最近刚入手了 7900xtx,本地跑llm, 为opencode, pi.dev 提供本地llm api 解决客户的代码隐私焦虑。
花了亿点点时间跑了下性能,结果如下,供各位参考。流水账,先不贴llama-bench 结果了,太多。
先发 老特 这里了,回头有空了再发个reddit
回头等DFlash + HIP(ROCM) 成熟了再跑下看看。
1. Rocm + turboquant,
repo: https://github.com/domvox/llama.cpp-turboquant-hip
性能: 256k上下文, pp: 970t/s tg: 29t/s
Comment:目前测试,除了反应没在线api 快,生成代码的质量不比在线api 差。
~/llama.cpp-turboquant-hip/rocm/llama-server -m ~/model/llm/qwen3.6-27b/Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-Q4_K_P.gguf --mmproj ~/model/llm/qwen3.6-27b/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf --alias qwen3.6-27b --host 0.0.0.0 --port 8080 --n-gpu-layers 999 --ctx-size 262144 --batch-size 2048 --ubatch-size 768 --threads 8 --temp 1.0 --top-p 0.95 --top-k 20 --min-p 0.00 --presence_penalty 1.5 --cache-type-k turbo3 --cache-type-v turbo3
2. Vulkan
repo: https://github.com/ggml-org/llama.cpp
性能: 256k上下文, kv-cache-type: Q4_0, pp: 730t/s tg: 47t/s, (Q8_0会慢一丢丢)
~/Downloads/llama.cpp/vulkan/bin/llama-server -m ~/model/llm/qwen3.6-27b/Qwen3.6-27B-Q4_K_M-mtp.gguf --alias qwen3.6-27b --cache-type-k q4_0 --cache-type-v q4_0 -np 1 -c 262144 --temp 0.7 --top-k 20 -ngl 99 --port 8080 --host 0.0.0.0 -fa 1 -ub 256
2.1 Vulkan + turboquant,
repo: https://github.com/TheTom/llama-cpp-turboquant
性能: 256k上下文, kv-cache-type: Q4_0, tg: 10t/s, decoding 时 GPU 使用率不到 30%,速度拉跨。开MTP 也 差不多。
~/llama.cpp/build/bin/llama-server -m ~/model/llm/qwen3.6-27b/Qwen3.6-27B-Q4_K_M-mtp.gguf --alias qwen3.6-27b --cache-type-k turbo3 --cache-type-v turbo3 -np 1 -c 262144 --temp 0.7 --top-k 20 -ngl 99 --port 8080 --host 0.0.0.0 -fa 1 -ub 256
3. Vulkan + MTP
repo/pr:
https://github.com/ggml-org/llama.cpp/pull/22673
性能: 256k上下文, kv-cache-type: Q4_0, pp: 730t/s tg: 67t/s, VRAM 占用跟不开MTP 差不多,
~/Downloads/llama.cpp/vulkan/bin/llama-server -m ~/model/llm/qwen3.6-27b/Qwen3.6-27B-Q4_K_M-mtp.gguf --alias qwen3.6-27b --spec-type mtp --spec-draft-n-max 3 --cache-type-k q4_0 --cache-type-v q4_0 -np 1 -c 262144 --temp 0.7 --top-k 20 -ngl 99 --port 8080 --host 0.0.0.0 -fa 1 -ub 256
