
看目前這社區越來越多人買7900XTX了,大家為了一個爽度token無限發與反應速度,這幾天折騰的過程分享給大家(win11+vulkan & ubuntu +rocm)
-
Vulkan 版在 Linux 上 MTP 幾乎無效(GitHub issue #22842)
有效果啊,接受率70%+
-
@AGI 不知道耶 我怎麼測速度都起不來,,cc直接放棄,但我在win11+vulkan明顯可以 我的AI 可能累了,你有作業可以抄嗎?
/usr/local/bin/llama-server \ -m ./models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q5_K_P.gguf \ --mmproj ./models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf \ -c 131072 \ --parallel 1 \ -b 2048 \ -ub 512 \ -fa 1 \ -ngl 99 \ -t 16 \ --spec-type draft-mtp \ --cache-type-k q5_0 \ --cache-type-v q4_1 \ --no-mmap \ --temp 0.4 \ --spec-draft-n-max 3 \ --top-p 0.95 \ --top-k 20 \ --host 0.0.0.0 \ --port 8080 \ --tools allroot@ailab:~# llama-server --version version: 236 (d5376cf5d) built with GNU 13.3.0 for Linux x86_64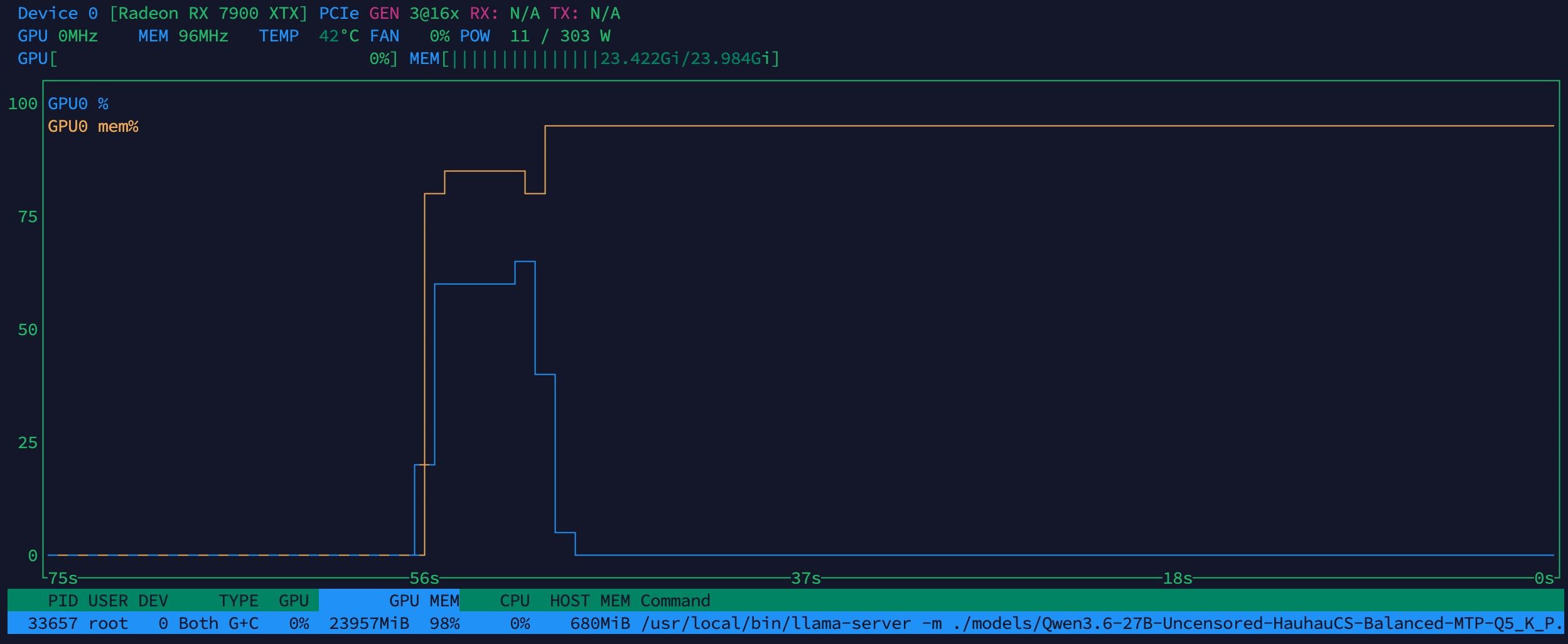
-
@AGI 不知道耶 我怎麼測速度都起不來,,cc直接放棄,但我在win11+vulkan明顯可以 我的AI 可能累了,你有作業可以抄嗎?
