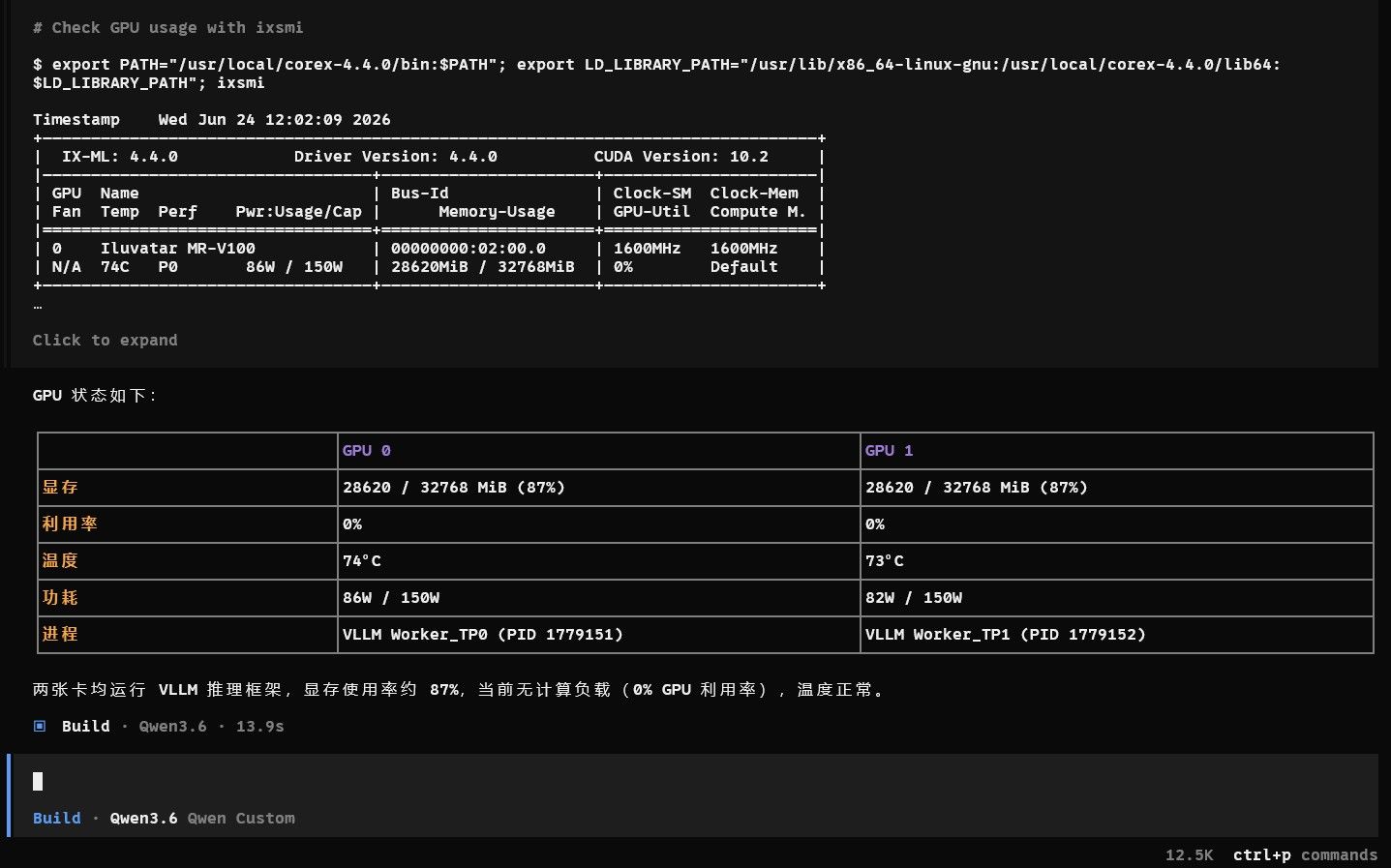
跑的是这个模型Qwen3.6 35B A3B APEX-MTP
Qwen3.6-35B-A3B-APEX-MTP-I-Mini.gguf -》13.7 GB
我是个刚开始研究本地部署LLM的小白,因此运行步骤和过程基于GPT5.5 CHAT辅助实现。

省流:
- 台式机和USB4拓展坞都可以跑在8g显存的显卡上,MTP的速度挺快的,30+tokens/s,代码能跑到45-50
- 因为显存不够,上下文prompt太多了以后处理起来很慢,拓展坞情况比我的台式机慢3-4倍
补充:
- 台式机后续尝试了I-Compact和I-Quality,发现速度有下降,但是不明显
- 4060还是玩9B吧...跑起来还快点,当然不嫌慢,等这个慢慢跑也行(我记得特总视频也提过这一点)
以下是GPT总结的过程:
Qwen3.6 35B A3B APEX-MTP 本地运行测试总结
测试目标:验证
Qwen3.6-35B-A3B-APEX-MTP-I-Mini.gguf在本地消费级硬件上的可用性、运行效率、上下文设置、MTP 效果,以及台式机与 USB4 外接显卡笔记本之间的差异。
1. 测试模型
本次测试模型:
Qwen3.6-35B-A3B-APEX-MTP-I-Mini.gguf
模型关键词:
Qwen3.6 35B A3B
MoE 架构
APEX 量化
MTP 单文件自投机解码
GGUF 格式
llama.cpp 运行
本次测试的核心结论是:
该模型可以在单张 RTX 4060 8GB 上运行。
通过 CPU MoE + APEX 量化 + MTP,自建本地代码 Agent 服务是可行的。
台式机 PCIe 内置显卡明显优于笔记本 USB4 外接显卡,尤其是在长上下文 prompt processing 阶段。
2. 运行方式
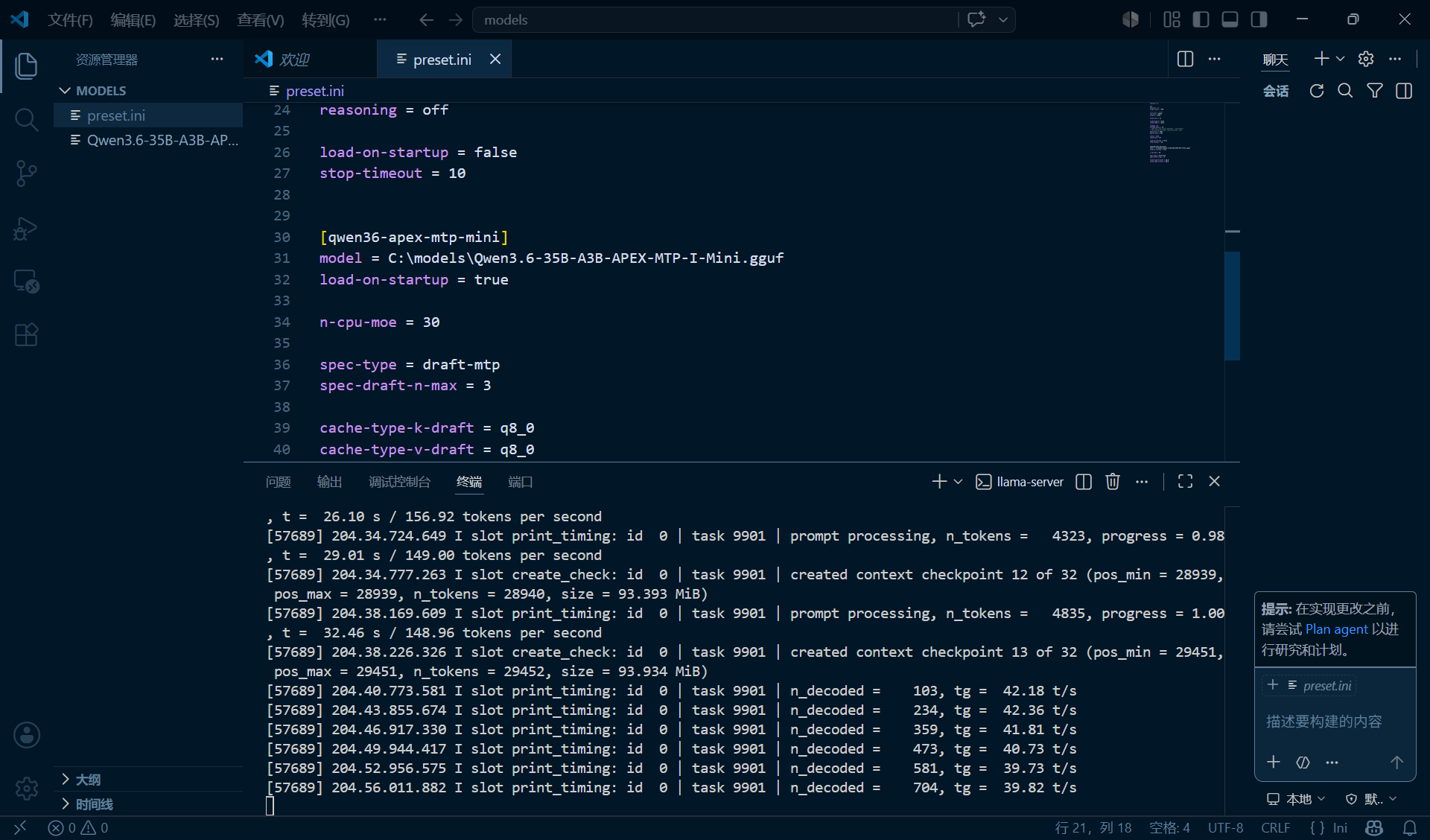
最终采用的运行方式:
Windows 版 llama.cpp 预编译 CUDA 12.4 包
llama-server
OpenAI-compatible API
models-preset INI 配置
启动方式示例:
.\llama-server.exe `
--models-preset C:\models\preset.ini `
--host 0.0.0.0 `
--port 8888
服务地址:
http://127.0.0.1:8888/v1
适合接入:
Hermes
ASRBot
OpenAI-compatible 客户端
自写 py-llmcli
其他 Agent / IDE / CLI 工具
3. 台式机测试环境
3.1 硬件配置
CPU:AMD Ryzen 7 5700X
内存:DDR4 3200 16GB × 4,共 64GB
显卡:RTX 4060 8GB
连接方式:台式机主板 PCIe 内置连接
3.2 台式机 llama.cpp 预设
