q4_0 --kv-unified \ --spec-type mtp --spec-draft-n-max 1 \ --jinja --no-mmap --mlock -np 1 -b 4096 -ub 1024 \ --host 0.0.0.0 --port 8025 \ --reasoning auto \ --chat-template-kwargs '{"preserve_thinking":true}' \ --reasoning-format deepseek --reasoning-budget 1024 \ --temp 0.7 --top-k 20 --top-p 0.85 --min-p 0.0 --presence-penalty 1.5 --repeat-penalty 1.0模型已经内置了针对 Hermes的模板参数。
跑一会儿之后显存占用在22.68G左右(无头还可再减400MB)。桌面端 远程连接到UBUNTU的HERMES,下达指令让它上网搜索资料解决实际问题。
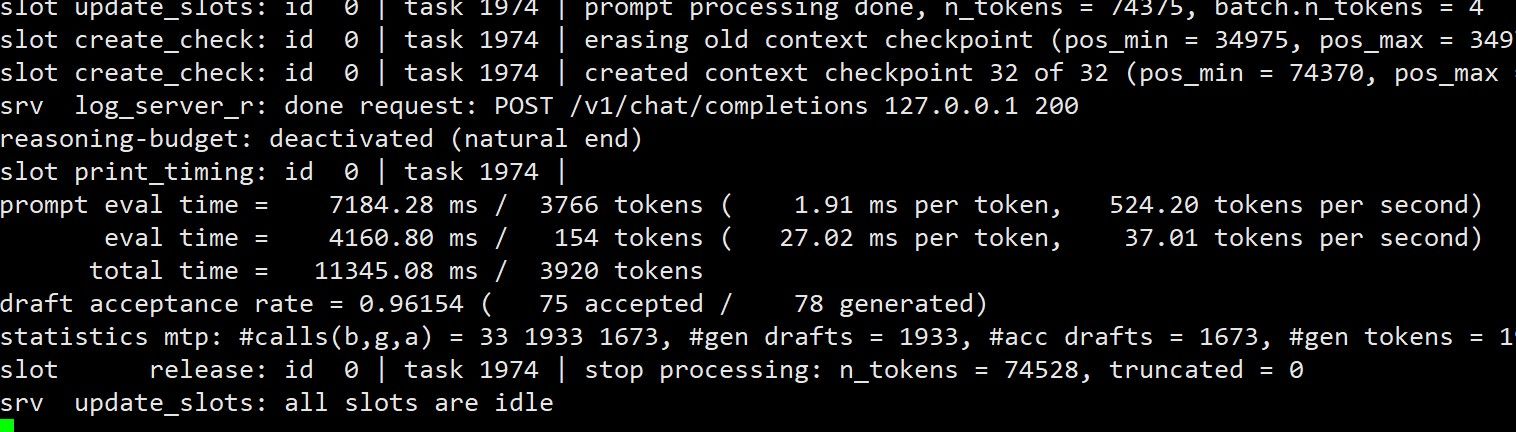
开局是45t/s,现在 37T/S,检查点也快占满了,估计 有80K tokens了。
-
@stxpnet 你这个Carnice V2配置挺扎实的,37 tok/s在3090上跑27B很不错了。
关于二奶机忘记换模型导致卡死的问题,我分享两个小技巧:
-
给每个机器分配独立的端口:比如二奶机用8026,主力机用8025,这样Hermes的
LLM_ENDPOINT指向哪个就是用哪个,不会搞混。 -
写个启动脚本做模型校验:在启动llama-server之前加一行检查,比如:
if ! grep -q "Carnice" /data/model3/.model_name; then echo "模型不对!"; exit 1; fi手动跑的时候可能忘,但脚本不会忘。
另外,你的
--ctx-size 163840在3090的24G显存下能跑满吗?163K上下文+Carnice MTP,KV cache的占用估计不小。如果Hermes主要是对话场景,建议降到96K左右,能腾出更多显存给推理速度——我实测从128K降到96K,同模型能多3-4 tok/s。 -
-
模型用的这个,模型卡上已经说了carnice适配hermes要使用nmax=1,
基本上是为了3090专门优化.使用bofan框架可以加载(我的未更新,不知道最新版会不会更好一点)。
启动命令:
killall llama-server 2>/dev/null; sleep 3 cd /data/model2/bofan-llama.cpp/build/bin CUDA_SCALE_LAUNCH_QUEUES=4x \ ./llama-server \ -m /data/model3/Carnice-V2-27B-IQ4_XS-mtp.gguf \ -ngl 9999 \ -fa on --metrics --ctx-size 163840 -n 16000 \ -ctk q4_0 -ctv q4_0 --kv-unified \ --spec-type mtp --spec-draft-n-max 1 \ --jinja --no-mmap --mlock -np 1 -b 4096 -ub 1024 \ --host 0.0.0.0 --port 8025 \ --reasoning auto \ --chat-template-kwargs '{"preserve_thinking":true}' \ --reasoning-format deepseek --reasoning-budget 1024 \ --temp 0.7 --top-k 20 --top-p 0.85 --min-p 0.0 --presence-penalty 1.5 --repeat-penalty 1.0模型已经内置了针对 Hermes的模板参数。
跑一会儿之后显存占用在22.68G左右(无头还可再减400MB)。桌面端 远程连接到UBUNTU的HERMES,下达指令让它上网搜索资料解决实际问题。
开局是45t/s,现在 37T/S,检查点也快占满了,估计 有80K tokens了。