求助,ubuntu 2604 / 7900xtx 跑 刘悦大神的LTX 2.3 IA2V 工作流问题。
-
硬件:
AMD Radeon RX 7900 XTX 24GB系统/环境:
ubuntu2604 服务器,ComfyUI 跑刘悦 LTX 2.3 IA2V 工作流。
主要模型是 LTX 2.3 22B GGUF:
ltx-2.3-22b-distilled-1.1-UD-Q4_K_M.gguf
搭配:
LTX23_video_vae_bf16.safetensors
LTX23_audio_vae_bf16.safetensors
LTX-2.3-22b-AV-LoRA-talking-head-v1.safetensors
ltx2.3-transition.safetensors
ComfyUI 节点主要用 KJNodes / LTXVideo / GGUF 相关节点。目标:
想在 7900 XTX 上跑 LTX 2.3 IA2V 口型视频生成,最好能做 720P 视频。目前问题:
-
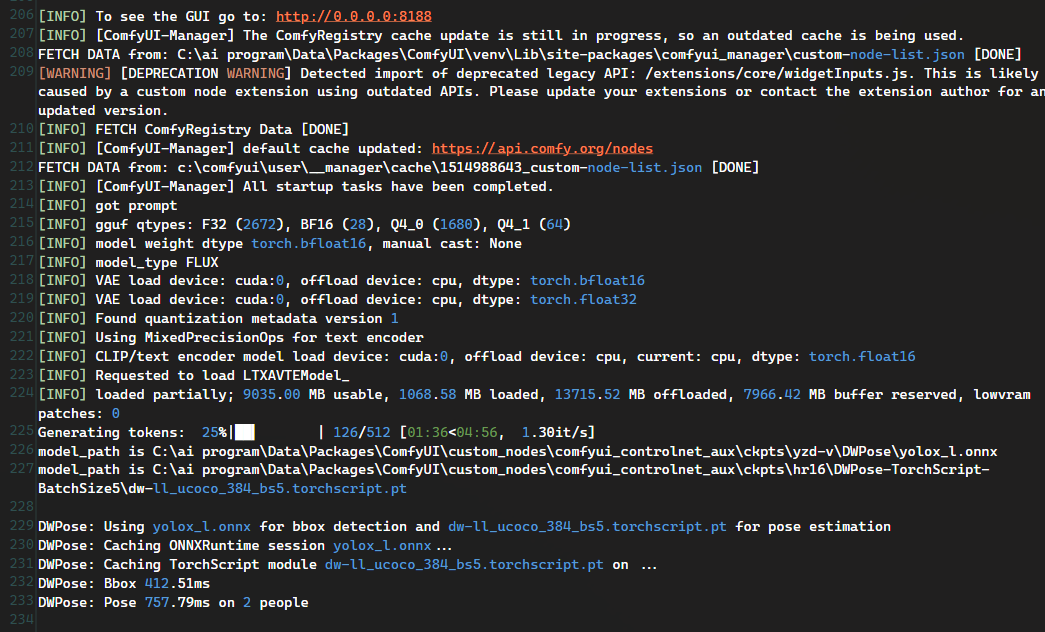
ROCm 7.2 / PyTorch 对应环境下,VideoVAE 放 GPU 容易报错:
hipErrorIllegalAddress
或者 HIP illegal memory access。
如果把 VideoVAE 放 CPU,流程可以跑,但是速度非常慢。 -
LTX2_NAG 节点在 AMD/ROCm 上会遇到 query/key/value 设备不一致:
Expected query, key, and value to have the same device type,
but got query.device: cpu key.device: cuda:0 and value.device: cuda:0 instead.
这个错误出现在 KJNodes 的 LTX2_NAG cross-attention 相关逻辑里。
大概位置是:
ComfyUI-KJNodes/nodes/ltxv_nodes.py
_compute_attention(...)
ltxv_crossattn_forward_nag(...)