3. Rocm + MTP
repo/pr: https://github.com/ggml-org/llama.cpp/pull/22673
性能: 4k上下文, kv-cache-type: Q4_0, pp: 730t/s tg: 67t/s
Comment: Rocm的backend + MTP 有问题,VRAM 在开始 对话时 暴增 5G,具体原因不明,所以 最多8k上下文, Rocm目前的好处 是由 turbo quant 集成。
~/llama.cpp/build/bin/llama-server -m ~/model/llm/qwen3.6-27b/Qwen3.6-27B-Q4_K_M-mtp.gguf --alias qwen3.6-27b --spec-type mtp --spec-draft-n-max 3 --cache-type-k q4_0 --cache-type-v q4_0 -np 1 -c 4096 --temp 0.7 --top-k 20 -ngl 99 --port 8080 --host 0.0.0.0 -fa 1 -ub 256
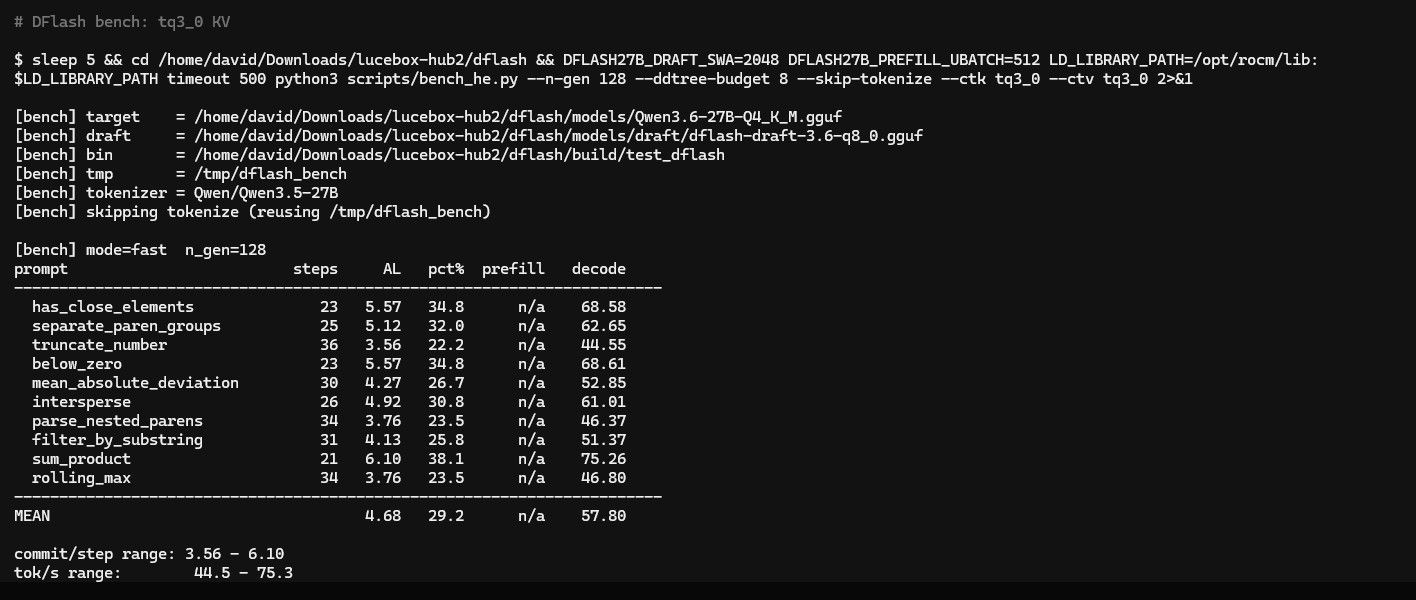
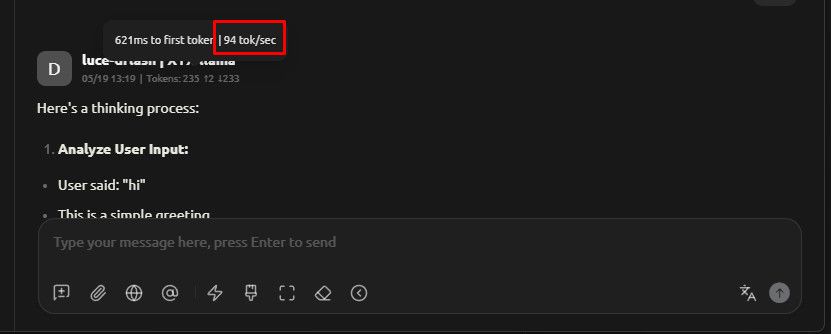
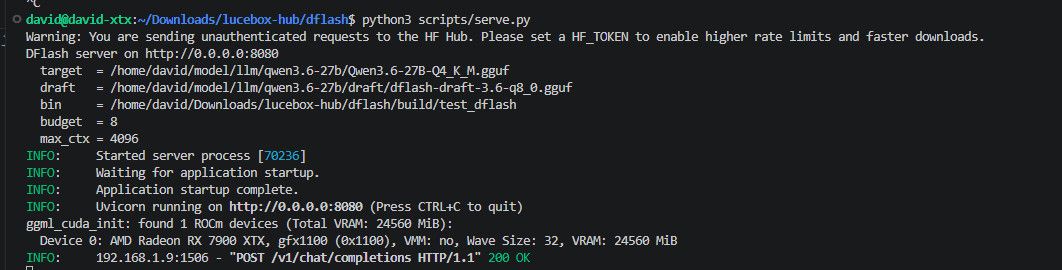
4.Hipfire (DFlash) v0.1.20
repo: https://github.com/Kaden-Schutt/hipfire
性能: 4k上下文, pp: 930t/s tg: 46t/s,
Comment: 只能chat聊天,速度很快,默认开启 DFlash, 但是 上下文8k 以上就会卡死,或者崩溃, 没法给 opencode 或者pi 使用,等三个月半年再看看。
5. 老卡 P40 24G,
repo: https://github.com/TheTom/llama-cpp-turboquant
pr: https://github.com/ggml-org/llama.cpp/pull/22673
不开MTP
性能: 196k 上下文,tg: 10t/s,
~/llama.cpp-mtp/build/bin/llama-server -m ~/model/llm/qwen3.6-27b/Qwen3.6-27B-Q4_K_M-mtp.gguf --alias qwen3.6-27b --cache-type-k turbo3 --cache-type-v turbo3 -c 196608 --temp 0.7 --top-k 20 -ngl 99 --port 8080 --host 0.0.0.0 -fa 1 -ub 256
开MTP
性能: 196k上下文,tg: 17t/s,
~/llama-cpp-turboquant/build/bin/llama-server -m ~/model/llm/qwen3.6-27b/Qwen3.6-27B-Q4_K_M-mtp.gguf --alias qwen3.6-27b --spec-type mtp --spec-draft-n-max 3 --cache-type-k turbo3 --cache-type-v turbo3 -np 1 -c 196608 --temp 0.7 --top-k 20 -ngl 99 --port 8080 --host 0.0.0.0 -fa 1 -ub 256
opencode + deepseek v4 帮我跑了一把,结果如下
- 如果追求性能 Vulkan + MTP 效果最好,
- MTP的性能不是恒定的,不同的上下文或者任务,可能存在很大的差别,你让他写小说,规划日常,写代码,性能提升可能会不一样,跑分仅供参考。
- MTP 目前只能单个对话session,没法并行。
- Vuklan 后端对 Turbo quant的支持还有存在问题, GPU利用率不够,还得优化。
