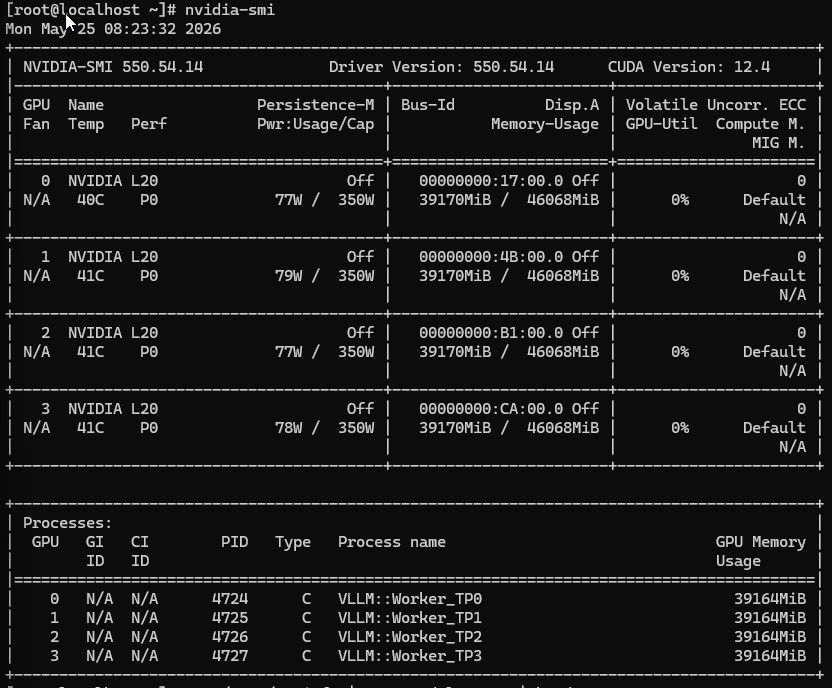
GPU: 4× NVIDIA L20 (48GB each, Ada Lovelace, sm_89)
CPU: 4× L20 = 192GB 总显存 (用了 33GB / 18%)
RAM: 251GB
存储: /home 2.5TB 可用
驱动: NVIDIA 550.54.14
OS: CentOS 7.9
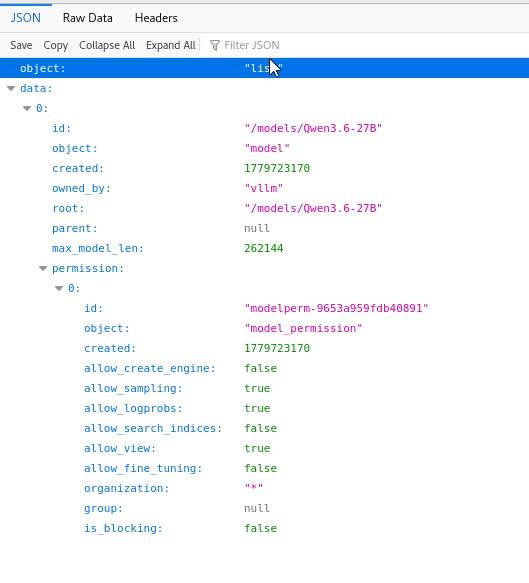
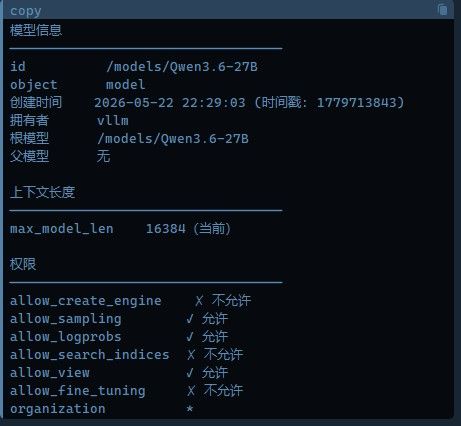
Model: Qwen3.6-27B-FP8 (基础架构 qwen3_5_text, hybrid GatedDeltaNet)
架构: 64 层, 5120 hidden, 24 attention heads, 4 KV heads
注意力: 16 × (3× GatedDeltaNet + 1× Gated Attention) (3:1 比例)
MTP: 1 个 MTP 头 (multi-token prediction)
训练 ctx: 262,144 (256K)
量化: Q5_K_XL (Unsloth Dynamic 2.0)
文件: /home/models/qwen3-27b-mtp-gguf/Qwen3.6-27B-UD-Q5_K_XL.gguf
大小: 19.0 GB
GGUF源: unsloth/Qwen3.6-27B-MTP-GGUF
主机
mkdir -p /tmp/llama-build/host-out
cd /tmp/llama-build && git clone --depth 1 https://github.com/ggml-org/llama.cpp.git
构建脚本(必须放在源码树内,容器才能看到)
cat > /tmp/llama-build/llama.cpp/build-wrapper.sh <<'EOF'
#!/bin/bash
exec >/tmp/build-out/build.log 2>&1
set -e
apt-get update -qq
apt-get install -y -qq cmake build-essential git ninja-build
cd /src/llama.cpp
rm -rf build
cmake -B build -G Ninja
-DGGML_CUDA=ON -DCMAKE_BUILD_TYPE=Release
-DCMAKE_CUDA_ARCHITECTURES='89'
-DGGML_NATIVE=OFF -DGGML_CUDA_F16=ON
-DGGML_RPC=OFF -DBUILD_SHARED_LIBS=OFF
cmake --build build -j$(nproc) --target llama-server llama-cli llama-quantize
EOF
chmod +x /tmp/llama-build/llama.cpp/build-wrapper.sh
docker run -d --name llama-cpp-build
-v /tmp/llama-build/llama.cpp:/src/llama.cpp
-v /tmp/llama-build/host-out:/tmp/build-out
-w /src/llama.cpp