version = 1
[*]
parallel = 1
n-gpu-layers = 999
ctx-size = 16384
predict = 4096
flash-attn = on
cache-type-k = q8_0
cache-type-v = q8_0
threads = 8
threads-batch = 16
batch-size = 1024
ubatch-size = 512
jinja = true
reasoning = off
no-mmap = true
load-on-startup = false
stop-timeout = 10
[qwen36-apex-mtp-mini]
model = C:\models\Qwen3.6-35B-A3B-APEX-MTP-I-Mini.gguf
ctx-size = 65536
load-on-startup = true
n-cpu-moe = 32
spec-type = draft-mtp
spec-draft-n-max = 3
cache-type-k-draft = q8_0
cache-type-v-draft = q8_0
3.3 台式机表现
台式机表现明显更好,尤其是长 prompt 输入处理阶段。
典型日志表现:
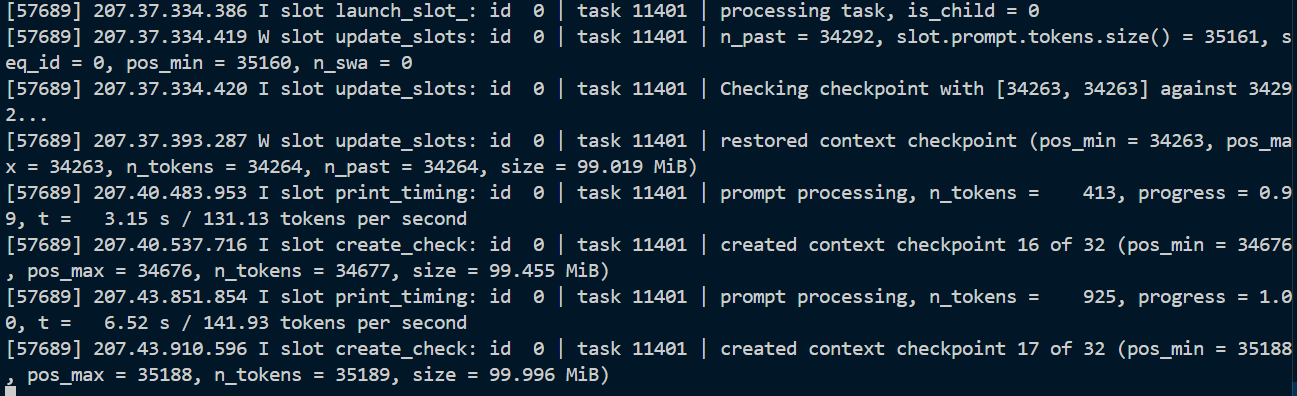
prompt eval time ≈ 29640 ms / 14791 tokens
prompt processing ≈ 499 tok/s
生成阶段在长输出测试中也能达到较高速度:
eval ≈ 35~38 tok/s
MTP acceptance rate 较高时,输出体验很好
3.4 台式机定位
台式机适合作为主力本地模型服务端:
Hermes 主力服务端
代码 Agent
OpenAI 兼容 API 服务
长上下文代码分析
RAG 问答
ASRBot 后端大模型
本地开发辅助
推荐保留台式机作为主要模型服务机器。
4. 笔记本测试环境
4.1 硬件配置
型号:HP 战X 2022
CPU:AMD Ryzen 7 6850HS
内存:DDR5 4800 16GB × 2,共 32GB
显卡:RTX 4060 8GB
连接方式:USB4 外接 RTX 4060
4.2 笔记本 llama.cpp 预设
version = 1
[*]
parallel = 1
n-gpu-layers = 999
#ctx-size = 16384
ctx-size = 65536
predict = 8192
flash-attn = on
cache-type-k = q8_0
cache-type-v = q8_0
threads = 8
threads-batch = 16
batch-size = 1024
ubatch-size = 512
jinja = true
reasoning = off
