
@566656661 这卡待机功耗也太高了,两张100w,在旁边闷热闷热的
E
ezios
@ezios
-
【国产替代】智铠100 32Gx2部署Qwen3.6-35B-W4A8含多并发测试结果 -
【国产替代】智铠100 32Gx2部署Qwen3.6-35B-W4A8含多并发测试结果@566656661 我这里是个台式机,推理卡也是改了涡轮散热,太神奇了

-
【国产替代】智铠100 32Gx2部署Qwen3.6-35B-W4A8含多并发测试结果@terry 已修改,拆分成两个表格,看着会舒服一些

-
双 3090(NVLink)跑 Qwen3.6-27B,128K 上下文实测@applejuice 架子65,延长线贵延长线要¥69,30厘米的
nvlink是卖显卡那个二手店套餐送的
-
双 3090(NVLink)跑 Qwen3.6-27B,128K 上下文实测@qw-er
不如买个架子

-
2x2080ti nvlink到祸了。想问问大家有没有测试LLM脚本我看得github项目,vllm啥的都是一条龙配好的。但是bench跑不起来,我想测试一下输出速度
-
【国产替代】智铠100 32Gx2部署Qwen3.6-35B-W4A8含多并发测试结果这家伙跟arc一样,待机功耗奇高,ixsmi官方工具查看显示待机功耗达到了45-50w。我在旁边调试,快热死我了
-
【国产替代】智铠100 32Gx2部署Qwen3.6-35B-W4A8含多并发测试结果1. 说明

双智铠100算力卡运行大模型的测试情况,当前已完整形成性能测试结果的模型为:Qwen3.6-35B-A3B-W4A8
并且opencode接入了该模型使用,非常快

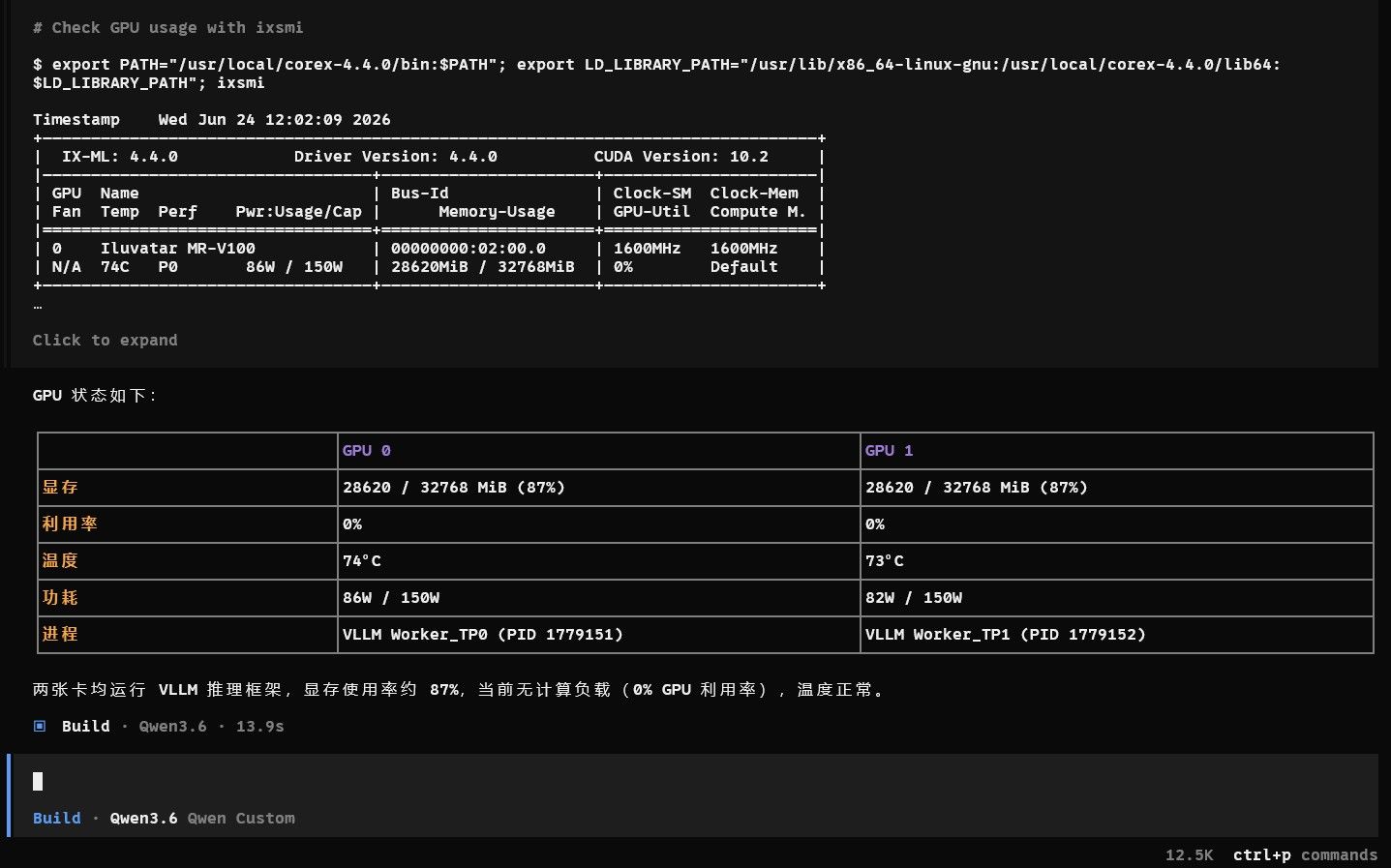
2. 测试对象
硬件对象:双智铠100算力卡。
推理框架:vLLM。
接口协议:OpenAI Chat Completions API。
主要测试接口:
http://127.0.0.1:10030/v1/chat/completions主要测试模型:
Qwen3.6-35B-A3B-W4A8模型路径:
/data/model/Qwen3___6-35B-A3B-W4A83. Qwen3.6-35B-A3B-W4A8 启动命令
3.1 日常交互启动命令
该配置适合低并发、普通上下文和长上下文测试。
export VLLM_RPC_TIMEOUT=50000 export VLLM_ENFORCE_CUDA_GRAPH=1 export VLLM_W8A8_MOE_USE_W4A8=1 export VLLM_KV_DISABLE_CROSS_GROUP_SHARE=1 vllm serve /data/model/Qwen3___6-35B-A3B-W4A8 \ --trust-remote-code \ --tensor-parallel-size 2 \ --max-num-seqs 4 \ --enable-chunked-prefill \ --max-model-len 65536 \ --reasoning-parser qwen3 \ --enable-auto-tool-choice \ --tool-call-parser qwen3_coder \ --host 0.0.0.0 \ --port 10030 \ --gpu-memory-utilization 0.90 \ --served-model-name Qwen3.6-35B-A3B-W4A8 \ --compilation-config '{"cudagraph_mode": "FULL_DECODE_ONLY", "level": 0}' \ --default-chat-template-kwargs '{"enable_thinking": false}'3.2 吞吐压测启动命令
该配置用于 6、8、12 并发测试,主要观察吞吐上限和过载边界。