@CHIA-AN-YANG llama-server.service
/home/myclaw/Downloads/llama.cpp/vulkan/bin/llama-server -m /media/myclaw/SYS/VM/llm/Qwen3.6-27B-Q4_K_M-mtp.gguf --alias qwen3.6-27b --spec-type draft-mtp --spec-draft-n-max 3 --cache-type-k q4_0 --cache-type-v q4_0 -np 1 -c 131072 --temp 0.7 --top-k 20 -ngl 99 --port 8080 --host 0.0.0.0 -fa 1 -ub 256 -fit off -
/usr/local/bin/llama-server \ -m ./models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q5_K_P.gguf \ --mmproj ./models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf \ -c 131072 \ --parallel 1 \ -b 2048 \ -ub 512 \ -fa 1 \ -ngl 99 \ -t 16 \ --spec-type draft-mtp \ --cache-type-k q5_0 \ --cache-type-v q4_1 \ --no-mmap \ --temp 0.4 \ --spec-draft-n-max 3 \ --top-p 0.95 \ --top-k 20 \ --host 0.0.0.0 \ --port 8080 \ --tools allroot@ailab:~# llama-server --version version: 236 (d5376cf5d) built with GNU 13.3.0 for Linux x86_64 -
,系统 取消固定了此主题
-
@chia-an-yang @agi Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q5_K_P.gguf ,请问你们这个模型是在哪下载的,现在hauhuacs的huggingface的repo里面 已经没有这个模型了。google也搜不到。
@nami-ryuu 通常都是讓ai agent代勞了,,比較快
-
@agi 您好!我也是用7900xtx显卡,使用
/usr/local/bin/llama-server
-m ./models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q5_K_P.gguf
--mmproj ./models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf
-c 131072
--parallel 1
-b 2048
-ub 512
-fa 1
-ngl 99
-t 16
--spec-type draft-mtp
--cache-type-k q5_0
--cache-type-v q4_1
--no-mmap
--temp 0.4
--spec-draft-n-max 3
--top-p 0.95
--top-k 20
--host 0.0.0.0
--port 8080
--tools all启动llama.cpp, 但是遇到oom的错误如下:
/usr/local/bin/llama-server -m ./models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q5_K_P.gguf --mmproj ./models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf -c 131072 --parallel 1 -b 2048 -ub 512 -fa 1 -ngl 99 -t 16 --spec-type draft-mtp --cache-type-k q5_0 --cache-type-v q4_1 --no-mmap --temp 0.4 --spec-draft-n-max 3 --top-p 0.95 --top-k 20 --host 0.0.0.0 --port 8080 --tools all
0.00.014.095 I log_info: verbosity = 3 (adjust with the-lv NCLI arg)
0.00.014.097 I device_info:
0.00.014.112 I - ROCm0 : Radeon RX 7900 XTX (24560 MiB, 24524 MiB free)
0.00.014.154 I - ROCm1 : AMD Radeon Graphics (47068 MiB, 89322 MiB free)
0.00.014.156 I - CPU : AMD Ryzen 7 9700X 8-Core Processor (94137 MiB, 94137 MiB free)
0.00.014.207 I system_info: n_threads = 16 (n_threads_batch = 16) / 16 | ROCm : NO_VMM = 1 | PEER_MAX_BATCH_SIZE = 128 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX_VNNI = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | BMI2 = 1 | AVX512 = 1 | AVX512_VBMI = 1 | AVX512_VNNI = 1 | AVX512_BF16 = 1 | LLAMAFILE = 1 | OPENMP = 1 | REPACK = 1 |
