
剛跑了qwen 3.6 27B Q8 單台DGX spark的測試供參考, 手邊沒有Q4的模型可以跑.

圖片影片的話.. 論壇上有發一篇了, 可以看看
剛跑了qwen 3.6 27B Q8 單台DGX spark的測試供參考, 手邊沒有Q4的模型可以跑.
圖片影片的話.. 論壇上有發一篇了, 可以看看
我用兩張V100 32G, qwen3.6 27B Q8模型可以到4x, reasoning模式關閉感覺智力略降, 所以雖然會拖慢一點, 我還是開著. 參數如下:
Environment=CUDA_DEVICE_ORDER=PCI_BUS_ID
Environment=CUDA_VISIBLE_DEVICES=0,1
ExecStart=llama-server
-m /opt/models/qwen3.6-27b-mtp/Qwen3.6-27B-UD-Q8_K_XL.gguf
--host 0.0.0.0
--port 9527
--alias qwen3.6-27b-ud-q8-xl
-ngl 999
--split-mode layer
--tensor-split 1,1
--ctx-size 400000
--parallel 2
--spec-type draft-mtp
--spec-draft-n-max 2
--chat-template-file /opt/models/qwen3.6-27b-mtp/chat_template.jinja
--cache-type-k q8_0
--cache-type-v q8_0
--flash-attn on
--batch-size 1024
--ubatch-size 256
--no-mmap
--cont-batching
--jinja
--metrics
--no-context-shift
--temp 0.15
--top-p 0.90
--top-k 40
--min-p 0.03
--repeat-last-n 512
--repeat-penalty 1.1
Restart=always
RestartSec=5
[Install]
WantedBy=multi-user.target
2080 ti + P40, 可以跑Qwen 3.6 27B Q4量化了
前幾天看著平常編程在用的洋垃圾, 突然想搞個顯卡來跑跑qwen 3.6 27B. 看了半天, 台灣這邊魔改卡不好買, 也都是天價. 7900XTX基本沒人在賣, R9700兩張又太貴, 就入了兩張Nvidia TESLA v100 32G來試試.
電腦本來只有BMC顯示, 所以驅動啥的都沒裝, 只有裝ubuntu 26.04.
各論壇看了看, 鎖定llama.cpp + Qwen3.6-27B-UD-Q8_K_XL.gguf , 然後把相關資料交給gemini cli去安裝, 大概一個小時它就把NVIDIA 驅動,CUDA其他相依軟件及設定搞好, llama.cpp編譯完成, 該避的坑避掉, 模型下載完然後就跑起來了, 全程無干預.
再來就是跟它花了大概兩個小時測試調整, 主要是一開始的prefill慘不忍睹, 花很多時間在長文本測試優化. 調到一個滿意的設定, 就差不多了, 整個過程還挺順利的.