- Rocm + MTP 存在 VRAM问题,会无端暴涨5G占用,导致跑起来最多8k多一点。
llama.cpp master branch 测试结果 (2026-6-2)
由于最近 PR22673 merge到了主分支,今天正好有空重新跑了下,结果差不多。
系统配置
- GPU:AMD Radeon RX 7900 XTX(24GB 显存)
- 构建:llama.cpp 9470(Vulkan + ROCm 后端)
最佳参数
| 参数 | 最佳值 |
|---|---|
| 后端 | Vulkan |
| MTP | --spec-type draft-mtp --spec-draft-n-max 2 |
| 子批次大小 | -ub 512 |
| 批次大小 | -b 512 |
| 闪存注意力 | -fa auto(默认) |
| KV 缓存 | -ctk q4_0 -ctv q4_0 |
| GPU 层数 | -ngl 999(全部) |
| 线程数 | 默认(自动) |
| 上下文大小 | 最高 -c 262144(256K) |
原始 GPU 基准测试(llama-bench,pp512/tg128)
子批次大小扫描
| ubatch | ROCm pp(t/s) | ROCm tg(t/s) | Vulkan pp(t/s) | Vulkan tg(t/s) |
|---|---|---|---|---|
| 64 | 614 | 29 | 511 | 40 |
| 128 | 703 | 29 | 768 | 40 |
| 256 | 910 | 29 | 844 | 40 |
| 512 | 975 | 29 | 908 | 40 |
| 1024 | 977 | 29 | 908 | 40 |
KV 缓存类型(性能影响可忽略)
| KV 类型 | ROCm pp | ROCm tg | Vulkan pp | Vulkan tg |
|---|---|---|---|---|
| f16 | 975 | 29 | 907 | 40 |
| q8_0 | 973 | 28 | 904 | 40 |
| q4_0 | 974 | 28 | 903 | 39 |
| q4_1 | - | - | 905 | 39 |
| iq4_nl | - | - | - | - |
闪存注意力
| flash-attn | ROCm pp | ROCm tg | Vulkan pp | Vulkan tg |
|---|---|---|---|---|
| 开启 | 976 | 29 | 908 | 40 |
| 关闭 | 964 | 29 | 902 | 40 |
| 自动 | 977 | 29 | 908 | 40 |
批次大小扫描
| batch | ROCm pp | ROCm tg | Vulkan pp | Vulkan tg |
|---|---|---|---|---|
| 256 | 914 | 29 | 832 | 40 |
| 512 | 976 | 29 | 907 | 40 |
| 1024 | 976 | 29 | 904 | 40 |
| 2048 | 976 | 29 | 905 | 40 |
| 4096 | 977 | 29 | 907 | 40 |
服务器基准测试(llama-server,7 token 提示词,100 生成 token)
Vulkan 后端
| 配置 | pp(t/s) | tg(t/s) | 草稿接受数 | 接受率 |
|---|---|---|---|---|
| 基线(无推测解码) | 39.5 | 39.7 | - | - |
| MTP n=2 | 29.4 | 63.6 | 58/81 | 72% |
| MTP n=4 | 31.2 | 62.1 | 52/75 | 69% |
| MTP n=8 | 29.4 | 60.5 | 45/68 | 66% |
| MTP n=16 | 28.1 | 58.0 | 38/60 | 63% |
| MTP n=32 | 27.3 | 53.2 | 32/55 | 58% |
ROCm 后端
| 配置 | pp(t/s) | tg(t/s) | 草稿接受数 | 接受率 |
|---|---|---|---|---|
| 基线(无推测解码) | 50.8 | 29.5 | - | - |