0.00.014.234 I srv init: running without SSL
0.00.014.273 I srv init: using 15 threads for HTTP server
0.00.014.473 W srv llama_server: -----------------
0.00.014.474 W srv llama_server: Built-in tools are enabled, do not expose server to untrusted environments
0.00.014.474 W srv llama_server: This feature is EXPERIMENTAL and may be changed in the future
0.00.014.474 W srv llama_server: -----------------
0.00.014.481 I srv start: binding port with default address family
0.00.015.619 I srv llama_server: loading model
0.00.015.661 I srv load_model: loading model './models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q5_K_P.gguf'
0.00.052.136 I srv load_model: [mtmd] estimated worst-case memory usage of mmproj is 1157.64 MiB (took 36.45 ms)
0.00.295.983 I srv load_model: [spec] estimated memory usage of MTP context is 708.02 MiB
0.00.296.004 I common_init_result: fitting params to device memory ...
0.00.296.004 I common_init_result: (for bugs during this step try to reproduce them with -fit off, or provide --verbose logs if the bug only occurs with -fit on)
0.00.517.578 W common_fit_params: failed to fit params to free device memory: n_gpu_layers already set by user to 99, abort
0.01.810.285 W llama_context: n_ctx_seq (131072) < n_ctx_train (262144) -- the full capacity of the model will not be utilized
0.01.838.385 I common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
0.01.916.196 I srv load_model: creating MTP draft context against the target model './models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q5_K_P.gguf'
0.01.916.222 W llama_context: n_ctx_seq (131072) < n_ctx_train (262144) -- the full capacity of the model will not be utilized
0.01.932.754 W load_hparams: Qwen-VL models require at minimum 1024 image tokens to function correctly on grounding tasks
0.01.932.756 W load_hparams: if you encounter problems with accuracy, try adding --image-min-tokens 1024
0.01.932.756 W load_hparams: more info: https://github.com/ggml-org/llama.cpp/issues/168420.01.933.558 E ggml_backend_cuda_buffer_type_alloc_buffer: allocating 884.62 MiB on device 0: cudaMalloc failed: out of memory
0.01.933.561 E alloc_tensor_range: failed to allocate ROCm0 buffer of size 927588992
/home/liubo/llama.cpp/ggml/src/ggml-backend.cpp:179: GGML_ASSERT(buffer) failed
[New LWP 459888]
[New LWP 459887]
[New LWP 459886]
[New LWP 459885]
[New LWP 459884]
[New LWP 459883]
[New LWP 459882]
[New LWP 459881]
[New LWP 459880]
[New LWP 459879]
[New LWP 459878]
[New LWP 459877]
[New LWP 459876]
[New LWP 459875]
[New LWP 459874]
[New LWP 459717]
[New LWP 459716]
[New LWP 459715]
[New LWP 459714]
[New LWP 459713]
[New LWP 459712]
[New LWP 459711]
[New LWP 459710]
[New LWP 459709]
[New LWP 459708]
[New LWP 459707]
[New LWP 459706]
[New LWP 459705]
[New LWP 459704]
[New LWP 459703]
[New LWP 459702]
[New LWP 459700]
[New LWP 459699]
[New LWP 459696]This GDB supports auto-downloading debuginfo from the following URLs:
https://debuginfod.ubuntu.com
Enable debuginfod for this session? (y or [n]) [answered N; input not from terminal]
Debuginfod has been disabled.
To make this setting permanent, add 'set debuginfod enabled off' to .gdbinit.
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
0x0000762b61110813 in __GI___wait4 (pid=459889, stat_loc=0x0, options=0, usage=0x0) at ../sysdeps/unix/sysv/linux/wait4.c:30
warning: 30 ../sysdeps/unix/sysv/linux/wait4.c: No such file or directory
#0 0x0000762b61110813 in __GI___wait4 (pid=459889, stat_loc=0x0, options=0, usage=0x0) at ../sysdeps/unix/sysv/linux/wait4.c:30
30 in ../sysdeps/unix/sysv/linux/wait4.c
#1 0x0000762b6134e663 in ggml_print_backtrace () from /home/liubo/llama.cpp/build/bin/libggml-base.so.0
#2 0x0000762b6134e80b in ggml_abort () from /home/liubo/llama.cpp/build/bin/libggml-base.so.0
#3 0x0000762b61367611 in ggml_backend_buffer_set_usage () from /home/liubo/llama.cpp/build/bin/libggml-base.so.0
#4 0x0000762b617a75e8 in clip_model_loader::load_tensors(clip_ctx&) () from /home/liubo/llama.cpp/build/bin/libmtmd.so.0
#5 0x0000762b61795dcd in clip_init(char const*, clip_context_params) () from /home/liubo/llama.cpp/build/bin/libmtmd.so.0
#6 0x0000762b6170987c in mtmd_context::mtmd_context(char const*, llama_model const*, mtmd_context_params const&, bool) () from /home/liubo/llama.cpp/build/bin/libmtmd.so.0
#7 0x0000762b61703211 in mtmd_init_from_file () from /home/liubo/llama.cpp/build/bin/libmtmd.so.0
#8 0x0000762b619aab79 in server_context_impl::load_model(common_params&) () from /home/liubo/llama.cpp/build/bin/libllama-server-impl.so
#9 0x0000762b618e4a48 in llama_server(int, char**) () from /home/liubo/llama.cpp/build/bin/libllama-server-impl.so
#10 0x0000762b6102a1ca in __libc_start_call_main (main=main@entry=0x5e6c5fa22270 <main>, argc=argc@entry=40, argv=argv@entry=0x7fffc3eb01c8) at ../sysdeps/nptl/libc_start_call_main.h:58
warning: 58 ../sysdeps/nptl/libc_start_call_main.h: No such file or directory
#11 0x0000762b6102a28b in __libc_start_main_impl (main=0x5e6c5fa22270 <main>, argc=40, argv=0x7fffc3eb01c8, init=<optimized out>, fini=<optimized out>, rtld_fini=<optimized out>, stack_end=0x7fffc3eb01b8) at ../csu/libc-start.c:360
warning: 360 ../csu/libc-start.c: No such file or directory
#12 0x00005e6c5fa222a5 in _start ()
[Inferior 1 (process 459658) detached]
Aborted (core dumped)请问是我哪步弄错了吗?我问了gemini,它让我减少上下文,q4我可运行,占用21.5g,我加上q4和q5模型的权重差,我大概差1g的内存。我们几乎是一样的环境。感谢!!