load-on-startup = false
stop-timeout = 10
[qwen36-apex-mtp-mini]
model = C:\models\Qwen3.6-35B-A3B-APEX-MTP-I-Mini.gguf
load-on-startup = true
n-cpu-moe = 30
spec-type = draft-mtp
spec-draft-n-max = 3
cache-type-k-draft = q8_0
cache-type-v-draft = q8_0
4.3 笔记本表现
笔记本可以运行该模型,但长上下文和 Agent 场景明显慢于台式机。
之前测试中,笔记本 USB4 外接 RTX 4060 时,长 prompt processing 大约为:
prompt processing ≈ 168 tok/s
与台式机约 499 tok/s 相比,差距接近 3 倍。
4.4 笔记本变慢的主要原因
主要不是 RTX 4060 算力本身问题,而是以下因素叠加:
1. USB4 eGPU 带宽和延迟弱于台式机 PCIe。
2. Qwen3.6 35B A3B 当前依赖 CPU MoE,CPU/GPU 协作频繁。
3. 6850HS 是移动端 CPU,持续功耗、散热、内存带宽不如台式机 5700X 稳定。
4. 笔记本内存为 32GB,64K 上下文 + prompt cache + CPU MoE 时余量更小。
4.5 笔记本定位
笔记本适合移动测试、轻量任务,不建议作为主力 Hermes 服务端。
更适合:
普通聊天
短上下文代码问答
轻量开发辅助
16K~32K 上下文任务
小模型或 dense 模型测试
如果笔记本继续运行该 35B A3B 模型,建议更保守:
ctx-size = 32768
predict = 4096
n-cpu-moe = 35
cache-type-k = q8_0
cache-type-v = q8_0
5. 关键参数理解
5.1 ctx-size
ctx-size 控制上下文窗口大小。
本次测试结论:
16K:普通问答、短代码够用。
32K:Hermes 轻量任务更合适。
64K:台式机可用,适合代码 Agent 和长上下文。
128K/262K:单张 RTX 4060 不建议默认开启。
当前台式机建议:
ctx-size = 65536
笔记本建议:
ctx-size = 32768
如确实需要 64K,笔记本也可以运行,但需要接受 prompt processing 变慢。
5.2 predict
predict 控制最大输出 token 数。
本次测试中发现:
predict = 4096 时速度更稳。
predict = 8192 可以输出更长内容,但响应时间会明显变长。
代码写不完时,不建议长期依赖超大 predict,而应让 Agent 分文件、分阶段输出。
推荐:
predict = 4096
需要长代码时可临时使用:
predict = 8192