底下是我電腦的基本資訊:
目前的狀態大概是這樣:
qwen36-llama.servicellama.cpp (CUDA 70架構優化編譯版)Qwen3.6-27B-UD-Q8_K_XL.gguf524,288 tokens2 路 (每路 262,144 tokens)q8_0draft-mtp, 最大預測數: 2)系統已確保 100% 的權重與 KV Cache 駐留於 VRAM 中,完全不依賴系統 RAM 進行 offload,徹底解除 PCIe 頻寬瓶頸。
以上是Gemini寫的報告, 中間有多次參數設定調整, 比較如下:
| 測試組合 | 3路 256K (無MTP) | 2路 256K (MTP 2) | 1路 256K (B256, mtp2) | 1路 256K (B512,mtp2) | 1路 256K (B1024,mtp2) | 2路 256K (B1024,mtp2) |
|---|---|---|---|---|---|---|
| 1. 成功啟動 | 是 | 是 | 是 | 是 | 是 | 是 |
| 2. VRAM Used (GPU0/1) | 27.8/31.2 GB | 23.7/29.1 GB | 19.3/23.8 GB | 19.6/24.5 GB | 19.9/25.1 GB | 24.3/30.3 GB |
| 3. Prefill (t/s) | 90.31 | 42.02 (短文) | 263.93 | 395.94 | 611.04 | 23.01 (短文) |
| 4. Generation (t/s) | 20.87 | 37.24 | 46.64 | 43.09 | 40.65 | 40.06 |
| 5. MTP 接受率 | N/A | 79% | 100% | 100% | 100% | 87.5% |
| 6. 是否 OOM | 否 | 否 | 否 | 否 | 否 | 否 |
| 7. 數據位置 | 部分 RAM | 部分 RAM | 純 VRAM | 純 VRAM | 純 VRAM | 純 VRAM |
| 8. GPU Power (0/1) | 51W/49W | 51W/49W | ~50W/50W | 52W/52W | 53W/53W | 51W/49W |
| 9. GPU Temp (0/1) | 35°C/35°C | 34°C/33°C | 35°C/35°C | 39°C/40°C | 39°C/41°C | 34°C/34°C |
定案之後看了一下vram占用狀態跟跑一下benchmark:
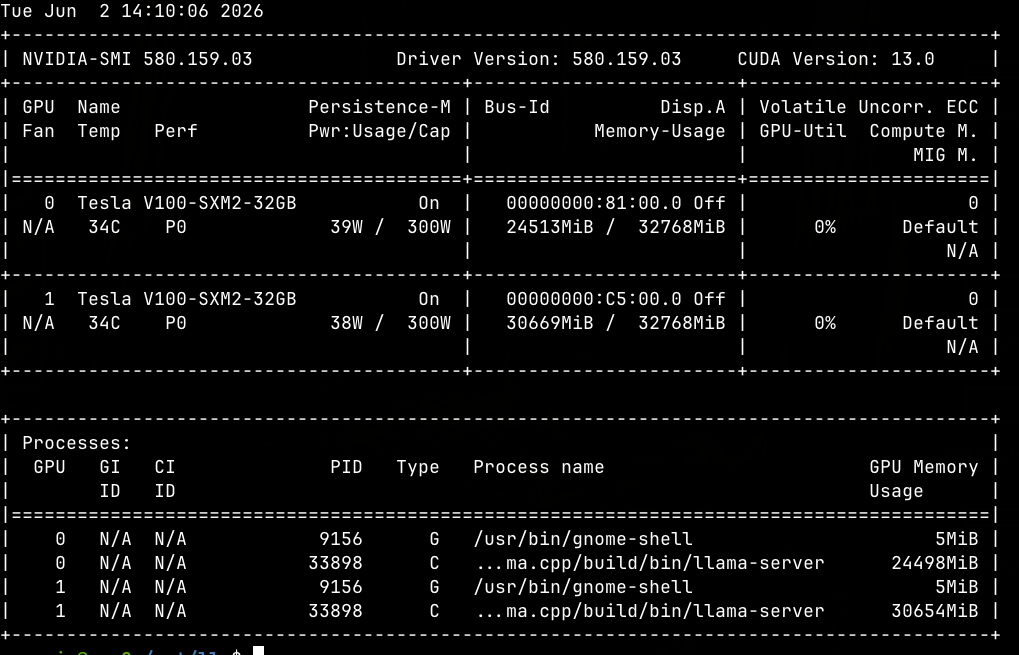
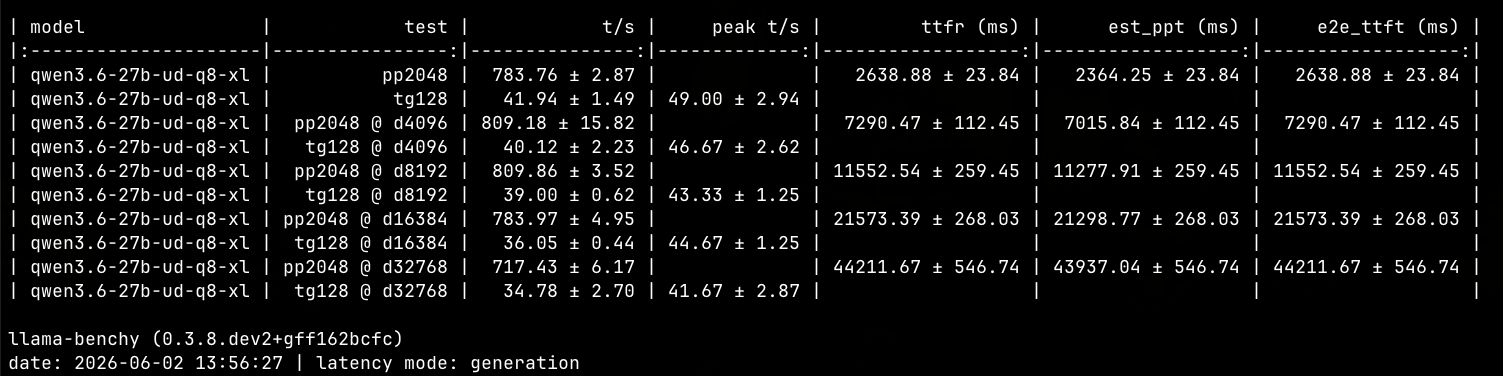
心得:
@kop-wang
connectX-7 頻寬是200Gb/s , 不過我測起來只有100 Gb/s, 不知道是不是它有兩個connectX-7 port, 但是我只插了一個. 不過看起來100 Gb/s + RDMA, vllm的張量運算也跑的還可以.