-
@chia-an-yang @agi Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q5_K_P.gguf ,请问你们这个模型是在哪下载的,现在hauhuacs的huggingface的repo里面 已经没有这个模型了。google也搜不到。
-
@agi 您好!我也是用7900xtx显卡,使用
/usr/local/bin/llama-server
-m ./models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q5_K_P.gguf
--mmproj ./models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf
-c 131072
--parallel 1
-b 2048
-ub 512
-fa 1
-ngl 99
-t 16
--spec-type draft-mtp
--cache-type-k q5_0
--cache-type-v q4_1
--no-mmap
--temp 0.4
--spec-draft-n-max 3
--top-p 0.95
--top-k 20
--host 0.0.0.0
--port 8080
--tools all启动llama.cpp, 但是遇到oom的错误如下:
/usr/local/bin/llama-server -m ./models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q5_K_P.gguf --mmproj ./models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf -c 131072 --parallel 1 -b 2048 -ub 512 -fa 1 -ngl 99 -t 16 --spec-type draft-mtp --cache-type-k q5_0 --cache-type-v q4_1 --no-mmap --temp 0.4 --spec-draft-n-max 3 --top-p 0.95 --top-k 20 --host 0.0.0.0 --port 8080 --tools all
0.00.014.095 I log_info: verbosity = 3 (adjust with the-lv NCLI arg)
0.00.014.097 I device_info:
0.00.014.112 I - ROCm0 : Radeon RX 7900 XTX (24560 MiB, 24524 MiB free)
0.00.014.154 I - ROCm1 : AMD Radeon Graphics (47068 MiB, 89322 MiB free)
0.00.014.156 I - CPU : AMD Ryzen 7 9700X 8-Core Processor (94137 MiB, 94137 MiB free)
0.00.014.207 I system_info: n_threads = 16 (n_threads_batch = 16) / 16 | ROCm : NO_VMM = 1 | PEER_MAX_BATCH_SIZE = 128 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX_VNNI = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | BMI2 = 1 | AVX512 = 1 | AVX512_VBMI = 1 | AVX512_VNNI = 1 | AVX512_BF16 = 1 | LLAMAFILE = 1 | OPENMP = 1 | REPACK = 1 |
0.00.014.234 I srv init: running without SSL
0.00.014.273 I srv init: using 15 threads for HTTP server
0.00.014.473 W srv llama_server: -----------------
0.00.014.474 W srv llama_server: Built-in tools are enabled, do not expose server to untrusted environments
0.00.014.474 W srv llama_server: This feature is EXPERIMENTAL and may be changed in the future
0.00.014.474 W srv llama_server: -----------------
0.00.014.481 I srv start: binding port with default address family
0.00.015.619 I srv llama_server: loading model
0.00.015.661 I srv load_model: loading model './models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q5_K_P.gguf'
0.00.052.136 I srv load_model: [mtmd] estimated worst-case memory usage of mmproj is 1157.64 MiB (took 36.45 ms)
0.00.295.983 I srv load_model: [spec] estimated memory usage of MTP context is 708.02 MiB
0.00.296.004 I common_init_result: fitting params to device memory ...
0.00.296.004 I common_init_result: (for bugs during this step try to reproduce them with -fit off, or provide --verbose logs if the bug only occurs with -fit on)
0.00.517.578 W common_fit_params: failed to fit params to free device memory: n_gpu_layers already set by user to 99, abort
0.01.810.285 W llama_context: n_ctx_seq (131072) < n_ctx_train (262144) -- the full capacity of the model will not be utilized
0.01.838.385 I common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
0.01.916.196 I srv load_model: creating MTP draft context against the target model './models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q5_K_P.gguf'
0.01.916.222 W llama_context: n_ctx_seq (131072) < n_ctx_train (262144) -- the full capacity of the model will not be utilized
0.01.932.754 W load_hparams: Qwen-VL models require at minimum 1024 image tokens to function correctly on grounding tasks
0.01.932.756 W load_hparams: if you encounter problems with accuracy, try adding --image-min-tokens 1024
0.01.932.756 W load_hparams: more info: https://github.com/ggml-org/llama.cpp/issues/168420.01.933.558 E ggml_backend_cuda_buffer_type_alloc_buffer: allocating 884.62 MiB on device 0: cudaMalloc failed: out of memory
0.01.933.561 E alloc_tensor_range: failed to allocate ROCm0 buffer of size 927588992
/home/liubo/llama.cpp/ggml/src/ggml-backend.cpp:179: GGML_ASSERT(buffer) failed
[New LWP 459888]
[New LWP 459887]
[New LWP 459886]
[New LWP 459885]
[New LWP 459884]
[New LWP 459883]
[New LWP 459882]
[New LWP 459881]
[New LWP 459880]
[New LWP 459879]
[New LWP 459878]
[New LWP 459877]
[New LWP 459876]
[New LWP 459875]
[New LWP 459874]
[New LWP 459717]
[New LWP 459716]
[New LWP 459715]
[New LWP 459714]
[New LWP 459713]
[New LWP 459712]
[New LWP 459711]
[New LWP 459710]
[New LWP 459709]
[New LWP 459708]
[New LWP 459707]
[New LWP 459706]
[New LWP 459705]
[New LWP 459704]
[New LWP 459703]
[New LWP 459702]
[New LWP 459700]
[New LWP 459699]
[New LWP 459696]This GDB supports auto-downloading debuginfo from the following URLs:
https://debuginfod.ubuntu.com
Enable debuginfod for this session? (y or [n]) [answered N; input not from terminal]
Debuginfod has been disabled.