但最好配合任务拆分:
先生成 Controller
再生成 Service
再生成 Mapper
再生成测试代码
5.3 n-cpu-moe
n-cpu-moe 控制前 N 层 MoE 专家放在 CPU。
当前测试结论:
n-cpu-moe 太低会让更多专家进 GPU,显存占用上升,但不一定更快。
显存占用从 4GB 拉到 7.4GB 后,tokens/s 反而下降到约 25 tok/s。
CPU MoE 在 RTX 4060 8GB 上不是坏事,反而是该模型能跑快的关键。
台式机当前推荐:
n-cpu-moe = 32
笔记本建议:
n-cpu-moe = 35
如果某个配置显存接近 7.5GB 且速度下降,应回退到更高的 n-cpu-moe。
5.4 MTP
MTP 参数:
spec-type = draft-mtp
spec-draft-n-max = 3
本次测试中,MTP 有明显收益。日志中出现过较高 draft acceptance rate,例如:
draft acceptance rate ≈ 0.64~0.88
判断:
MTP 生效。
MTP 对输出速度有帮助。
不建议关闭。
5.5 KV Cache
当前使用:
cache-type-k = q8_0
cache-type-v = q8_0
cache-type-k-draft = q8_0
cache-type-v-draft = q8_0
测试结论:
q8_0 稳定性和质量更好。
如果 64K 上下文显存压力较大,可以考虑 q4_0。
当前台式机使用 q8_0 可接受。
如果显存不足,可改成:
cache-type-k = q4_0
cache-type-v = q4_0
cache-type-k-draft = q4_0
cache-type-v-draft = q4_0
5.6 parallel
当前设置:
parallel = 1
本地个人使用和代码 Agent 推荐保持 1。
原因:
减少 KV cache 压力。
减少并发 slot 占用。
更适合长上下文和长输出。
6. Hermes 接入结论
该模型适合接入 Hermes,但需要注意上下文管理。
6.1 接入地址
base_url = http://127.0.0.1:8888/v1
model = qwen36-apex-mtp-mini
api_key = local
6.2 Hermes 推荐使用方式
推荐:
台式机作为 Hermes 主力服务端。
64K context。
predict 4096。
按任务分阶段生成代码。
控制工具输出长度。
不要让 Hermes 每轮塞入过多日志和无关文件。
6.3 Hermes 性能瓶颈
Hermes 场景下最主要的瓶颈不是输出速度,而是 prompt processing。
当 Hermes 每轮发送 20K~30K tokens 时,即便模型生成速度很快,也会在每轮开始前等待较长时间。
优化重点:
减少每轮 prompt tokens 数量。