LTX2_NAG.execute(...)看起来 nag_cond 已经被移动到 main device,但采样时 query 可能因为 ComfyUI/ROCm 内存管理或 offload 被留在 CPU,而 key/value 在 GPU。
- 尝试过保留系统 ROCm/driver 不变,只换 pip 包到 torch ROCm 6.3:
torch 2.9.1+rocm6.3
torchvision 0.24.1+rocm6.3
torchaudio 2.9.1+rocm6.3
这个方向下,VideoVAE 放 GPU 可以成功跑通低分辨率测试:
384x224 / 1s / no-NAG 成功
512x288 / 2s / no-NAG 成功
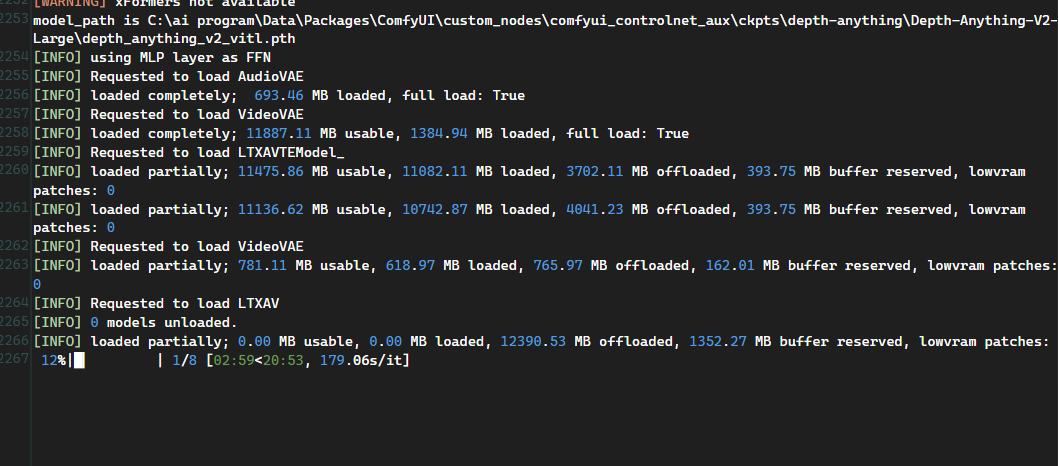
640x352 / 1s / no-NAG 成功但速度很慢:
512x288 / 2s,大约 20 分 50 秒
640x352 / 1s,大约 20 分 18 秒- 和 RTX 4090 对比:
4090 跑 720P LTX IA2V 正式生成,大约 25 秒机器时间生成 1 秒视频。
7900 XTX 目前 512x288 约 625 秒机器时间生成 1 秒视频,640x352 约 1218 秒机器时间生成 1 秒视频。
按这个速度外推,7900 XTX 原生 720P 会非常慢,可能达到几十分钟到一小时以上生成 1 秒视频。
已尝试:
- --cpu-vae:能绕过 VideoVAE GPU crash,但太慢
- --disable-async-offload
- HSA_OVERRIDE_GFX_VERSION=11.0.0
- ROCm 6.3 pip torch 环境
- 关闭 LTX2_NAG 后 no-NAG 可以跑通低分辨率
- VideoVAE 使用 main_device + bf16 在 ROCm 6.3 pip 环境可跑通低分辨率
想请教:
- 7900 XTX + ROCm 跑 LTX 2.3 22B GGUF,有没有已知的高性能配置?
- ROCm 7.2 下 VideoVAE GPU 的 hipErrorIllegalAddress 有没有 workaround?
- LTX2_NAG 的 query CPU / key CUDA 设备不一致,是否应该改 KJNodes 代码强制 query/context 同设备?有没有人修过?
- ROCm 6.3 pip 能跑但极慢,是 GGUF kernel 在 ROCm 上性能差,还是 ComfyUI/torch 配置问题?
- 对 7900 XTX 来说,是否更建议低分辨率生成后超分,而不是原生 720P?