To make this setting permanent, add 'set debuginfod enabled off' to .gdbinit.
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
0x0000762b61110813 in __GI___wait4 (pid=459889, stat_loc=0x0, options=0, usage=0x0) at ../sysdeps/unix/sysv/linux/wait4.c:30
warning: 30 ../sysdeps/unix/sysv/linux/wait4.c: No such file or directory
#0 0x0000762b61110813 in __GI___wait4 (pid=459889, stat_loc=0x0, options=0, usage=0x0) at ../sysdeps/unix/sysv/linux/wait4.c:30
30 in ../sysdeps/unix/sysv/linux/wait4.c
#1 0x0000762b6134e663 in ggml_print_backtrace () from /home/liubo/llama.cpp/build/bin/libggml-base.so.0
#2 0x0000762b6134e80b in ggml_abort () from /home/liubo/llama.cpp/build/bin/libggml-base.so.0
#3 0x0000762b61367611 in ggml_backend_buffer_set_usage () from /home/liubo/llama.cpp/build/bin/libggml-base.so.0
#4 0x0000762b617a75e8 in clip_model_loader::load_tensors(clip_ctx&) () from /home/liubo/llama.cpp/build/bin/libmtmd.so.0
#5 0x0000762b61795dcd in clip_init(char const*, clip_context_params) () from /home/liubo/llama.cpp/build/bin/libmtmd.so.0
#6 0x0000762b6170987c in mtmd_context::mtmd_context(char const*, llama_model const*, mtmd_context_params const&, bool) () from /home/liubo/llama.cpp/build/bin/libmtmd.so.0
#7 0x0000762b61703211 in mtmd_init_from_file () from /home/liubo/llama.cpp/build/bin/libmtmd.so.0
#8 0x0000762b619aab79 in server_context_impl::load_model(common_params&) () from /home/liubo/llama.cpp/build/bin/libllama-server-impl.so
#9 0x0000762b618e4a48 in llama_server(int, char**) () from /home/liubo/llama.cpp/build/bin/libllama-server-impl.so
#10 0x0000762b6102a1ca in __libc_start_call_main (main=main@entry=0x5e6c5fa22270 <main>, argc=argc@entry=40, argv=argv@entry=0x7fffc3eb01c8) at ../sysdeps/nptl/libc_start_call_main.h:58
warning: 58 ../sysdeps/nptl/libc_start_call_main.h: No such file or directory
#11 0x0000762b6102a28b in __libc_start_main_impl (main=0x5e6c5fa22270 <main>, argc=40, argv=0x7fffc3eb01c8, init=<optimized out>, fini=<optimized out>, rtld_fini=<optimized out>, stack_end=0x7fffc3eb01b8) at ../csu/libc-start.c:360
warning: 360 ../csu/libc-start.c: No such file or directory
#12 0x00005e6c5fa222a5 in _start ()
[Inferior 1 (process 459658) detached]
Aborted (core dumped)请问是我哪步弄错了吗?我问了gemini,它让我减少上下文,q4我可运行,占用21.5g,我加上q4和q5模型的权重差,我大概差1g的内存。我们几乎是一样的环境。感谢!!
-
@agi 您好!我也是用7900xtx显卡,使用
/usr/local/bin/llama-server
-m ./models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q5_K_P.gguf
--mmproj ./models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf
-c 131072
--parallel 1
-b 2048
-ub 512
-fa 1
-ngl 99
-t 16
--spec-type draft-mtp
--cache-type-k q5_0
--cache-type-v q4_1
--no-mmap
--temp 0.4
--spec-draft-n-max 3
--top-p 0.95
--top-k 20
--host 0.0.0.0
--port 8080
--tools all启动llama.cpp, 但是遇到oom的错误如下:
/usr/local/bin/llama-server -m ./models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q5_K_P.gguf --mmproj ./models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf -c 131072 --parallel 1 -b 2048 -ub 512 -fa 1 -ngl 99 -t 16 --spec-type draft-mtp --cache-type-k q5_0 --cache-type-v q4_1 --no-mmap --temp 0.4 --spec-draft-n-max 3 --top-p 0.95 --top-k 20 --host 0.0.0.0 --port 8080 --tools all
0.00.014.095 I log_info: verbosity = 3 (adjust with the-lv NCLI arg)
0.00.014.097 I device_info:
0.00.014.112 I - ROCm0 : Radeon RX 7900 XTX (24560 MiB, 24524 MiB free)
0.00.014.154 I - ROCm1 : AMD Radeon Graphics (47068 MiB, 89322 MiB free)
0.00.014.156 I - CPU : AMD Ryzen 7 9700X 8-Core Processor (94137 MiB, 94137 MiB free)
0.00.014.207 I system_info: n_threads = 16 (n_threads_batch = 16) / 16 | ROCm : NO_VMM = 1 | PEER_MAX_BATCH_SIZE = 128 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX_VNNI = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | BMI2 = 1 | AVX512 = 1 | AVX512_VBMI = 1 | AVX512_VNNI = 1 | AVX512_BF16 = 1 | LLAMAFILE = 1 | OPENMP = 1 | REPACK = 1 |