export VLLM_RPC_TIMEOUT=50000 export VLLM_ENFORCE_CUDA_GRAPH=1 export VLLM_W8A8_MOE_USE_W4A8=1 export VLLM_KV_DISABLE_CROSS_GROUP_SHARE=1 vllm serve /data/model/Qwen3___6-35B-A3B-W4A8 \ --trust-remote-code \ --tensor-parallel-size 2 \ --max-num-seqs 12 \ --enable-chunked-prefill \ --max-model-len 65536 \ --reasoning-parser qwen3 \ --enable-auto-tool-choice \ --tool-call-parser qwen3_coder \ --host 0.0.0.0 \ --port 10030 \ --gpu-memory-utilization 0.90 \ --served-model-name Qwen3.6-35B-A3B-W4A8 \ --compilation-config '{"cudagraph_mode": "FULL_DECODE_ONLY", "level": 0}' \ --default-chat-template-kwargs '{"enable_thinking": false}'4. 测试命令模板
4.1 单并发普通上下文测试
vllm bench serve \ --backend openai-chat \ --base-url http://127.0.0.1:10030 \ --endpoint /v1/chat/completions \ --model Qwen3.6-35B-A3B-W4A8 \ --tokenizer /data/model/Qwen3___6-35B-A3B-W4A8 \ --dataset-name random \ --random-input-len 2048 \ --random-output-len 512 \ --num-prompts 20 \ --request-rate inf \ --max-concurrency 1 \ --ignore-eos \ --seed 1234.2 普通上下文多并发测试
将
--max-concurrency分别设置为4、6、8、12。vllm bench serve \ --backend openai-chat \ --base-url http://127.0.0.1:10030 \ --endpoint /v1/chat/completions \ --model Qwen3.6-35B-A3B-W4A8 \ --tokenizer /data/model/Qwen3___6-35B-A3B-W4A8 \ --dataset-name random \ --random-input-len 4096 \ --random-output-len 512 \ --num-prompts 50 \ --request-rate inf \ --max-concurrency 8 \ --ignore-eos \ --seed 123说明:4 并发测试时,实际提供的测试请求数为 10;6、8、12 并发测试请求数为 50。
4.3 长上下文测试
vllm bench serve \ --backend openai-chat \ --base-url http://127.0.0.1:10030 \ --endpoint /v1/chat/completions \ --model Qwen3.6-35B-A3B-W4A8 \ --tokenizer /data/model/Qwen3___6-35B-A3B-W4A8 \ --dataset-name random \ --random-input-len 16384 \ --random-output-len 512 \ --num-prompts 20 \ --request-rate inf \ --max-concurrency 2 \ --ignore-eos \ --seed 1235. Qwen3.6-35B-A3B-W4A8 测试结果总表
表格 1:基础信息与吞吐量
