
我現在在用的就是 cyankiwi/Qwen3.6-27B-AWQ-INT4 可以正常識別圖片
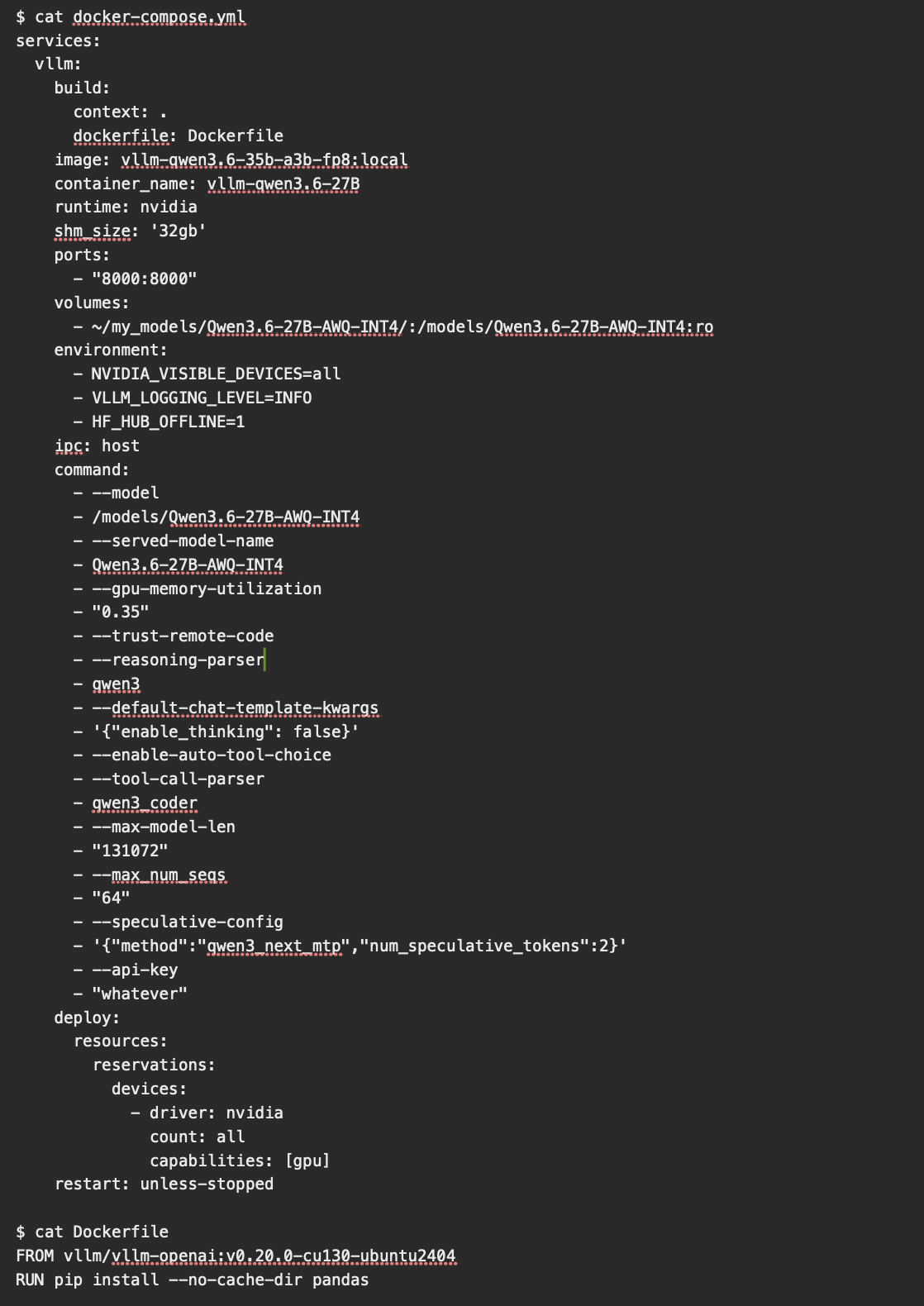
使用 Docker 部署,可以參考文件
我現在在用的就是 cyankiwi/Qwen3.6-27B-AWQ-INT4 可以正常識別圖片
使用 Docker 部署,可以參考文件
KV cache 也要吃 VRAM 啊 ,gpu-memory-utilization 要設定夠高,VRAM 不夠 max_model_len 就不能設定太大
@0xsltomorrow Ultimate Clone 沒試過太多次
使用 HTTP API 調用 生成幾次之後就變成隨機音色 女聲變男聲
再試幾天沒有改善可能要換成使用 Qwen3-TTS
只是用最新版。 是用 vllm 容器開啟模型 沒有詳細日誌 晚點再研究
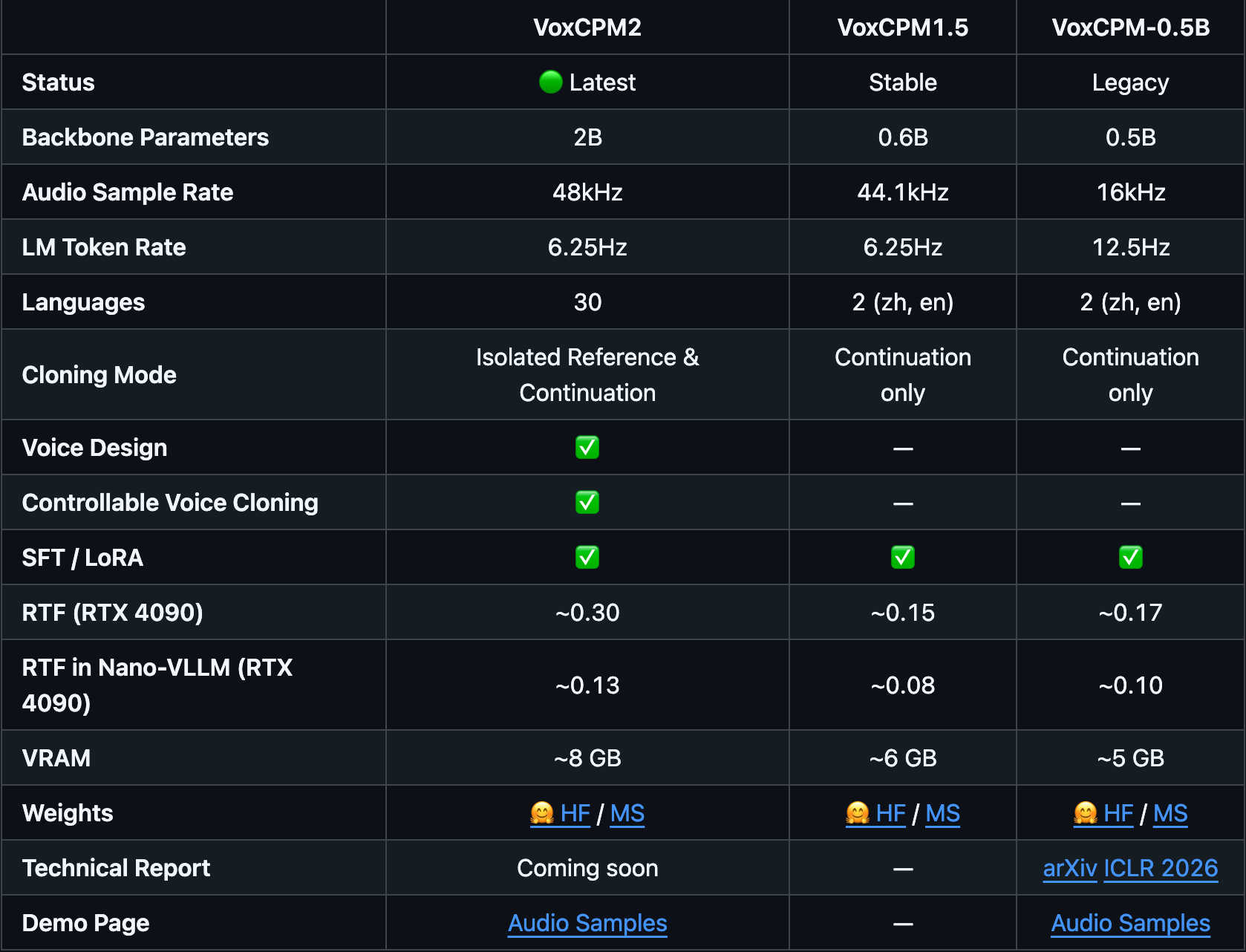
@terry 4月出 2版了。目前最新是2.0.2
想請教一下各位大神,前幾天嘗試部署 VoxCPM2
並使用語音克隆功能來給我的 Hermes 妹妹發聲
提供了約一分鐘的 wav 音頻當 reference
但是每次生成的語音音色都不太一樣,聽著很不舒服
使用極致克隆好像有 bug 更慘,生成多次後音色都變了
不知道大神們有沒有遇上這種狀況,又是如何解決?
@Tide 沒辦法選字是 terminal app 的問題吧。多試試不同的 terminal app
重點是要加載 mmproj 文件,以下是我使用的容器 docker-compose 文件,可以參考 command:
services:
llama-cpp:
image: ghcr.io/ggml-org/llama.cpp:server-cuda
container_name: llama-cpp-cuda
ports:
- "8080:8080"
volumes:
- ~/models:/models
command:
- -m
- /models/Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-Q4_K_P.gguf
- --alias
- Qwen3.6-27B-Q4_K_P
- --host
- 0.0.0.0
- --port
- "8080"
- --mmproj
- /models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf
- --n-gpu-layers
- "999"
- --jinja
- --ctx-size
- "131072"
- --chat-template-kwargs
- '{"enable_thinking": false}'
- --metrics
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]