提高 prompt cache/LCP 命中率。
减少工具输出长度。
避免把完整日志、完整项目、无关历史反复塞回上下文。
7. 台式机与笔记本分工建议
7.1 台式机
建议作为主力:
Qwen3.6 35B A3B APEX-MTP
64K 上下文
Hermes
代码 Agent
ASRBot 后端模型
RAG / 文档问答
推荐配置:
ctx-size = 65536
predict = 4096
n-cpu-moe = 32
parallel = 1
KV = q8_0
MTP = draft-mtp
7.2 笔记本
建议作为移动测试或轻量环境:
普通聊天
轻量代码问答
短上下文任务
小模型测试
推荐配置:
ctx-size = 32768
predict = 4096
n-cpu-moe = 35
parallel = 1
KV = q8_0
MTP = draft-mtp
如果笔记本需要长期运行本地 LLM,更建议使用:
Qwen3.5 9B
7B / 8B / 9B dense coder 模型
能完整放进 RTX 4060 8GB 显存的模型
这类模型在 USB4 eGPU 下受 CPU MoE 和链路瓶颈影响更小。
8. 最终结论
本次测试可以形成以下结论:
1. Qwen3.6 35B A3B APEX-MTP I-Mini 在单张 RTX 4060 8GB 上可用。
2. APEX 降低了模型体积,MTP 明显提升了输出速度。
3. CPU MoE 是该模型能在 8GB 显存上运行的关键。
4. 台式机 PCIe RTX 4060 明显优于笔记本 USB4 外接 RTX 4060。
5. Hermes / 代码 Agent / 长上下文任务应优先跑在台式机上。
6. 笔记本可以跑,但更适合轻量任务或小模型。
7. 当前台式机配置可作为本地代码 Agent 主力方案。
最终推荐部署策略:
台式机:
Qwen3.6 35B A3B APEX-MTP I-Mini
64K context
predict 4096
作为 Hermes / 代码 Agent 主力服务端
笔记本:
优先使用 16K~32K context
或改用 Qwen3.5 9B 等更小 dense 模型
作为移动轻量环境
9. 后续可继续优化方向
后续如果继续优化,可以关注:
1. 对比 n-cpu-moe = 32 / 35 的实际 tok/s 和显存占用。
2. 测试 ctx-size = 32768 与 65536 在 Hermes 中的实际等待差异。
3. 测试 predict = 4096 与 8192 对代码任务完成度的影响。
4. 优化 Hermes 工具输出和上下文压缩策略。
5. 为台式机和笔记本分别维护独立 preset.ini。
6. 尝试 Qwen3.5 9B dense 模型作为笔记本轻量主力。
7. 后续如果升级 24GB 显卡,可重新评估 Qwen3.6 35B A3B 更高量化版本或更少 CPU MoE。