测试场景 输入/输出 tokens 并发 请求数 成功数 失败数 总耗时 输出吞吐 (tok/s) 总吞吐 (tok/s) 单并发普通上下文 2048 / 512 1 20 20 0 181.81s 56.32 281.61 4 并发普通上下文 4096 / 512 4 10 10 0 44.94s 113.93 1025.39 6 并发普通上下文 4096 / 512 6 50 50 0 172.87s 148.09 1332.81 8 并发普通上下文 4096 / 512 8 50 50 0 149.76s 170.94 1538.48 12 并发普通上下文 4096 / 512 12 50 50 0 236.90s 108.06 972.58 长上下文 16384 / 512 2 20 20 0 192.28s 53.26 1757.45 表格 2:延迟指标(TTFT / TPOT / ITL)
测试场景 平均 TTFT P99 TTFT 平均 TPOT P99 TPOT P99 ITL 单并发普通上下文 675.33ms 684.19ms 16.47ms 16.59ms 17.21ms 4 并发普通上下文 2539.73ms 4174.28ms 25.62ms 28.45ms 24.38ms 6 并发普通上下文 2812.72ms 5848.28ms 33.38ms 36.07ms 508.41ms 8 并发普通上下文 3110.26ms 8321.04ms 38.25ms 41.46ms 515.14ms 12 并发普通上下文 3593.71ms 12122.58ms 100.03ms 106.45ms 524.32ms 长上下文 6423.67ms 8687.50ms 25.04ms 28.39ms 22.67ms 6. 每用户体感输出速度
每用户体感输出速度按以下公式估算:
每用户输出速度 ≈ 1000 / 平均 TPOT(ms)测试场景 平均 TPOT 估算每用户输出速度 单并发普通上下文 16.47ms 约 60.72 tok/s 4 并发普通上下文 25.62ms 约 39.03 tok/s 6 并发普通上下文 33.38ms 约 29.96 tok/s 8 并发普通上下文 38.25ms 约 26.14 tok/s 12 并发普通上下文 100.03ms 约 10.00 tok/s 长上下文 25.04ms 约 39.94 tok/s 补充:
配置信息
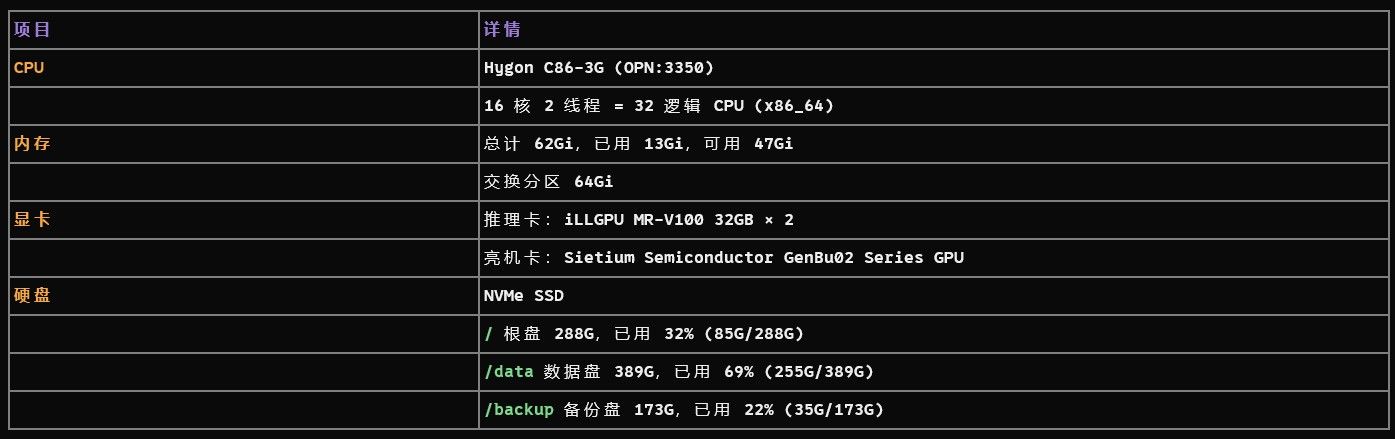
价格
公司订购的一台测试机子,工作站样式,外壳应该是铝的定制的;整机5w多。我看淘宝上同款推理卡mr-100一张1.5w左右
-
(双卡指南) 最丐 Qwen3.6-27b - 3000 元双 RTX 3060 - 50t/s@stakira 我看两三百块钱转换器吧,加上再买一张显卡2k出头就下来了
-
(双卡指南) 最丐 Qwen3.6-27b - 3000 元双 RTX 3060 - 50t/s我打算2080ti 22g x2走nvlink了;我看有人说第二张卡pciex1就够
-
【RTX4060】【8G显存】运行Qwen3.6 35B A3B APEX-MTP包含两种方式及测试结果@Tony-Hu cpu线程数你电脑是多少,卸载层数先从40 或者35试试
-
来交作业了,华南金牌X99套装+RTX3090Ti+RTX3060双卡装机完毕prefill速度多少
-
8G显存 篇。RTX3070 8G显存。成功跑 Qwen3.6-35B 多模态AI大模型 ,你试试我的帖子里面的apex mtp模型,速度还能提升
,你试试我的帖子里面的apex mtp模型,速度还能提升 -
虽迟但到,交作业了确实移动有大毒,我父母那是移动的,wg通了就是连不上rdp,我换成4g就好了,md
-
2080Ti 22G魔改版+llama.cpp pr-22673开启MTP Chat场景TPS提升20%左右@Tony-Wang 看来没啥好优化的了,但是没得说,27b干活是真爽
-
2080Ti 22G魔改版+llama.cpp pr-22673开启MTP Chat场景TPS提升20%左右@davidwei0826 我跟你这差不多,看来到极限了
-
RTX3080 20g,qwen3.6 27B 60-40T/S 本地爽玩配置@vosrock 我认为35B你那个配置还可以优化,不应该只有500,Hermes我刚试了2080ti,35B很快就回答了,后台扫了一眼日志,应该是上千的。我是2080ti,并且是用USB4接的显卡,输出只有45tokens/s
不过我是llamacpp跑的:
