
【国产替代】智铠100 32Gx2部署Qwen3.6-35B-W4A8含多并发测试结果
-
1. 说明

双智铠100算力卡运行大模型的测试情况,当前已完整形成性能测试结果的模型为:Qwen3.6-35B-A3B-W4A8
并且opencode接入了该模型使用,非常快

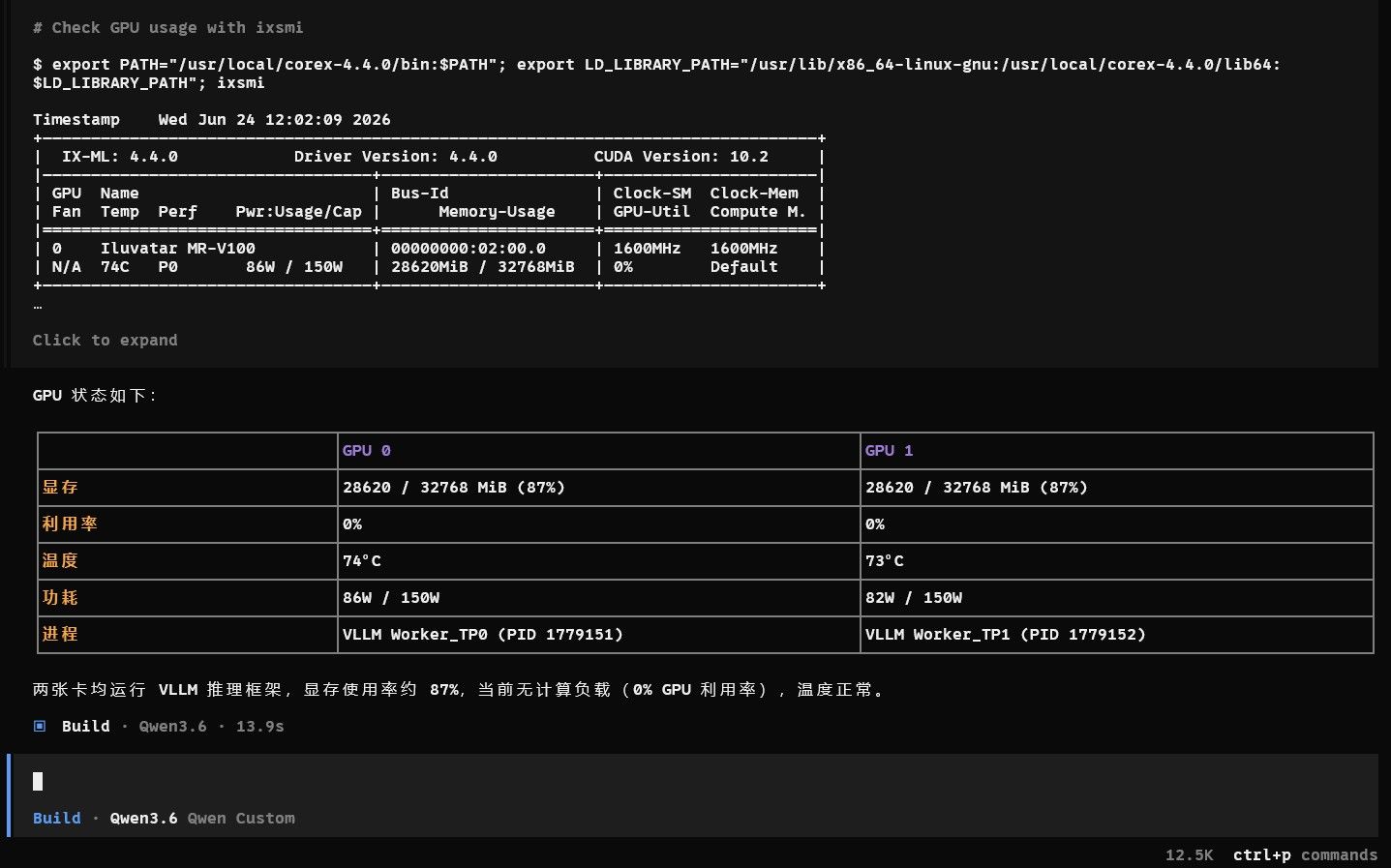
2. 测试对象
硬件对象:双智铠100算力卡。
推理框架:vLLM。
接口协议:OpenAI Chat Completions API。
主要测试接口:
http://127.0.0.1:10030/v1/chat/completions主要测试模型:
Qwen3.6-35B-A3B-W4A8模型路径:
/data/model/Qwen3___6-35B-A3B-W4A83. Qwen3.6-35B-A3B-W4A8 启动命令
3.1 日常交互启动命令
该配置适合低并发、普通上下文和长上下文测试。
export VLLM_RPC_TIMEOUT=50000 export VLLM_ENFORCE_CUDA_GRAPH=1 export VLLM_W8A8_MOE_USE_W4A8=1 export VLLM_KV_DISABLE_CROSS_GROUP_SHARE=1 vllm serve /data/model/Qwen3___6-35B-A3B-W4A8 \ --trust-remote-code \ --tensor-parallel-size 2 \ --max-num-seqs 4 \ --enable-chunked-prefill \ --max-model-len 65536 \ --reasoning-parser qwen3 \ --enable-auto-tool-choice \ --tool-call-parser qwen3_coder \ --host 0.0.0.0 \ --port 10030 \ --gpu-memory-utilization 0.90 \ --served-model-name Qwen3.6-35B-A3B-W4A8 \ --compilation-config '{"cudagraph_mode": "FULL_DECODE_ONLY", "level": 0}' \ --default-chat-template-kwargs '{"enable_thinking": false}'3.2 吞吐压测启动命令
该配置用于 6、8、12 并发测试,主要观察吞吐上限和过载边界。
export VLLM_RPC_TIMEOUT=50000 export VLLM_ENFORCE_CUDA_GRAPH=1 export VLLM_W8A8_MOE_USE_W4A8=1 export VLLM_KV_DISABLE_CROSS_GROUP_SHARE=1 vllm serve /data/model/Qwen3___6-35B-A3B-W4A8 \ --trust-remote-code \ --tensor-parallel-size 2 \ --max-num-seqs 12 \ --enable-chunked-prefill \ --max-model-len 65536 \ --reasoning-parser qwen3 \ --enable-auto-tool-choice \ --tool-call-parser