0.00.014.234 I srv init: running without SSL
0.00.014.273 I srv init: using 15 threads for HTTP server
0.00.014.473 W srv llama_server: -----------------
0.00.014.474 W srv llama_server: Built-in tools are enabled, do not expose server to untrusted environments
0.00.014.474 W srv llama_server: This feature is EXPERIMENTAL and may be changed in the future
0.00.014.474 W srv llama_server: -----------------
0.00.014.481 I srv start: binding port with default address family
0.00.015.619 I srv llama_server: loading model
0.00.015.661 I srv load_model: loading model './models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q5_K_P.gguf'
0.00.052.136 I srv load_model: [mtmd] estimated worst-case memory usage of mmproj is 1157.64 MiB (took 36.45 ms)
0.00.295.983 I srv load_model: [spec] estimated memory usage of MTP context is 708.02 MiB
0.00.296.004 I common_init_result: fitting params to device memory ...
0.00.296.004 I common_init_result: (for bugs during this step try to reproduce them with -fit off, or provide --verbose logs if the bug only occurs with -fit on)
0.00.517.578 W common_fit_params: failed to fit params to free device memory: n_gpu_layers already set by user to 99, abort
0.01.810.285 W llama_context: n_ctx_seq (131072) < n_ctx_train (262144) -- the full capacity of the model will not be utilized
0.01.838.385 I common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
0.01.916.196 I srv load_model: creating MTP draft context against the target model './models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q5_K_P.gguf'
0.01.916.222 W llama_context: n_ctx_seq (131072) < n_ctx_train (262144) -- the full capacity of the model will not be utilized
0.01.932.754 W load_hparams: Qwen-VL models require at minimum 1024 image tokens to function correctly on grounding tasks
0.01.932.756 W load_hparams: if you encounter problems with accuracy, try adding --image-min-tokens 1024
0.01.932.756 W load_hparams: more info: https://github.com/ggml-org/llama.cpp/issues/168420.01.933.558 E ggml_backend_cuda_buffer_type_alloc_buffer: allocating 884.62 MiB on device 0: cudaMalloc failed: out of memory
0.01.933.561 E alloc_tensor_range: failed to allocate ROCm0 buffer of size 927588992
/home/liubo/llama.cpp/ggml/src/ggml-backend.cpp:179: GGML_ASSERT(buffer) failed
[New LWP 459888]
[New LWP 459887]
[New LWP 459886]
[New LWP 459885]
[New LWP 459884]
[New LWP 459883]
[New LWP 459882]
[New LWP 459881]
[New LWP 459880]
[New LWP 459879]
[New LWP 459878]
[New LWP 459877]
[New LWP 459876]
[New LWP 459875]
[New LWP 459874]
[New LWP 459717]
[New LWP 459716]
[New LWP 459715]
[New LWP 459714]
[New LWP 459713]
[New LWP 459712]
[New LWP 459711]
[New LWP 459710]
[New LWP 459709]
[New LWP 459708]
[New LWP 459707]
[New LWP 459706]
[New LWP 459705]
[New LWP 459704]
[New LWP 459703]
[New LWP 459702]
[New LWP 459700]
[New LWP 459699]
[New LWP 459696]This GDB supports auto-downloading debuginfo from the following URLs:
https://debuginfod.ubuntu.com
Enable debuginfod for this session? (y or [n]) [answered N; input not from terminal]
Debuginfod has been disabled.
To make this setting permanent, add 'set debuginfod enabled off' to .gdbinit.