| MTP n=2 | 24.2 | 46.2 | 58/81 | 72% |
| MTP n=8 | 23.1 | 43.5 | 36/93 | 39% |
| MTP n=16 | 22.5 | 41.0 | 30/80 | 38% |
| MTP n=32 | 21.8 | 38.5 | 25/70 | 36% |
长上下文(Vulkan MTP n=2,Q4 KV 缓存)
| 配置 | pp(t/s) | tg(t/s) | 草稿接受数 | 接受率 |
|---|---|---|---|---|
| 128K 上下文 | 31.5 | 67.5 | 30/36 | 83% |
| 256K 上下文 | 31.2 | 67.4 | 30/36 | 83% |
推荐启动命令
/home/david/Downloads/llama.cpp/vulkan/bin/llama-server \
-m /home/david/model/llm/qwen3.6-27b/Qwen3.6-27B-Q4_K_M-mtp.gguf \
-ngl 999 \
-c 131072 \
--spec-type draft-mtp --spec-draft-n-max 2 \
-ctk q4_0 -ctv q4_0
关键结论
- Vulkan 优于 ROCm:Vulkan 生成速度快 38%(MTP 下 63.6 vs 46.2 t/s)
- MTP n=2 最佳点:72% 草稿接受率,生成速度提升 +60%
- KV 缓存 Q4_0:无性能损失,相比 f16 节省 4 倍内存
- 长上下文正常工作:完整 256K 上下文运行速度与 4K 相同
- ~67 t/s:在 27B 模型上使用 MTP 实现出色的生成吞吐量
llama-bench 测试结果(2026-5-11)
环境
- MTP 模型: Qwen3.6-27B-Q4_K_M-mtp.gguf (15.82 GiB) https://huggingface.co/froggeric/Qwen3.6-27B-MTP-GGUF/
- 非MTP 模型: Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-Q4_K_P.gguf (17 GiB) https://huggingface.co/HauhauCS/Qwen3.6-27B-Uncensored-HauhauCS-Aggressive
- GPU: AMD Radeon RX 7900 XTX (24,560 MiB 显存)
- CPU: Genuine Intel(R) 13900hk ES
- 线程数: 8
- n-gpu-layers: 999 (完全卸载到 GPU)
- 温度: 0.7, top-k: 20
ROCm (HIP) - KV缓存类型对比 (非MTP)
二进制: ~/llama.cpp/rocm/bin/llama-bench (build 9046)
| KV缓存类型 | pp1024 (token/s) | tg128 (token/s) |
|---|---|---|
| f16 (默认) | 904.50 | 28.99 |
| q4_0 | 898.01 | 28.81 |
Vulkan - KV缓存类型对比 (非MTP)
标准构建 (~/Downloads/llama.cpp/build-vulkan/bin/llama-bench)
| KV缓存类型 | pp512 (token/s) | tg128 (token/s) |
|---|---|---|
| f16 | 765.94 | 37.06 |
| Q4_0 | 769.82 | 37.17 |
| Q8_0 | 273.25 | 37.13 |
Turboquant 构建 (~/Downloads/llama-cpp-turboquant/build-vulkan/bin/llama-bench)
| KV缓存类型 | pp512 (token/s) | tg128 (token/s) |
|---|---|---|
| turbo2 | 193.43 ± 1.49 | 23.79 ± 0.17 |
| turbo3 | 128.44 ± 1.31 | 21.88 ± 0.14 |
| turbo4 | 178.94 ± 2.03 | 23.00 ± 0.25 |