@Tony-Wang
ltx2.3大概是這樣:
(DGX Spark, 1280×720)
| steps | seconds | frames | 冷啟動耗時 |
|---|---|---|---|
| 12 | 4 | 97 | ~290 秒 |
| 24 | 4 | 97 | ~480 秒 |
使用這些模型:
models/checkpoints/ltx-2.3-22b-distilled-1.1.safetensorsmodels/text_encoders/gemma_3_12B_it_fp4_mixed.safetensorsmodels/latent_upscale_models/ltx-2.3-spatial-upscaler-x2-1.1.safetensorsFlux.2 1280x720、20 steps:
NVIDIA DGX spark 不是這邊的主力部署, 不過這裡有一些數據分享給想知道或是有類似需求的朋友.
我的LLM的用途主要是工作上(驅動/韌體 開發/debug), 基本上需要模型跑在全精度或至少Q8量化以上. 我試過FP8相較BF16已經略差, Q4實際使用上是無法達到我的需求.
在這個前提下, 我需要的是更多的vram, 能夠跑Q8以上的模型, 並且至少需要256K context, 才能比較舒適的使用. DGX spark雖然不快, 但是如果我想跑minimax, deepseek, mimo之類的模型, 選擇似乎也不多. 如果有超大模型, 超長上下文, 多併發的需求, 同時又不能使用雲端模型的情況下, DGX spark是可以考慮的選擇之一.
現在我手上有4台DGX spark, 因為QSFP switch還沒到手, 所以只能先倆倆對接, 四台還沒辦法接在一起. DGX spark自帶兩個connectX-7 QSFP介面, 把多台接在一起的時候,透過RDMA 和張量並行,集群可實現部分加速, 越多台速度越快,這應該比mac的exo快, 我沒有多台mac, 所以不知道實際狀況如何. 目前我是跑Qwen/Qwen3.6-27B-FP8(模型權重30.9G)跟deepseek-ai/DeepSeek-V4-Flash全精度模型(模型權重160G), 下面速度供大家參考:
Qwen/Qwen3.6-27B-FP8單spark:

Qwen/Qwen3.6-27B-FP8雙spark:
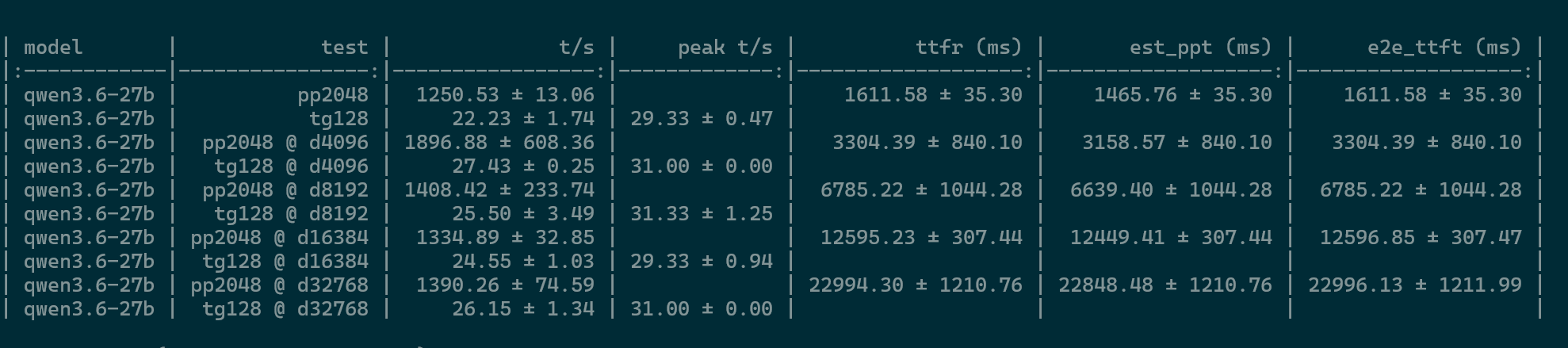
deepseek-ai/DeepSeek-V4-Flash, 雙spark:

速度不是非常快, 不過因為平常我也不跟它們聊天, 都是用opencode或pi把工作丟給它們就去做別的事了, 所以也還好. 基本上有個20我就覺得可以用了, 畢竟這是8 bit的模型, 也不能強求什麼了.
這兩個模型依我的使用比較起來, 感覺智力上相當接近, qwen 3.6 27B在tool call上出錯比較少, 是真的能打. 雖然跟claude opus 4.7或GPT 5.5相較之下還是有差異, 不過也堪用了.
至於ComfyUI嘛.. 它就是一個沒有什麼跑不動, 卻也沒有什麼跑的快的狀態.
6/2更新, deepseek v4 flash spark論壇上有新的優化, 請gemini cli照做後性能有所提升.
論壇網頁:
