
试一试玩转 LTX-2.3 AI lip-sync (唇形同步模型)
-
前文:
之前一直使用一款 极度简捷的唇形同步节点 Comfyui_Sonic,
还有,一定一定要参考我怎样copy 人物原音,不要只是用voxcpm
用ai 把 王祖贤 还原成香港配音https://github.com/smthemex/ComfyUI_Sonic
这个唇形同步可以简单到只要上载图像,上载语音,不用任何Prompt,
他就自动产出相当出色的唇形同步画面。效果参考这个视频:
https://youtu.be/9mzmB2aDgi8
缺点是:没有缺点,只不过我想试一试,比这个更加简单的。。
vram不足,处理时间太过长,这是我的缺点,不是他的缺点最终还是找回 LTX-2.3 AI lip-sync
官方对于LTX-2.3 AI lip-sync的介绍:
直接在Comfyui里面下载:
LTX-2.3 AI唇形同步模型采用音频到视频的转换流程,生成高度精准的人物说话视频。通过将参考图像与语音或歌唱音轨相结合,该模型能够完美匹配角色的嘴部动作、头部运动和自然面部表情。
模型工作原理
-
音频驱动生成:LTX-2.3 并非将嘴部动作粘贴到静态面部,而是将音频文件直接编码到潜在空间中。这样一来,除了嘴唇的动作之外,还能产生微妙的微表情、眉毛动作和自然的头部倾斜。
-
TalkVid ID-LoRA:为了使角色的面部在多个镜头或较长的视频中保持一致,您可以使用专门的身份 LoRA。
-
三标签提示系统:为了获得最佳效果,提示通常分为三个标签:[视觉] 用于摄像机/灯光,[语音] 用于确切的歌词或词语,[声音] 用于背景音频。
最佳平台和工作流程
ComfyUI 工作流程:为了完全控制角色的面部一致性、循环播放和音频注入,
总之讲到玩就是劲就对了。。。
其他的checkpoint照旧之前的ltx2.3, 如果你已经玩得非常熟悉,进入这里,一定也是照样顺顺利利,
对了,在官方得工作流,我加了两点自己的东西:- 加了自己对于画面的 auto height and auto width 的玩法,
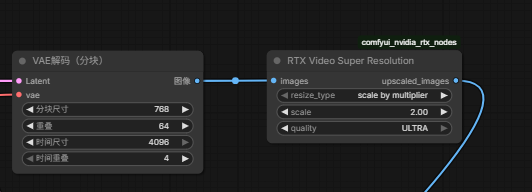
- 另外在输出的时候加了Rtx Video Super Resolution
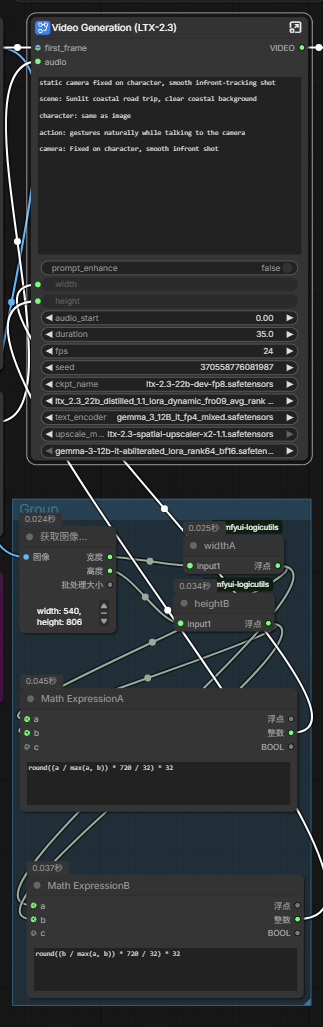
试一试用这个Prompt
static camera fixed on character, smooth infront-tracking shot scene: Sunlit coastal road trip, clear coastal background character: same as image action: gestures naturally while talking to the camera camera: Fixed on character, smooth infront shot
效果:
Comfyui Sonic Lip Syn
https://youtube.com/shorts/xOVSaBwaL3I?feature=shareLtx2.3 Lip Syn
https://youtube.com/shorts/I9Ri89pytAs?feature=share -
-
,
I imbiplaza ASUS 引用了 此主题
-
,