注意:turboquant 测试期间 GPU 使用率仅约 30%,未能充分利用 GPU。瓶颈可能在 CPU 端的量化/反量化操作。
q4_0/q8_0 在 turboquant 构建的 llama-bench 中仍然失败。
Vulkan + MTP
二进制: ~/llama.cpp/vulkan/bin/llama-cli
命令: --spec-type mtp --spec-draft-n-max 3 --parallel 1 -p "tell me a jok" -n 128 -ngl 999
注意:MTP 使用
-np 1(单并行序列),因此无法并行处理。草稿模型顺序执行,限制了吞吐量。
| 配置 | 生成速度 (token/s) |
|---|---|
| 非MTP (f16) | 39.5 |
| MTP (q4_0) | 81.2 |
| MTP (q8_0) | 77.5 |
ROCm + MTP
二进制: ~/llama.cpp/rocm/bin/llama-cli 配合 LD_LIBRARY_PATH
| 配置 | 生成速度 (token/s) |
|---|---|
| 非MTP (f16) | 29.4 |
| MTP (q4_0) | 53.6 |
| MTP (turbo3) | 47.4 |
| MTP (turbo4) | 57.2 |
总结
非MTP (llama-bench)
| KV缓存类型 | pp (token/s) | tg128 (token/s) | 后端 |
|---|---|---|---|
| f16 | 904.50 | 28.99 | ROCm (pp1024) |
| q4_0 | 898.01 | 28.81 | ROCm (pp1024) |
| f16 | 765.94 | 37.06 | Vulkan 标准 (pp512) |
| Q4_0 | 769.82 | 37.17 | Vulkan 标准 (pp512) |
| Q8_0 | 273.25 | 37.13 | Vulkan 标准 (pp512) |
| turbo2 | 193.43 | 23.79 | Vulkan turboquant (pp512) |
| turbo4 | 178.94 | 23.00 | Vulkan turboquant (pp512) |
| turbo3 | 128.44 | 21.88 | Vulkan turboquant (pp512) |
MTP (llama-cli)
| 配置 | 生成速度 (token/s) | 后端 |
|---|---|---|
| MTP (q4_0) | 81.2 | Vulkan |
| MTP (q8_0) | 77.5 | Vulkan |
| MTP (turbo4) | 57.2 | ROCm |
| MTP (q4_0) | 53.6 | ROCm |
| MTP (turbo3) | 47.4 | ROCm |
| 非MTP (f16) | 39.5 | Vulkan |
| 非MTP (f16) | 29.4 | ROCm |
关键观察
- ROCm 上的 q4_0 性能与 f16 几乎相同 (898 vs 905 token/s) — 差异可忽略。
- Turboquant 类型 仅适用于 turboquant Vulkan 构建。turbo2 的提示处理最快 (193 token/s @ pp512)。各 turbo 变体的生成速度相近 (~22-24 token/s)。
- 标准 Vulkan 构建 支持 Q4_0/Q8_0 — Q4_0 与 f16 速度相当 (~770 token/s pp512),Q8_0 提示处理慢约 2.8 倍 (273 token/s) 但生成速度相同 (~37 token/s)。Turbo 类型仅适用于 turboquant 构建。
- MTP 显著提升生成速度:Vulkan+q4_0 达到 81.2 token/s(比非MTP 提升 +106%),Vulkan+q8_0 达到 77.5 token/s (+96%),ROCm+turbo4 达到 57.2 token/s (+95%)。
 首选
首选
 ️ 重要:DFlash / PFlash 不能直接用 llama-server 启动。
️ 重要:DFlash / PFlash 不能直接用 llama-server 启动。
 `
`