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
0x0000762b61110813 in __GI___wait4 (pid=459889, stat_loc=0x0, options=0, usage=0x0) at ../sysdeps/unix/sysv/linux/wait4.c:30
warning: 30 ../sysdeps/unix/sysv/linux/wait4.c: No such file or directory
#0 0x0000762b61110813 in __GI___wait4 (pid=459889, stat_loc=0x0, options=0, usage=0x0) at ../sysdeps/unix/sysv/linux/wait4.c:30
30 in ../sysdeps/unix/sysv/linux/wait4.c
#1 0x0000762b6134e663 in ggml_print_backtrace () from /home/liubo/llama.cpp/build/bin/libggml-base.so.0
#2 0x0000762b6134e80b in ggml_abort () from /home/liubo/llama.cpp/build/bin/libggml-base.so.0
#3 0x0000762b61367611 in ggml_backend_buffer_set_usage () from /home/liubo/llama.cpp/build/bin/libggml-base.so.0
#4 0x0000762b617a75e8 in clip_model_loader::load_tensors(clip_ctx&) () from /home/liubo/llama.cpp/build/bin/libmtmd.so.0
#5 0x0000762b61795dcd in clip_init(char const*, clip_context_params) () from /home/liubo/llama.cpp/build/bin/libmtmd.so.0
#6 0x0000762b6170987c in mtmd_context::mtmd_context(char const*, llama_model const*, mtmd_context_params const&, bool) () from /home/liubo/llama.cpp/build/bin/libmtmd.so.0
#7 0x0000762b61703211 in mtmd_init_from_file () from /home/liubo/llama.cpp/build/bin/libmtmd.so.0
#8 0x0000762b619aab79 in server_context_impl::load_model(common_params&) () from /home/liubo/llama.cpp/build/bin/libllama-server-impl.so
#9 0x0000762b618e4a48 in llama_server(int, char**) () from /home/liubo/llama.cpp/build/bin/libllama-server-impl.so
#10 0x0000762b6102a1ca in __libc_start_call_main (main=main@entry=0x5e6c5fa22270 <main>, argc=argc@entry=40, argv=argv@entry=0x7fffc3eb01c8) at ../sysdeps/nptl/libc_start_call_main.h:58
warning: 58 ../sysdeps/nptl/libc_start_call_main.h: No such file or directory
#11 0x0000762b6102a28b in __libc_start_main_impl (main=0x5e6c5fa22270 <main>, argc=40, argv=0x7fffc3eb01c8, init=<optimized out>, fini=<optimized out>, rtld_fini=<optimized out>, stack_end=0x7fffc3eb01b8) at ../csu/libc-start.c:360
warning: 360 ../csu/libc-start.c: No such file or directory
#12 0x00005e6c5fa222a5 in _start ()
[Inferior 1 (process 459658) detached]
Aborted (core dumped)请问是我哪步弄错了吗?我问了gemini,它让我减少上下文,q4我可运行,占用21.5g,我加上q4和q5模型的权重差,我大概差1g的内存。我们几乎是一样的环境。感谢!!
@nami-ryuu 建議vulkan順很多
#!/bin/bash
先鎖 GPU 時脈(需 sudo)
sudo rocm-smi --device 0 --setperflevel manual
sudo bash -c "echo '2' > /sys/class/drm/card2/device/pp_dpm_sclk"
sudo bash -c "echo '3' > /sys/class/drm/card2/device/pp_dpm_mclk"export VK_ICD_FILENAMES=/usr/share/vulkan/icd.d/radeon_icd.json
SERVER=/path/to/llama.cpp/build-vulkan/bin/llama-server
MODEL=/path/to/Qwopus3.6-27B-v2-MTP-IQ4_XS.gguf"$SERVER"
--host 0.0.0.0 --port 8080
--device Vulkan0 \ # 指定 GPU0
-m "$MODEL"
--alias "unsloth/Qwen3.6-27B-GGUF"
--spec-type draft-mtp \ # 開啟 MTP 推測解碼
--spec-draft-n-max 3 \ # 一次預測 3 個草稿 token
-ngl 99 \ # 全部層放 GPU
--ctx-size 65536 \ # 65K context
-n 8192
-b 2048 -ub 512 -np 1
--cache-type-k q8_0 \ # q8_0 KV cache(比 q4_0 接受率高 10-15%)
--cache-type-v q8_0
--no-mmap --mlock
--flash-attn on
--jinja --no-warmup --reasoning off注意:不在 server 層設 sampling 參數(top-k/presence-penalty 會降低 MTP 接受率)
-
-
这个论坛的界面太丑了吧
-
@python96998 你可以在随便聊聊板块专门发帖,说出你对论坛UI的感受,可以说出哪里丑,这是你作为访客的权利,也可以提出改进建议。
这是个技术话题的帖子,你在这里如此回帖,是缺乏教养的表现。你不是宇宙的中心,这个论坛不是你的许愿池,如此缺乏教养就会被我扇耳光,被骂然后被禁言。煞笔东西。
-
@agi @chia-an-yang 两位老师我跑通了,但是我用hermes的时候工具调用感觉卡了额,我的7900xtx在疯狂的生成,但是hermes却卡住了。请问两位遇到过类似的问题吗?