qwen3_coder \ --host 0.0.0.0 \ --port 10030 \ --gpu-memory-utilization 0.90 \ --served-model-name Qwen3.6-35B-A3B-W4A8 \ --compilation-config '{"cudagraph_mode": "FULL_DECODE_ONLY", "level": 0}' \ --default-chat-template-kwargs '{"enable_thinking": false}'4. 测试命令模板
4.1 单并发普通上下文测试
vllm bench serve \ --backend openai-chat \ --base-url http://127.0.0.1:10030 \ --endpoint /v1/chat/completions \ --model Qwen3.6-35B-A3B-W4A8 \ --tokenizer /data/model/Qwen3___6-35B-A3B-W4A8 \ --dataset-name random \ --random-input-len 2048 \ --random-output-len 512 \ --num-prompts 20 \ --request-rate inf \ --max-concurrency 1 \ --ignore-eos \ --seed 1234.2 普通上下文多并发测试
将
--max-concurrency分别设置为4、6、8、12。vllm bench serve \ --backend openai-chat \ --base-url http://127.0.0.1:10030 \ --endpoint /v1/chat/completions \ --model Qwen3.6-35B-A3B-W4A8 \ --tokenizer /data/model/Qwen3___6-35B-A3B-W4A8 \ --dataset-name random \ --random-input-len 4096 \ --random-output-len 512 \ --num-prompts 50 \ --request-rate inf \ --max-concurrency 8 \ --ignore-eos \ --seed 123说明:4 并发测试时,实际提供的测试请求数为 10;6、8、12 并发测试请求数为 50。
4.3 长上下文测试
vllm bench serve \ --backend openai-chat \ --base-url http://127.0.0.1:10030 \ --endpoint /v1/chat/completions \ --model Qwen3.6-35B-A3B-W4A8 \ --tokenizer /data/model/Qwen3___6-35B-A3B-W4A8 \ --dataset-name random \ --random-input-len 16384 \ --random-output-len 512 \ --num-prompts 20 \ --request-rate inf \ --max-concurrency 2 \ --ignore-eos \ --seed 1235. Qwen3.6-35B-A3B-W4A8 测试结果总表