nvidia/cuda:12.4.0-devel-ubuntu22.04
bash /src/llama.cpp/build-wrapper.sh
mkdir -p /home/models/qwen3-27b-mtp-gguf
nohup bash -c '
curl -L --fail --retry 5
-o /home/models/qwen3-27b-mtp-gguf/Qwen3.6-27B-UD-Q5_K_XL.gguf
"https://hf-mirror.com/unsloth/Qwen3.6-27B-MTP-GGUF/resolve/main/Qwen3.6-27B-UD-Q5_K_XL.gguf"
' > /tmp/gguf-dl.log 2>&1 &
=== 模型 ===
-m /models/Qwen3.6-27B-UD-Q5_K_XL.gguf
=== 服务 ===
--host 0.0.0.0
--port 8003
--api-key 7cd5aace-734d-4223-813c-2406506c4b0a
=== 上下文(256K 完整原生)===
-c 262144
-ngl 999 # 所有层上 GPU
=== 多 GPU 切分(2×L20)===
--split-mode layer # 按层切分
--tensor-split 0.5,0.5 # GPU 2+3 各 50%
--main-gpu 0 # 主 GPU(相对 0 = 物理 GPU 2)
=== 并发 ===
--parallel 2 # 2 路并发
--kv-unified #  ️ 关键:共享 KV 池
️ 关键:共享 KV 池
--cont-batching # 连续批处理
=== KV 量化(节省 50% 显存)===
--cache-type-k q8_0
--cache-type-v q8_0
=== MTP 投机解码(1.7-2× 加速)===
--spec-type draft-mtp # ️ 关键
--spec-draft-n-max 3 # 草稿 3 token
--draft-p-min 0.85 # 接受阈值
=== 性能优化 ===
--flash-attn auto # Flash Attention
--no-mmap --mlock # 不 mmap,锁内存
--batch-size 512
--ubatch-size 128
=== 采样 ===
--top-p 0.95 --top-k 20 --temp 0.7 --repeat-penalty 1.0
=== 模板 ===
--jinja
--chat-template-kwargs '{"enable_thinking":false}'
--reasoning off
 结论
结论
vLLM 7.5 TPS 是 L20 + Qwen3-27B-FP8 物理上限(之前我们认为无法突破)。
llama.cpp + MTP 投机解码 在相同硬件上达到 50 TPS(平均)/ 80 TPS(峰值),6.7-10.7× 加速,且能跑 256K 完整原生上下文 + 2 路并发,显存只用 33GB。
关键启示:vLLM 框架本身在 hybrid Mamba/GDN 模型上有性能瓶颈(vLLM 0.5.x 测速 7.5 TPS,0.20.1 测速 7.45 TPS,几乎一样)。要突破必须换底层框架 — llama.cpp + MTP speculative decoding 是当前唯一现实路径。