llama.cpp 输出:65.27 t/s, tg_3s = 55.86 t/s
36.30.567.224 I slot print_timing: id 0 | task 8648 | n_decoded = 62072, tg = 65.24 t/s, tg_3s = 55.84 t/s
36.33.579.807 I slot print_timing: id 0 | task 8648 | n_decoded = 62240, tg = 65.21 t/s, tg_3s = 55.77 t/s
36.36.592.579 I slot print_timing: id 0 | task 8648 | n_decoded = 62408, tg = 65.18 t/s, tg_3s = 55.76 t/s
36.39.607.362 I slot print_timing: id 0 | task 8648 | n_decoded = 62576, tg = 65.15 t/s, tg_3s = 55.73 t/s
36.42.629.501 I slot print_timing: id 0 | task 8648 | n_decoded = 62744, tg = 65.12 t/s, tg_3s = 55.59 t/s
36.45.651.508 I slot print_timing: id 0 | task 8648 | n_decoded = 62912, tg = 65.09 t/s, tg_3s = 55.59 t/s
36.48.669.380 I slot print_timing: id 0 | task 8648 | n_decoded = 63080, tg = 65.06 t/s, tg_3s = 55.67 t/s
36.51.697.721 I slot print_timing: id 0 | task 8648 | n_decoded = 63247, tg = 65.03 t/s, tg_3s = 55.15 t/s
36.54.730.154 I slot print_timing: id 0 | task 8648 | n_decoded = 63415, tg = 65.00 t/s, tg_3s = 55.40 t/s
36.57.762.852 I slot print_timing: id 0 | task 8648 | n_decoded = 63583, tg = 64.97 t/s, tg_3s = 55.40 t/s
37.00.794.845 I slot print_timing: id 0 | task 8648 | n_decoded = 63751, tg = 64.94 t/s, tg_3s = 55.41 t/shermes输出:
c09f0fd3-2890-42e1-838f-8e36a2ab527b-bd93db497055bc01fe89b39dc4f1a308915fe680.rtfd
preparing browser_navigate...
navigate
search.yahoo.com
14.2s- Hermes
Let me try a more targeted search.
A
preparing browser_navigate... navigate www.google.com
3.35
Response truncated (finish_reason='length')
preparing browser_navigate...
navigate duckduckgo.com 20.5s preparing browser_scroll...
↓
scroll
down 0.2s
LOI
preparing browser_snapshot...
snapshot compact 0.2s preparing browser_navigate... navigate duckduckgo.com 1.5s
(>** cogitating...
model hit max output toke - qwen3.6-27b 30,9K/131.1K [
1]24% |36m |020
- Hermes
-
@agi @chia-an-yang 两位老师我跑通了,但是我用hermes的时候工具调用感觉卡了额,我的7900xtx在疯狂的生成,但是hermes却卡住了。请问两位遇到过类似的问题吗?
llama.cpp 输出:65.27 t/s, tg_3s = 55.86 t/s
36.30.567.224 I slot print_timing: id 0 | task 8648 | n_decoded = 62072, tg = 65.24 t/s, tg_3s = 55.84 t/s
36.33.579.807 I slot print_timing: id 0 | task 8648 | n_decoded = 62240, tg = 65.21 t/s, tg_3s = 55.77 t/s
36.36.592.579 I slot print_timing: id 0 | task 8648 | n_decoded = 62408, tg = 65.18 t/s, tg_3s = 55.76 t/s
36.39.607.362 I slot print_timing: id 0 | task 8648 | n_decoded = 62576, tg = 65.15 t/s, tg_3s = 55.73 t/s
36.42.629.501 I slot print_timing: id 0 | task 8648 | n_decoded = 62744, tg = 65.12 t/s, tg_3s = 55.59 t/s
36.45.651.508 I slot print_timing: id 0 | task 8648 | n_decoded = 62912, tg = 65.09 t/s, tg_3s = 55.59 t/s
36.48.669.380 I slot print_timing: id 0 | task 8648 | n_decoded = 63080, tg = 65.06 t/s, tg_3s = 55.67 t/s
36.51.697.721 I slot print_timing: id 0 | task 8648 | n_decoded = 63247, tg = 65.03 t/s, tg_3s = 55.15 t/s
36.54.730.154 I slot print_timing: id 0 | task 8648 | n_decoded = 63415, tg = 65.00 t/s, tg_3s = 55.40 t/s
36.57.762.852 I slot print_timing: id 0 | task 8648 | n_decoded = 63583, tg = 64.97 t/s, tg_3s = 55.40 t/s
37.00.794.845 I slot print_timing: id 0 | task 8648 | n_decoded = 63751, tg = 64.94 t/s, tg_3s = 55.41 t/shermes输出:
c09f0fd3-2890-42e1-838f-8e36a2ab527b-bd93db497055bc01fe89b39dc4f1a308915fe680.rtfd
preparing browser_navigate...
navigate
search.yahoo.com
14.2s- Hermes
Let me try a more targeted search.
A
preparing browser_navigate... navigate www.google.com
3.35
Response truncated (finish_reason='length')
preparing browser_navigate...
navigate duckduckgo.com 20.5s preparing browser_scroll...
↓
scroll
down 0.2s
LOI
preparing browser_snapshot...
snapshot compact 0.2s preparing browser_navigate... navigate duckduckgo.com 1.5s
(>** cogitating...
model hit max output toke - qwen3.6-27b 30,9K/131.1K [
1]24% |36m |020
- Hermes
-
@terry 老师,但是它在的decode的时候生成将近60000个字符之后系统强制停止的。Response truncated (finish_reason='length'),感觉它不知道啥时候停止,最后hermes把结果截断了。
{kind=link}