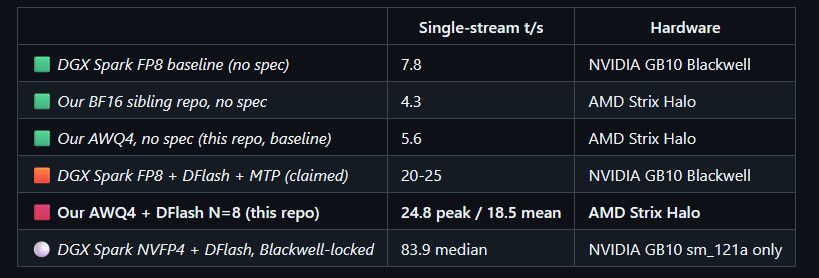
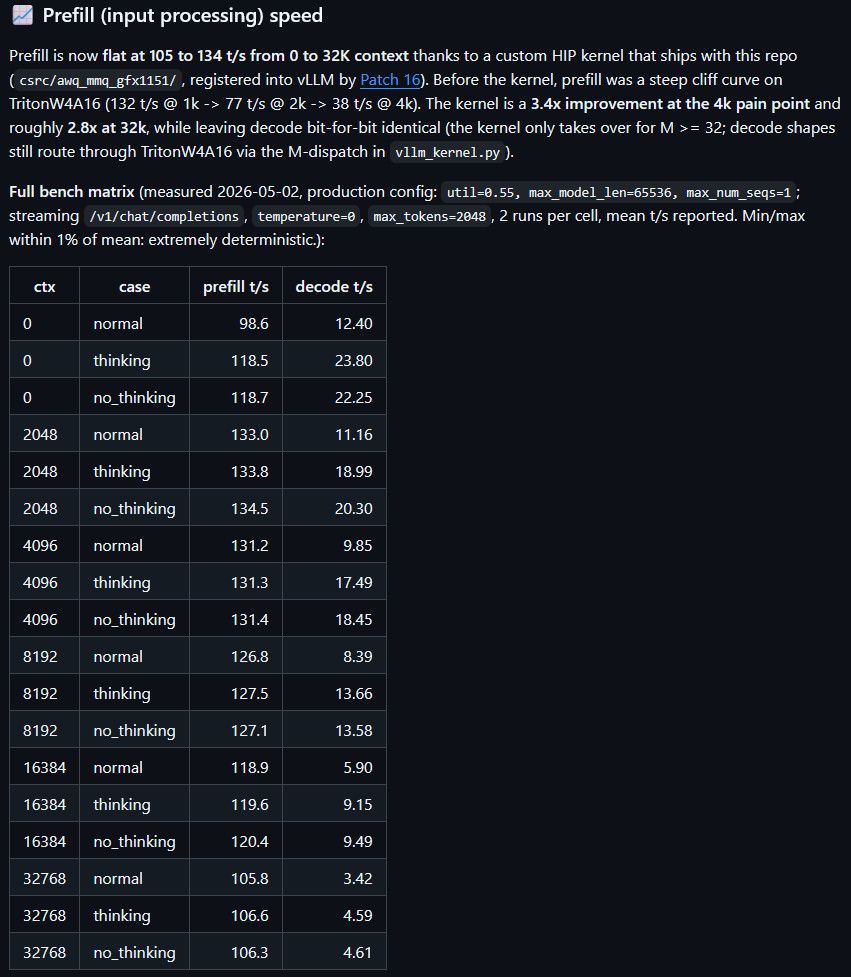
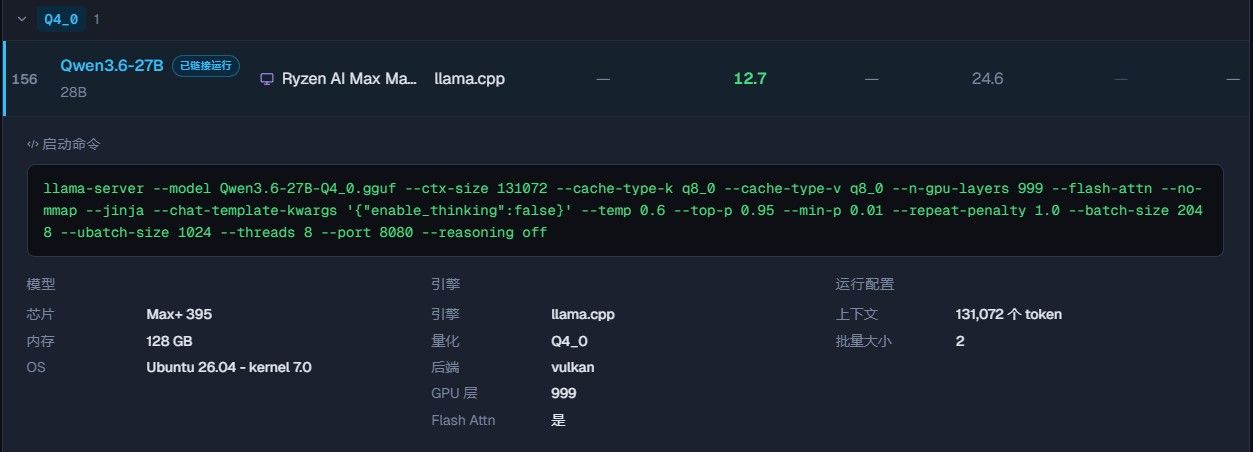
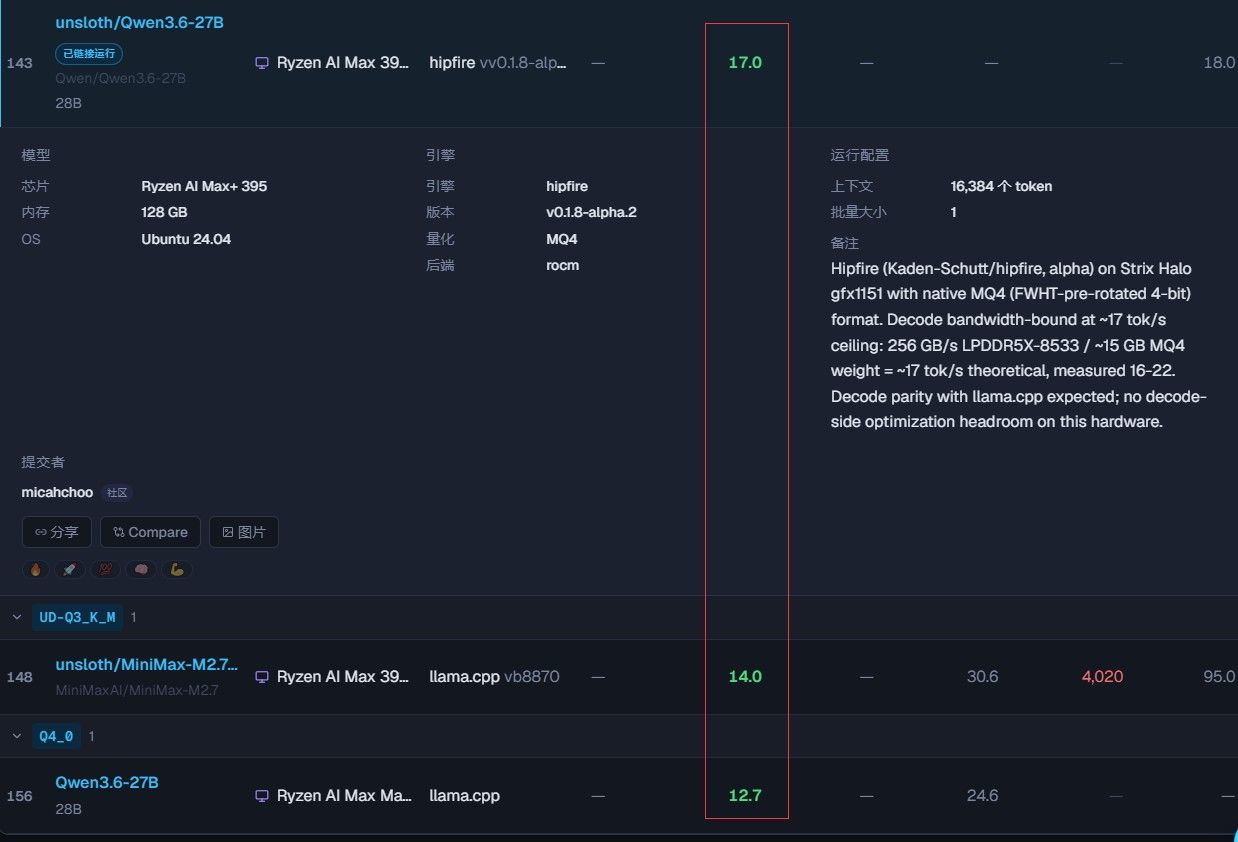
请问有没有人可以帮助提供 AMD AI MAX 395 跑Qwen3.6-27B的速度情况?
-
我想购买一个128G的
- 主要是看中他满载功耗低,
- 统一内存又没有显存焦虑
就是不知道跑Q4_K_M 或者 Q8 ,搭配opencode或者harmes在真实环境下,一般的速度分别是多少?
多谢各位大佬!
-
我记得好像是 5t/s.
Strix Halo 的推理性能受限于内存带宽而非算力:
UMA 带宽约 215 GB/s(理论值)
27B 模型的 decode 主要是权重流带宽瓶颈
因此量化到 Q8_0 比 BF16 快约 75%,Q4 比 Q8 更快
需要高速推理可以被劝退了。精度 权重大小 显存占用 Decode 速度 适用场景 BF16 (vLLM) 51.2 GB ~105 GB ~4.3 t/s 需原生精度、Vision 输入、Responses API Q8_0 (llama.cpp) ~27 GB ~35 GB ~7.5 t/s 日常对话、Agent 循环、速度优先 Q4_K_M ~16.8 GB 更低 ~10-12 t/s 长上下文、多模型并发