表格 1:基础信息与吞吐量
测试场景 输入/输出 tokens 并发 请求数 成功数 失败数 总耗时 输出吞吐 (tok/s) 总吞吐 (tok/s) 单并发普通上下文 2048 / 512 1 20 20 0 181.81s 56.32 281.61 4 并发普通上下文 4096 / 512 4 10 10 0 44.94s 113.93 1025.39 6 并发普通上下文 4096 / 512 6 50 50 0 172.87s 148.09 1332.81 8 并发普通上下文 4096 / 512 8 50 50 0 149.76s 170.94 1538.48 12 并发普通上下文 4096 / 512 12 50 50 0 236.90s 108.06 972.58 长上下文 16384 / 512 2 20 20 0 192.28s 53.26 1757.45 表格 2:延迟指标(TTFT / TPOT / ITL)
测试场景 平均 TTFT P99 TTFT 平均 TPOT P99 TPOT P99 ITL 单并发普通上下文 675.33ms 684.19ms 16.47ms 16.59ms 17.21ms 4 并发普通上下文 2539.73ms 4174.28ms 25.62ms 28.45ms 24.38ms 6 并发普通上下文 2812.72ms 5848.28ms 33.38ms 36.07ms 508.41ms 8 并发普通上下文 3110.26ms 8321.04ms 38.25ms 41.46ms 515.14ms 12 并发普通上下文 3593.71ms 12122.58ms 100.03ms 106.45ms 524.32ms 长上下文 6423.67ms 8687.50ms 25.04ms 28.39ms 22.67ms 6. 每用户体感输出速度
每用户体感输出速度按以下公式估算:
每用户输出速度 ≈ 1000 / 平均 TPOT(ms)测试场景 平均 TPOT 估算每用户输出速度 单并发普通上下文 16.47ms 约 60.72 tok/s 4 并发普通上下文 25.62ms 约 39.03 tok/s 6 并发普通上下文 33.38ms 约 29.96 tok/s 8 并发普通上下文 38.25ms 约 26.14 tok/s 12 并发普通上下文 100.03ms 约 10.00 tok/s 长上下文 25.04ms 约 39.94 tok/s 补充:
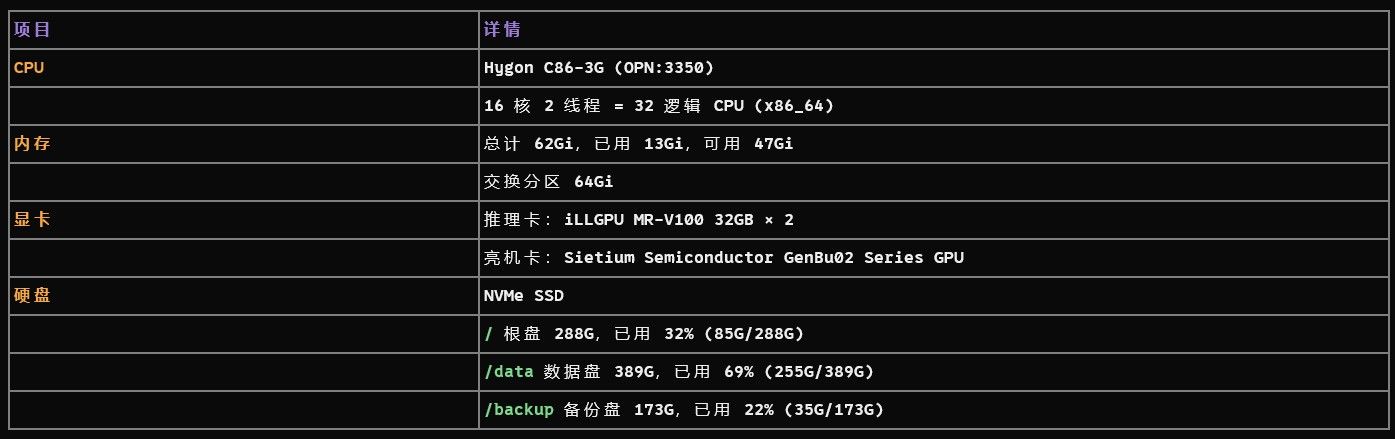
配置信息
价格
公司订购的一台测试机子,工作站样式,外壳应该是铝的定制的;整机5w多。我看淘宝上同款推理卡mr-100一张1.5w左右
-
,
 T terry 固定了此主题
T terry 固定了此主题
-
被動散熱估計也是data center的卡, 類似6000D的東東
先不說家用要改散熱, 有點懷疑一張卡的價格估計都要20到30K了
不過多一個玩家總是好事, 期待能把價格打下來
雖然以老黃的性格我覺得很難就是了@566656661 我这里是个台式机,推理卡也是改了涡轮散热,太神奇了

-
@566656661 我这里是个台式机,推理卡也是改了涡轮散热,太神奇了
-
@566656661 这卡待机功耗也太高了,两张100w,在旁边闷热闷热的
-
@566656661 这卡待机功耗也太高了,两张100w,在旁边闷热闷热的
-
,系统 取消固定了此主题