https://forums.developer.nvidia.com/t/deepseek-v4-flash-official-fp8-running-across-2x-dgx-spark-tp-2-mtp-200k-ctx-recipe-numbers/370309/135
測試:

一台GX10跑qwen3.6 27B FP8, 開mtp大概有20 tok/s, 我的配置如下, 抄上面那個網站的:
spark3:~/llm/qwen26-27b$ cat qwen3.6-27b-fp8.yaml
recipe_version: "1"
name: Qwen3.6-27B-FP8-MTP
description: vLLM serving Qwen3.6-27B-FP8 with MTP=3 on a single GB10 (Spark Arena recipe)
model: Qwen/Qwen3.6-27B-FP8
container: vllm/vllm-openai:v0.20.0-aarch64-cu130-ubuntu2404-ws
solo_only: true
defaults:
port: 8004
host: 0.0.0.0
tensor_parallel: 1
gpu_memory_utilization: 0.8069
max_model_len: 262144
max_num_batched_tokens: 32768
max_num_seqs: 8
env:
VLLM_MARLIN_USE_ATOMIC_ADD: "1"
VLLM_USE_DEEP_GEMM: "0"
CUDA_MANAGED_FORCE_DEVICE_ALLOC: "1"
PYTORCH_CUDA_ALLOC_CONF: "expandable_segments:True"
OMP_NUM_THREADS: "4"
command: |
vllm serve Qwen/Qwen3.6-27B-FP8
--served-model-name Qwen/Qwen3.6-27B-FP8 qwen3.6-27b
--tensor-parallel-size {tensor_parallel}
--port {port} --host {host}
--max-model-len {max_model_len}
--max-num-seqs {max_num_seqs}
--max-num-batched-tokens {max_num_batched_tokens}
--gpu-memory-utilization {gpu_memory_utilization}
--kv-cache-dtype fp8
--enable-prefix-caching
--language-model-only
--async-scheduling
--max-cudagraph-capture-size 128
--reasoning-parser qwen3
--enable-auto-tool-choice
--tool-call-parser qwen3_coder
--speculative-config '{{"method":"mtp","num_speculative_tokens":3}}'
--trust-remote-code
如果有兩台會再快一些