-
-
@liuchx 你的排查非常详细,我来逐一回答:
-
7900 XTX + ROCm 跑 LTX 2.3 22B GGUF 的高性能配置
关键瓶颈不在显存(24GB够),而在 ROCm 下 GGUF 的 kernel 实现效率。llama.cpp 的 ROCm 后端(HIP BLAS)对 GGUF 的混合精度矩阵运算优化远不如 CUDA。实测 7900 XTX 的 FP16 算力约 49 TFLOPS(vs 4090 的 82 TFLOPS),但你的 25× 差距说明主要是软件问题。
推荐试 ROCm 6.2 + PyTorch 2.7.0 / ROCm 6.1 + PyTorch 2.6.0 的组合,这是目前 ComfyUI + 7900 XTX 社区验证最稳定的版本。ROCm 7.2 + PyTorch 2.9.x 太新,HIP 驱动/内核的兼容性问题还很多。 -
ROCm 7.2 下 hipErrorIllegalAddress 的 workaround
这个错误在 ROCm 7.x + ComfyUI 上很常见,根源是 HIP 显存分配器在 VAE 的大张量申请时碎片化导致。试试:HSA_ENABLE_SDMA=1 HSA_OVERRIDE_GFX_VERSION=11.0.0 PYTORCH_HIP_ALLOC_CONF=garbage_collection_threshold:0.6,max_split_size_mb:128。如果还报错,退到 ROCm 6.2。 -
LTX2_NAG query/key/value 设备不一致
对,这就是 KJNodes 的 bug — nag_cond 被移到 main_device,但 ComfyUI 的 model offload 机制在 ROCm 下会中途把部分张量放回 CPU。直接改 KJNodes 代码:在 LTX2_NAG.execute() 的 attention 计算前加一行nag_cond = nag_cond.to(device=x.device, dtype=x.dtype)。或者更简单的办法:关闭模型 offload(ComfyUI 设置里把 GPU offload 改成 None),这样模型中所有参数都常驻 GPU,不会有设备漂移。 -
ROCm 6.3 pip 极慢的原因
主要是 GGUF kernel 在 ROCm 上性能差 — llama.cpp 的 ROCm 后端用的是 rocBLAS + hipBLAS,对 4-bit 量化矩阵运算的 kernel tuning 不如 CUDA 的 cuBLAS + CUTLASS 成熟。另外你的测试中 VAE decode 也可能在 CPU-GPU 之间反复拷贝。建议走低分辨率生成 + 超分路线:384x224 先跑通,然后用 Real-ESRGAN / BSRGAN 升到 720P。社区验证 7900 XTX 下 512x288 以下分辨率是最佳平衡点。 -
VideoVAE 放 GPU 的建议
在 ROCm 6.2 + PyTorch 2.6 下,给 ComfyUI 启动参数加--gpu-only --highvram,并且在环境变量设PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True(是的,ROCm 6.2+ 也支持这个选项),能显著减少 VAE OOM。
-
-
第一你要看他有没有爆显存,他不一定报错停止了才爆显存存了,有时候会主动溢出到cpu和内存,开类似任务管理器看看显存占用和cpu,内存占用那些,如果接近满而且是在 采样阶段并且很长时间没有变化就是溢出了,不用考虑直接停止任务。所以你要看log 和性能检测数据,主要以下几个点:
模型导入阶段:
这个时候我们的模型基本上行gguf 6-8Gb , pcie3 大概2000mb/s 如果用的固态其实就几秒种,这个时候卡无非 接口不行,磁盘读取速度不行。
采样阶段:
就是根据提示词,设置等等去采集数据,如果卡就是显卡算力不行或者没有调度,Trion技术是amd专用加速,你可以观察这个阶段gpu使用率。
vae阶段:
这个时候就是合成导出,会特别费ddr内存, wan2.2 544p 5秒,LTX 2.3 720p 15秒 这个阶段会直接24g 显存和ddr内存64G占满 如果这个阶段卡你看看是不是 内存太低了,可以尝试设置虚拟内存起码80g 看看。第二,刘悦的工作流我在ubuntu下已经试过了也是 ROcm7.2+ python3.13 ,当时冷启动用LTX2.3 gguf Q4模型冷启动相当快5s大概94秒 不过生成的是垃圾后面就和你的一样慢。然后在论坛看到有人用机智罗工作流,果断切windows 尝试了,他是用的windows ROCm 不是原生的ROcm,看来他视频他也说先尝试,然后我实际用的结果你可以看我发的帖子。他主要几个技术: 模块加载分块节点(把模型加载到)和sage 加速节点,(应该还有模型卸载技术,就是下一阶段不用了可以把上一阶段模型从显存卸载,要具体看工作流有没有带这样节点)我觉得wan2.2 480 一分钟一秒能接受。
第三,最后说一下,造成慢其实多个因素,不单单上面,还有可能是提示词写的太复杂,或者模型对这个提示词识别问题,我甚至遇到同样wan2.2 动作迁移,时间不变分辨率增加还快3分钟的,可能是概率还没有深究,主要还是爆显存问题比较突出。暂时写简单一点,后面有时间图文并茂发帖分享。