version = 1 [*] parallel = 1 n-gpu-layers = 999 ctx-size = 131072 predict = 8192 flash-attn = on cache-type-k = q4_0 cache-type-v = q4_0 threads = 8 threads-batch = 16 batch-size = 8192 ubatch-size = 512 jinja = true reasoning = off reasoning-budget = 0 cache-prompt = true cache-reuse = 256 kv-offload = true kv-unified = true context-shift = true no-mmap = true temp = 0.7 top-p = 0.9 top-k = 40 min-p = 0.0 presence-penalty = 0.0 repeat-penalty = 1.03 load-on-startup = true stop-timeout = 10 [default] model = C:\models\Qwopus3.6-35B-A3B-v1-APEX-MTP-I-Compact.gguf spec-type = draft-mtp spec-draft-n-max = 2 cache-type-k-draft = q4_0 cache-type-v-draft = q4_0 -
2080Ti 22G魔改版+llama.cpp pr-22673开启MTP Chat场景TPS提升20%左右请问27B的prompt处理速度是多少?我现在峰值600,慢慢就到500左右了,体感不好。35BA3B可以上千。按理说都在显存里,应该很快呀。
Q4KM的还行,UD的不行,说多了爆显存
version = 1 [*] parallel = 1 n-gpu-layers = 999 ctx-size = 65536 predict = 8192 flash-attn = on cache-type-k = q4_0 cache-type-v = q4_0 threads = 8 threads-batch = 16 batch-size = 8192 ubatch-size = 512 jinja = true reasoning = off reasoning-budget = 0 cache-prompt = true cache-reuse = 256 kv-offload = true kv-unified = true context-shift = true no-mmap = true temp = 0.6 top-p = 0.9 top-k = 40 min-p = 0.0 presence-penalty = 0.0 repeat-penalty = 1.03 load-on-startup = false stop-timeout = 10 [default] model = C:\models\Qwen3.6-27B-Q4_K_M.gguf ; 128k ctx-size = 131072 spec-type = draft-mtp spec-draft-n-max = 2 cache-type-k-draft = q4_0 cache-type-v-draft = q4_0 batch-size = 8192 ubatch-size = 1024 [qwen36-27b-ud-q4k-xl-hermes-fast-read] model = C:\models\Qwen3.6-27B-UD-Q4_K_XL.gguf ; 128k ctx-size = 131072 spec-type = draft-mtp spec-draft-n-max = 1 cache-type-k-draft = q4_0 cache-type-v-draft = q4_0 batch-size = 16384 ubatch-size = 1024 -
【RTX4060】【8G显存】运行Qwen3.6 35B A3B APEX-MTP包含两种方式及测试结果@R-simi-Kangtao 你可以试一下我这个模型,我认为对于你的卡是有提升的,对于4060提升有限
-
我的ai硬件方案分享你好,最近我在考虑2080ti22g,请问你这种跑法是不是35BA3B量化都放到显卡里面了?你跑过27B吗,效果怎么样